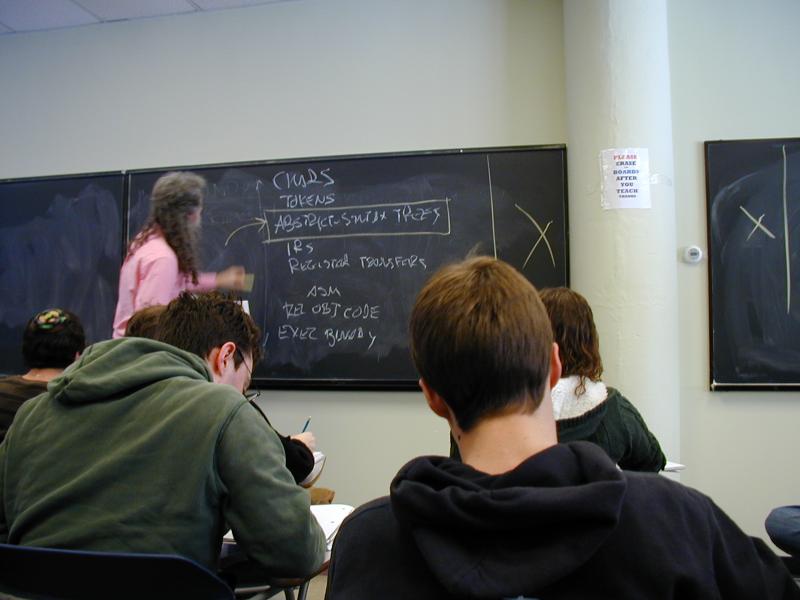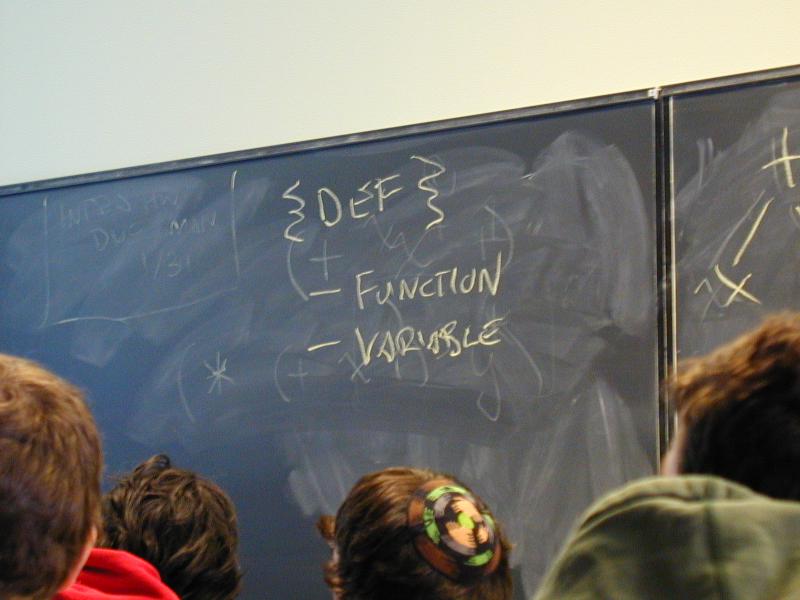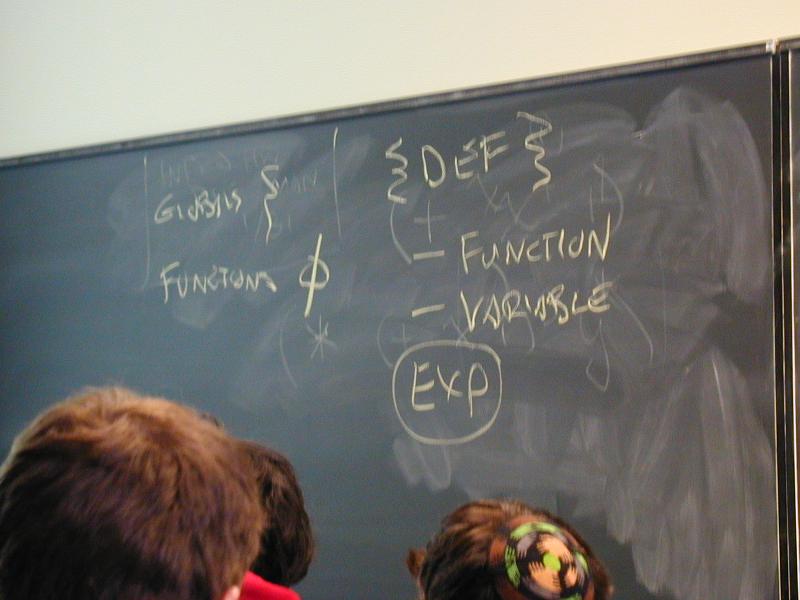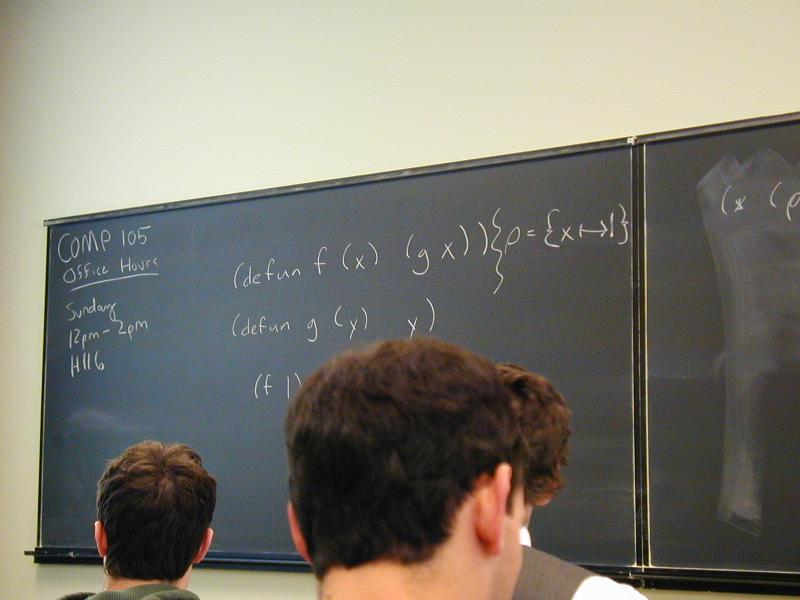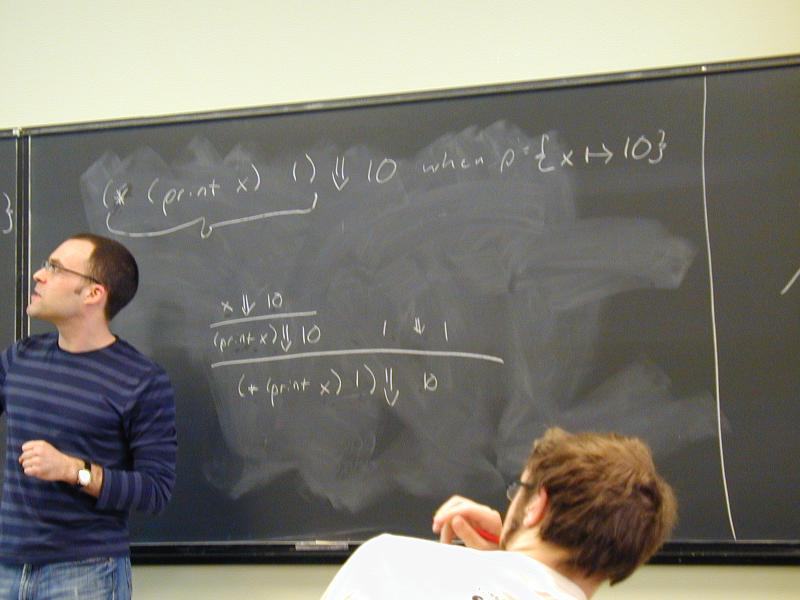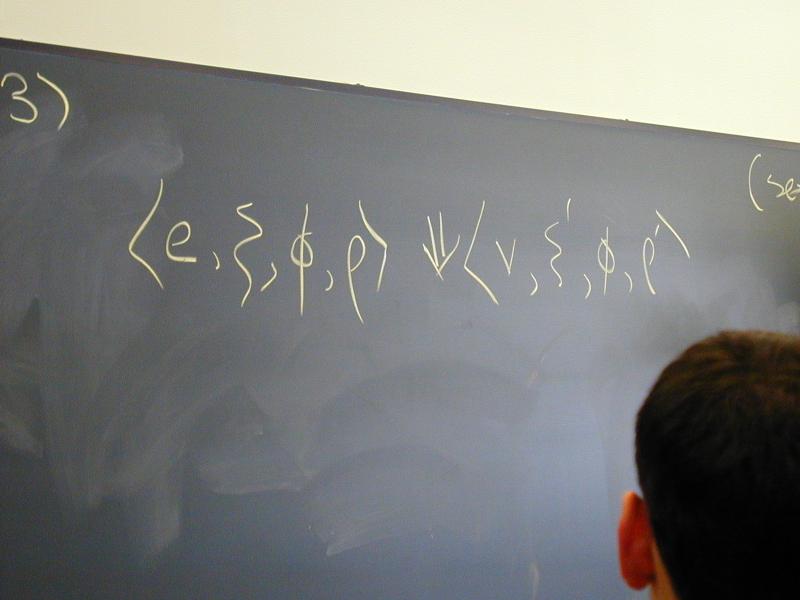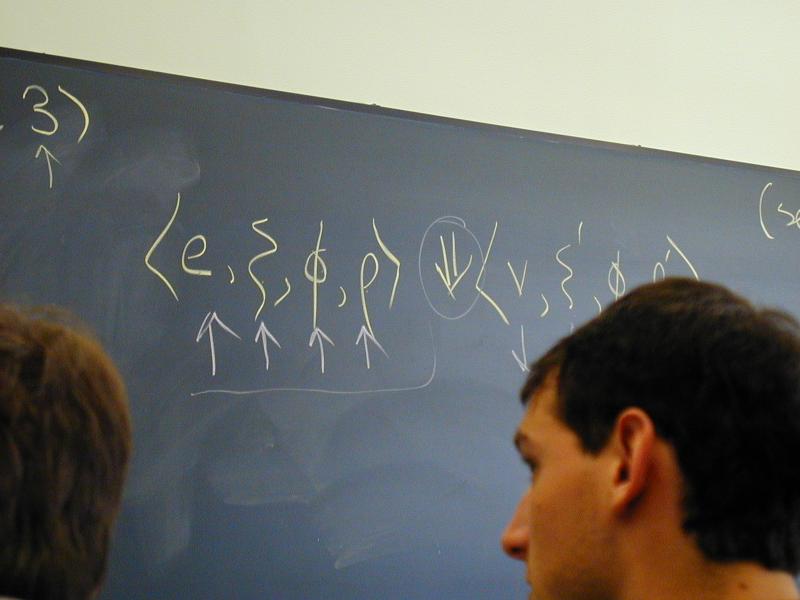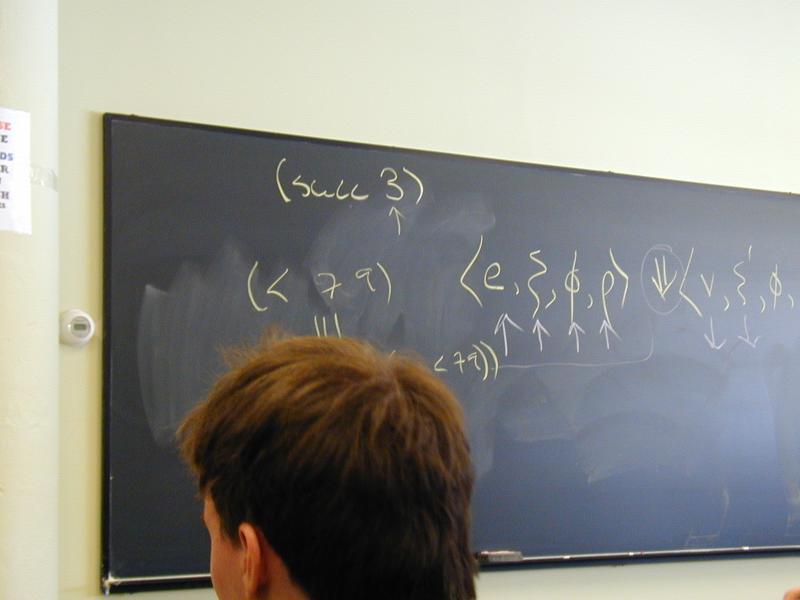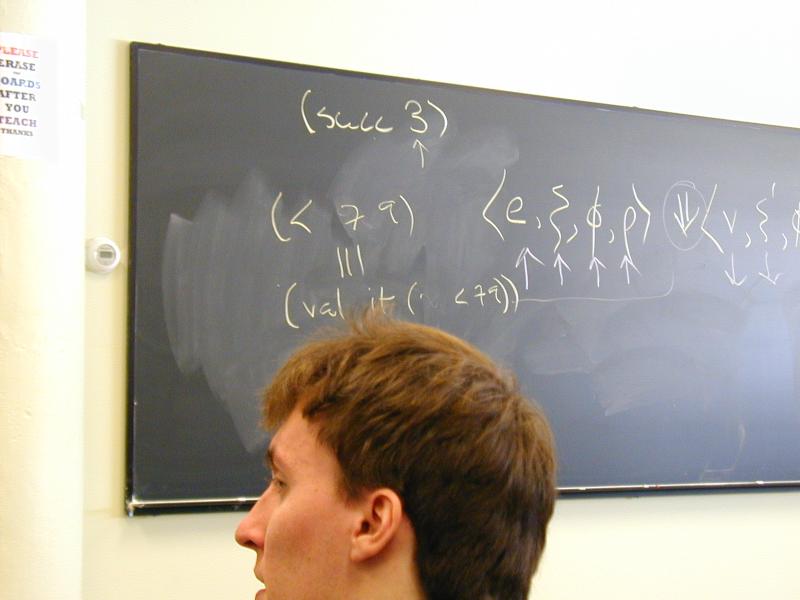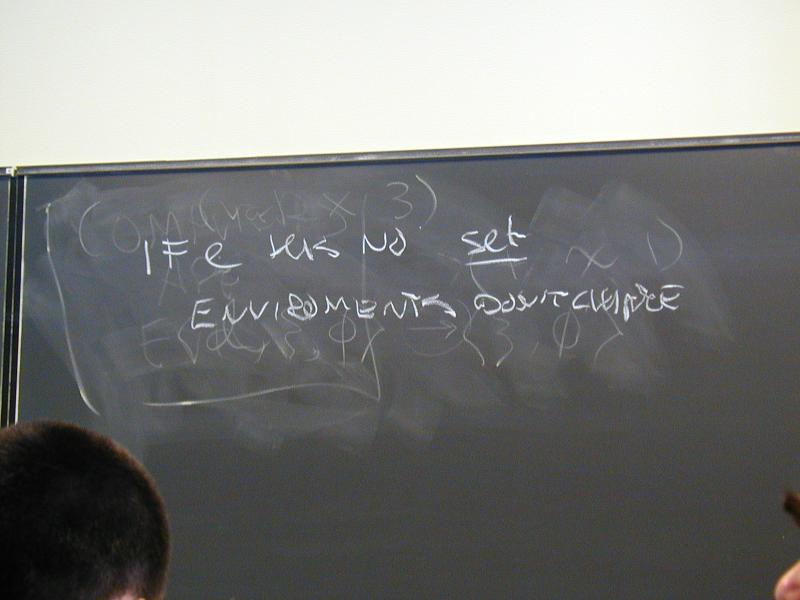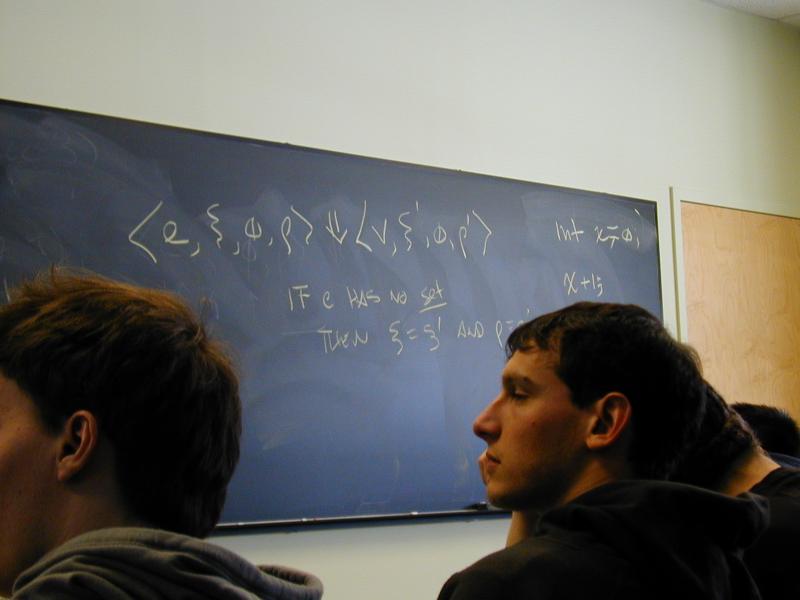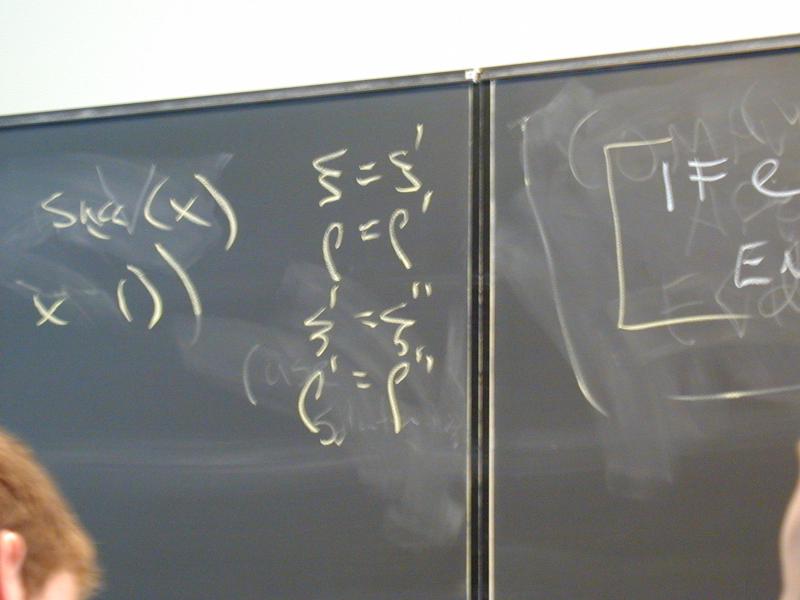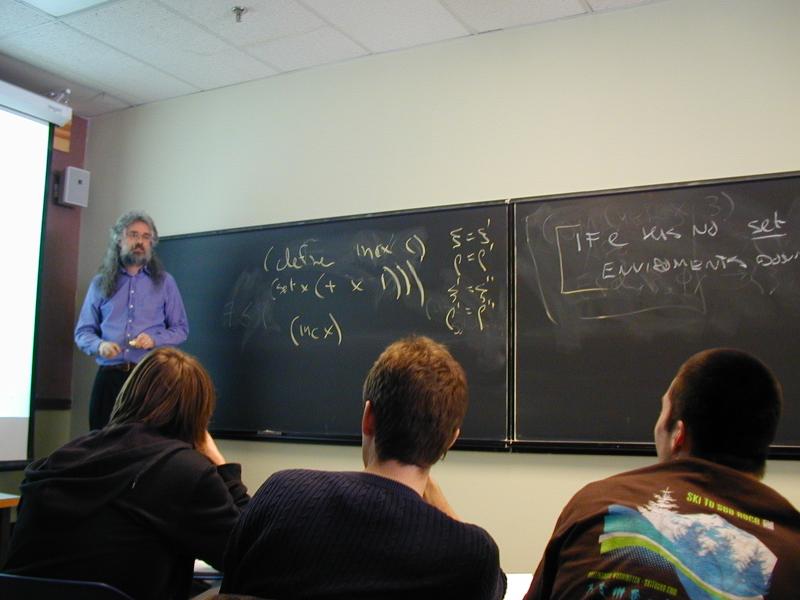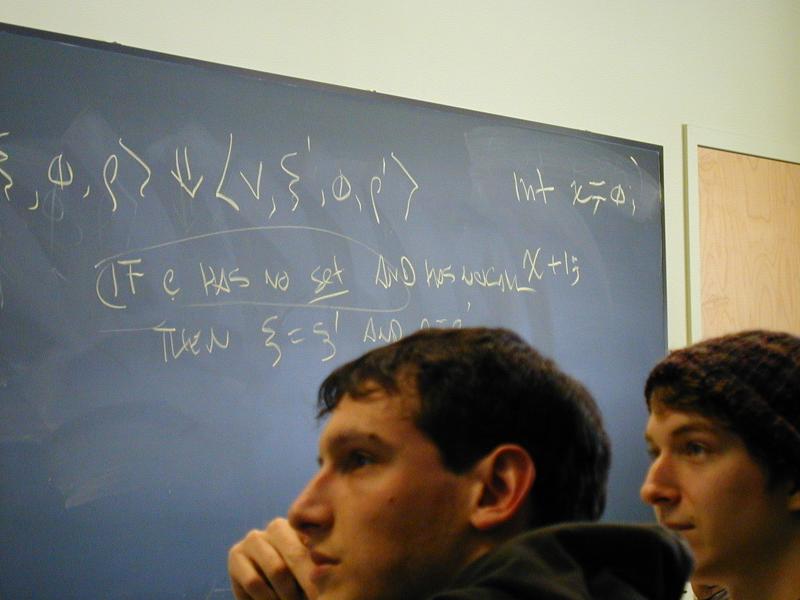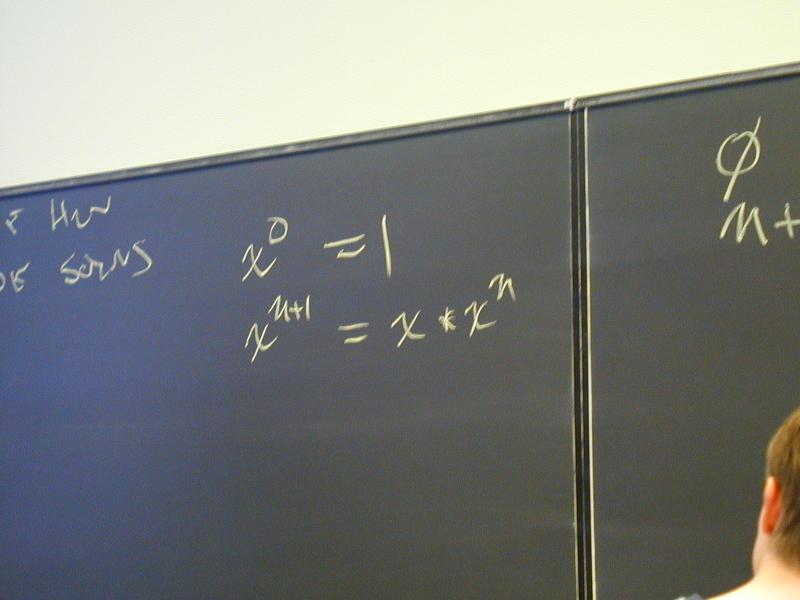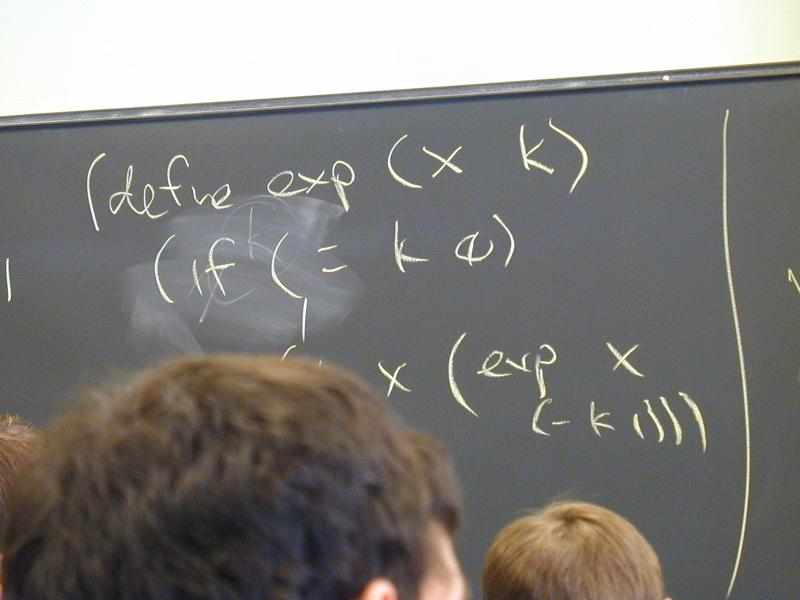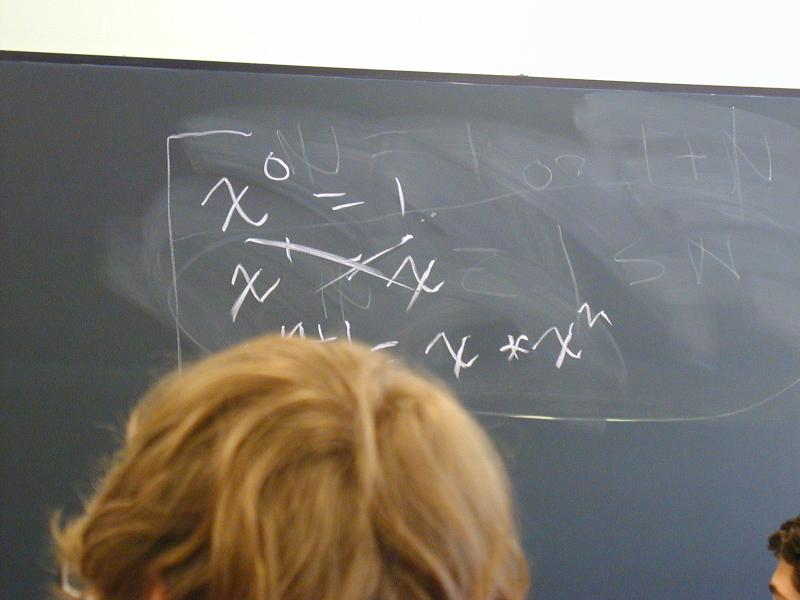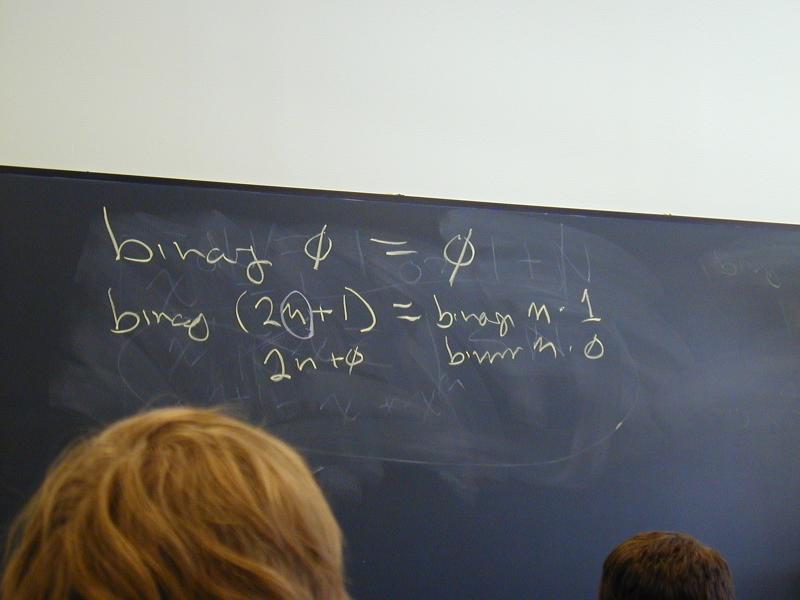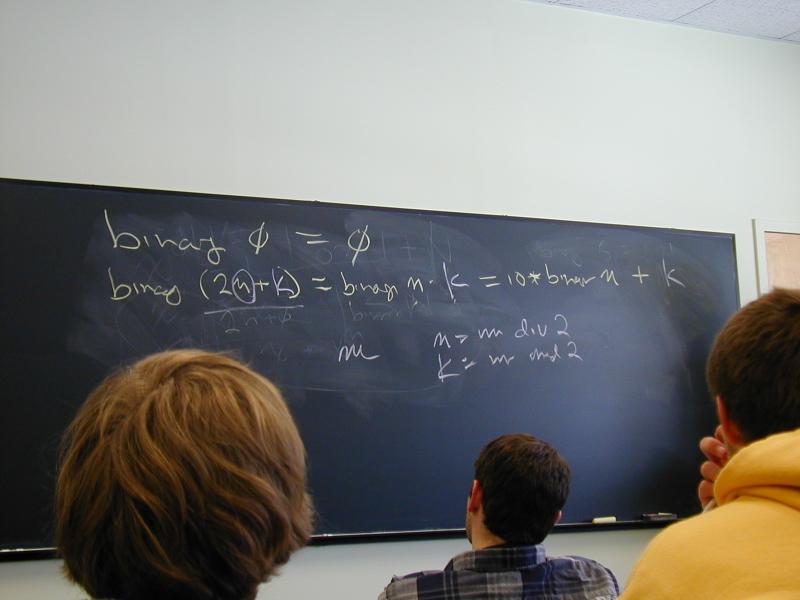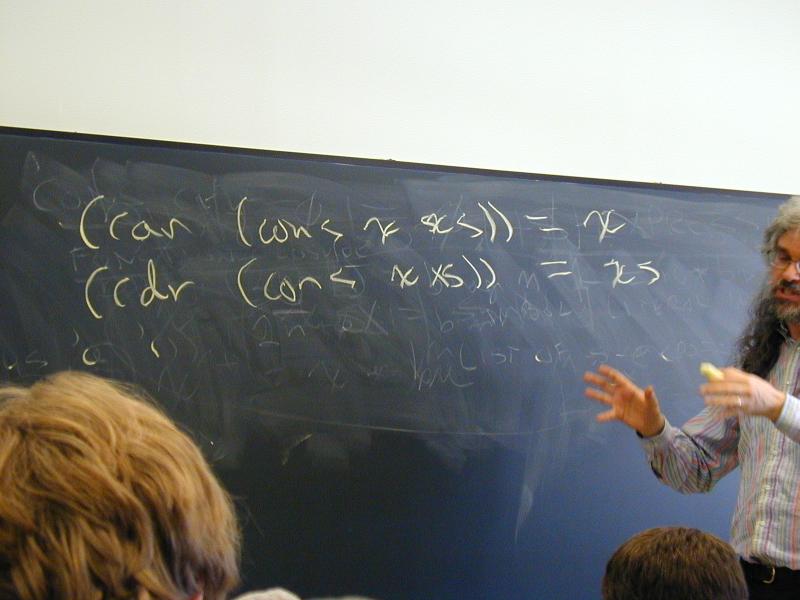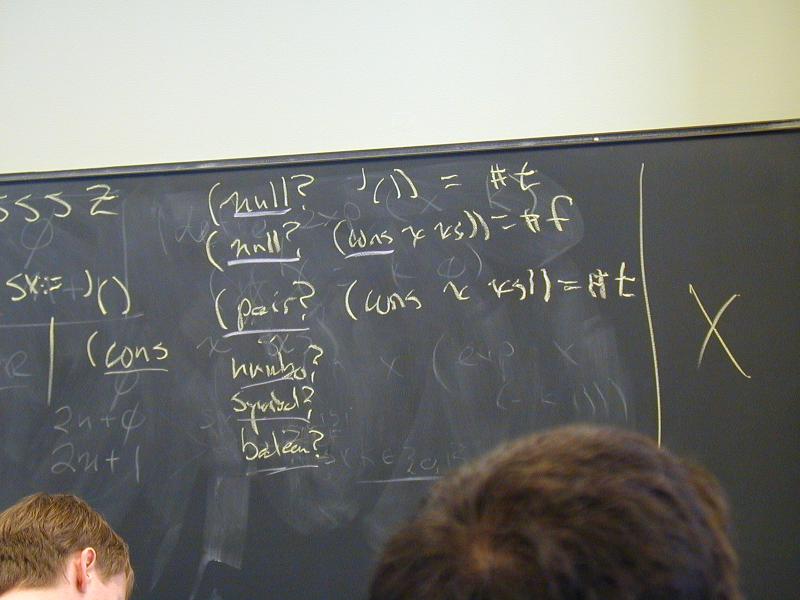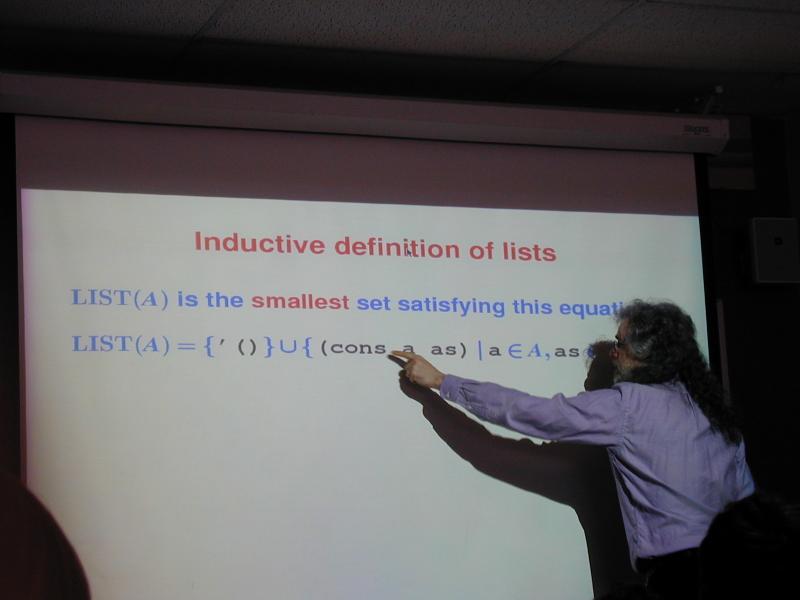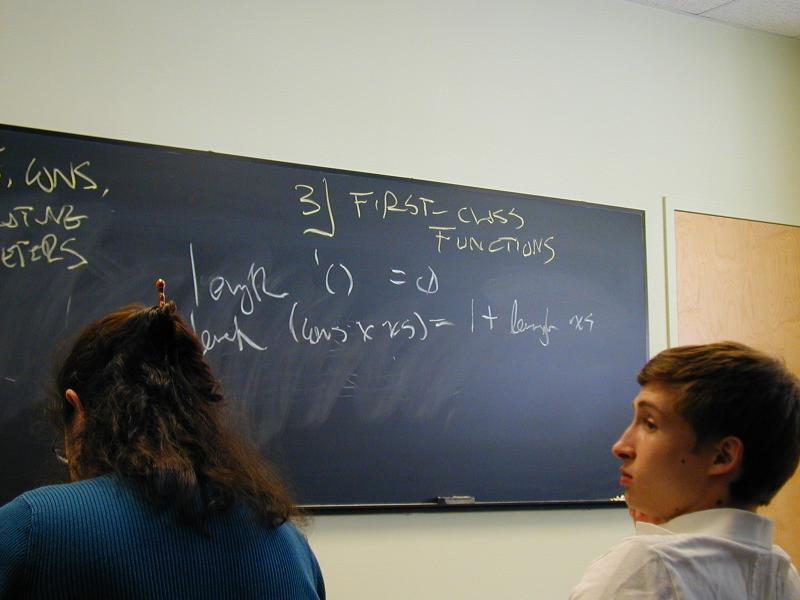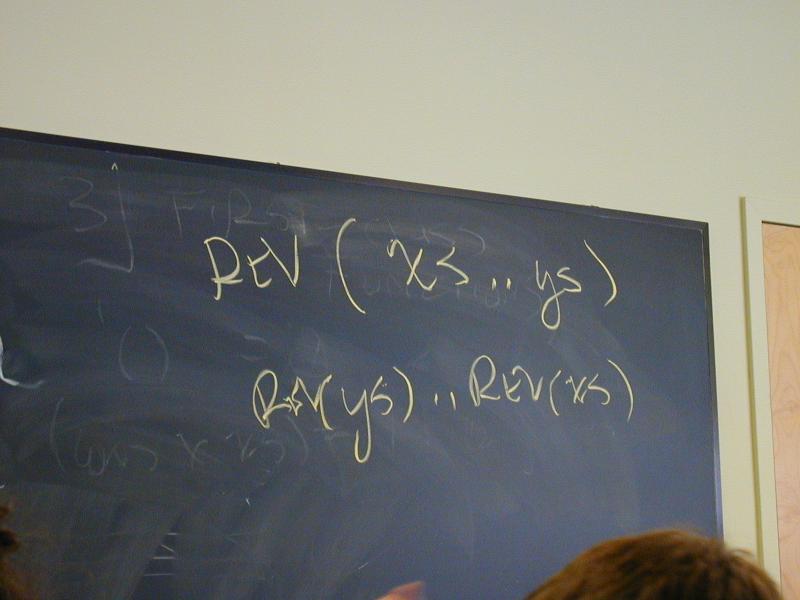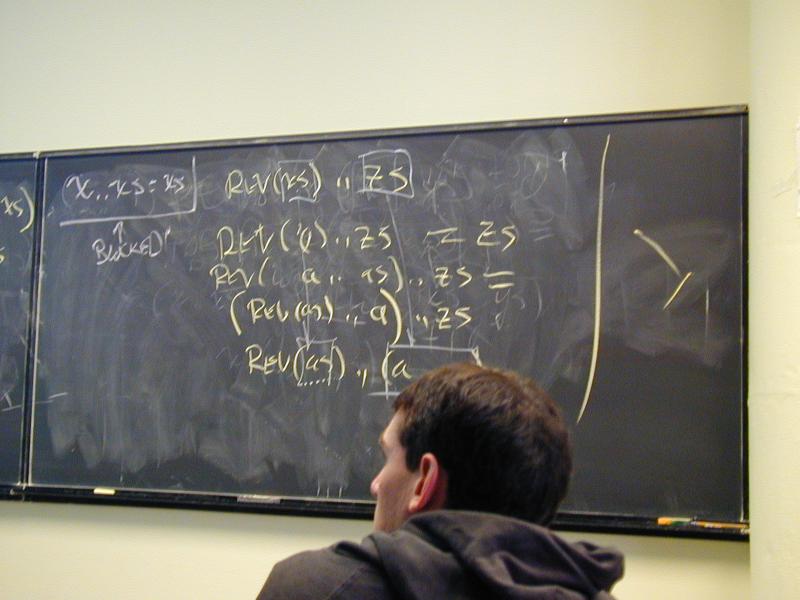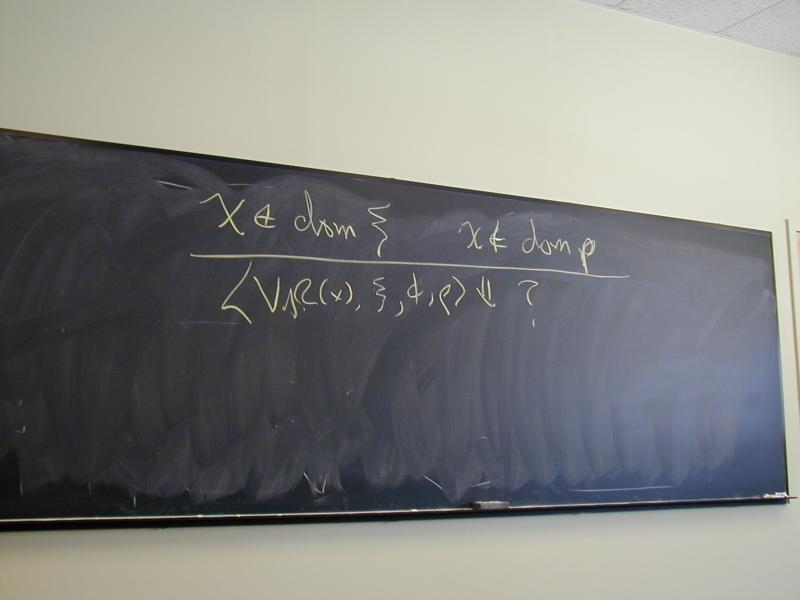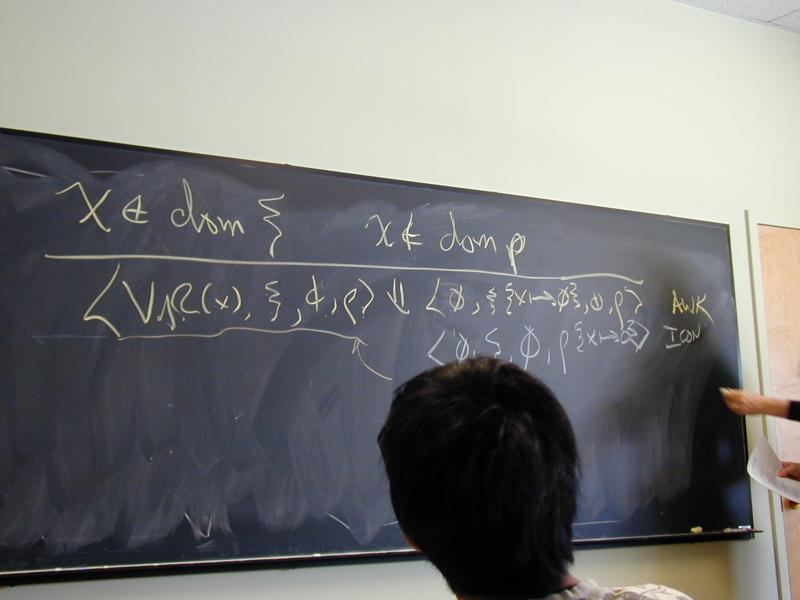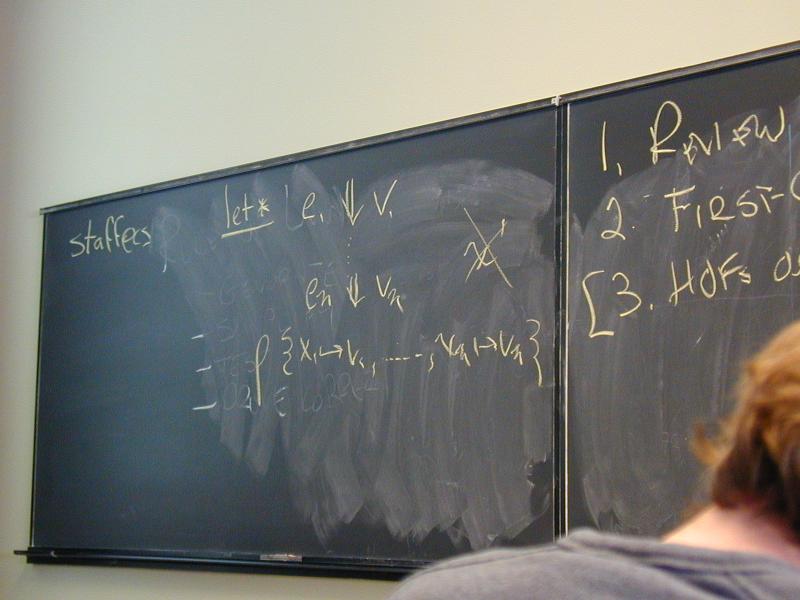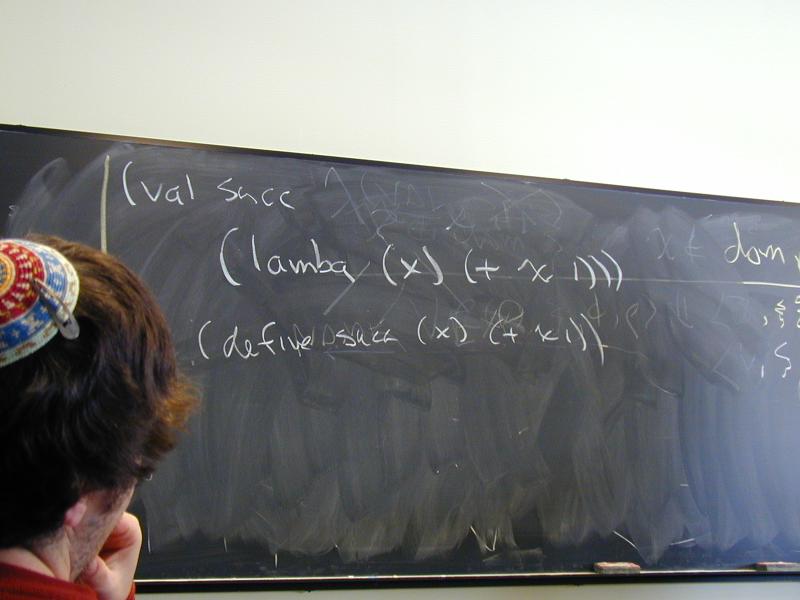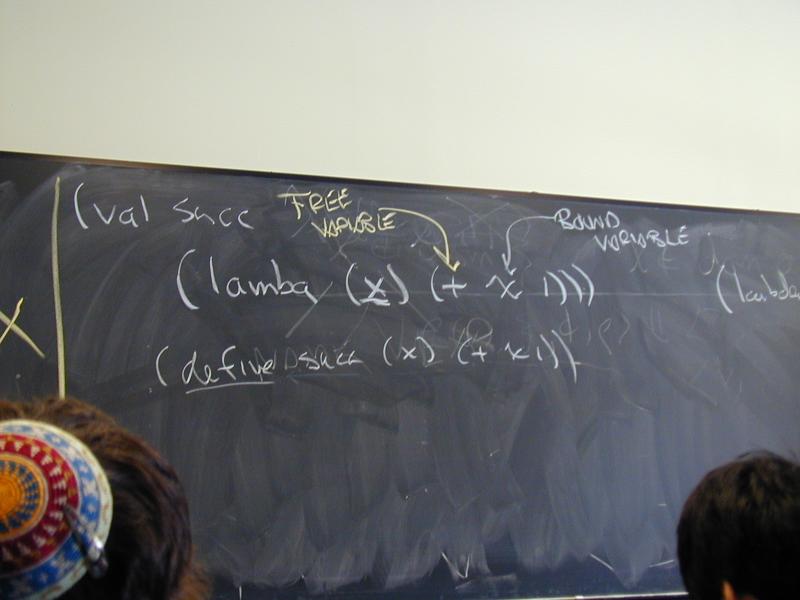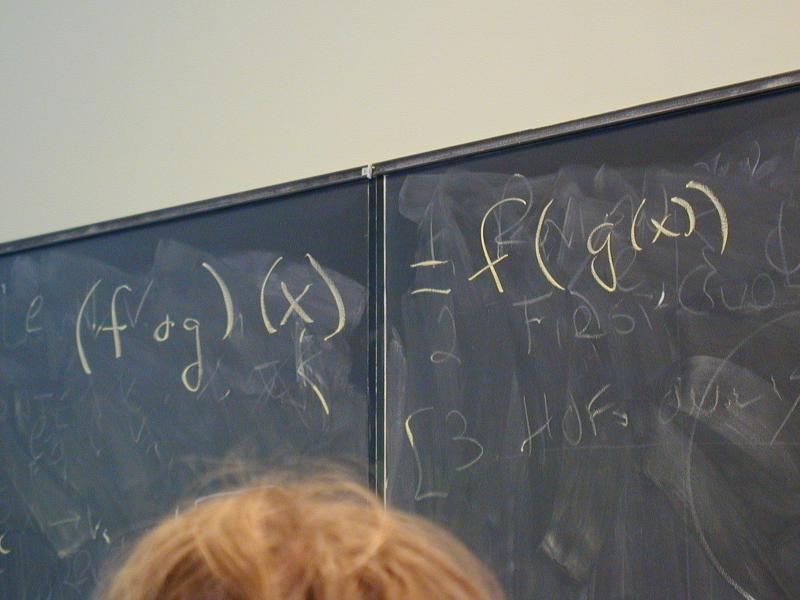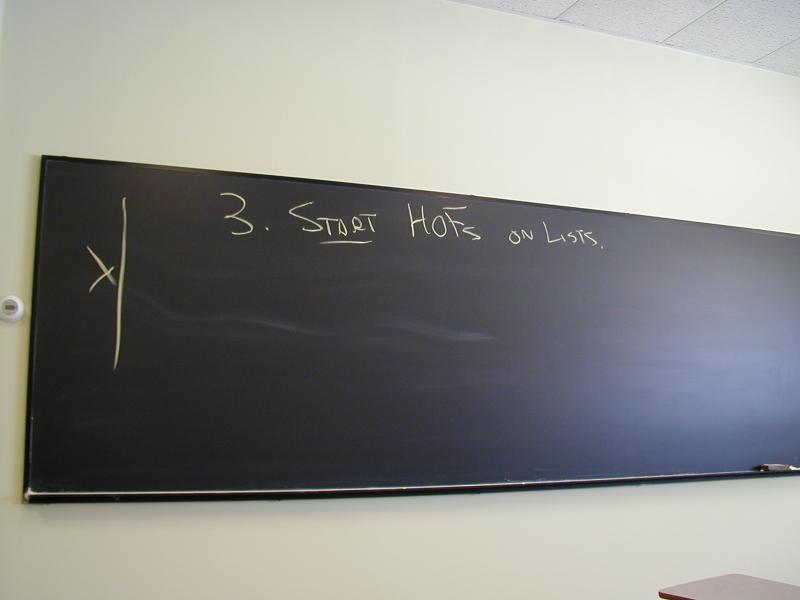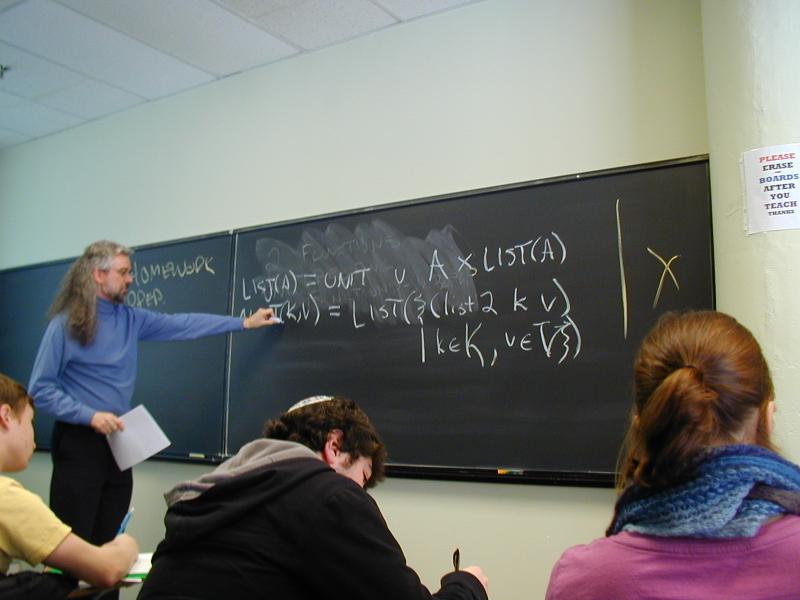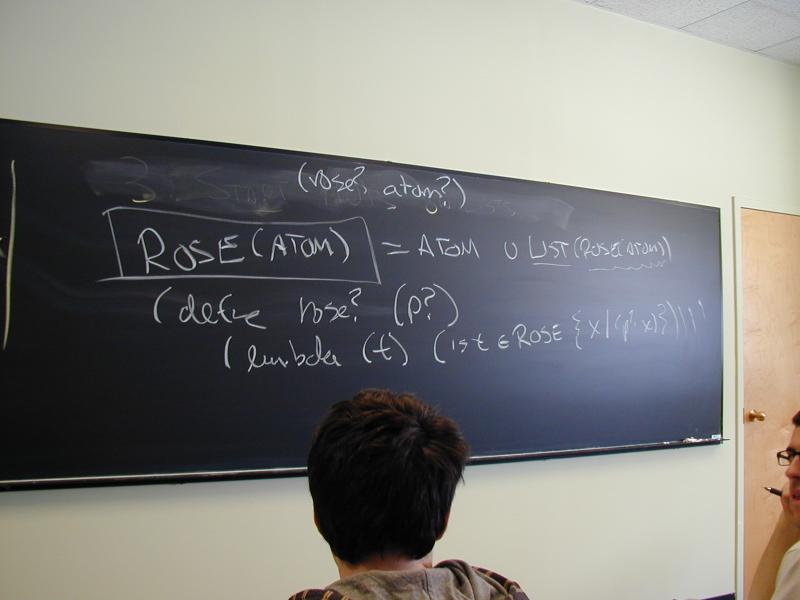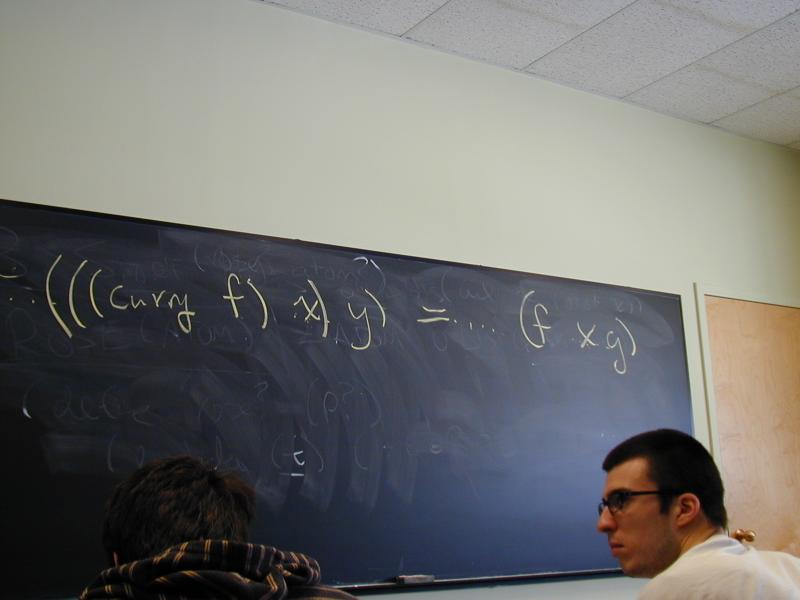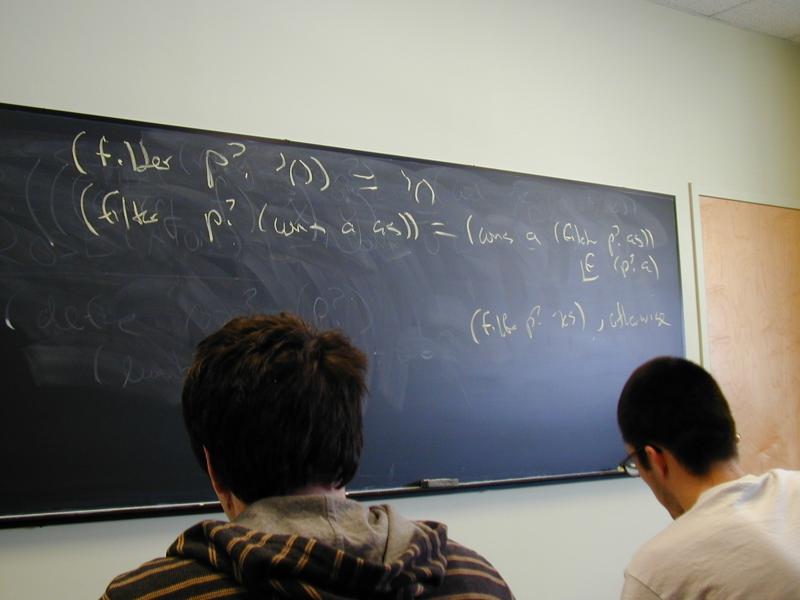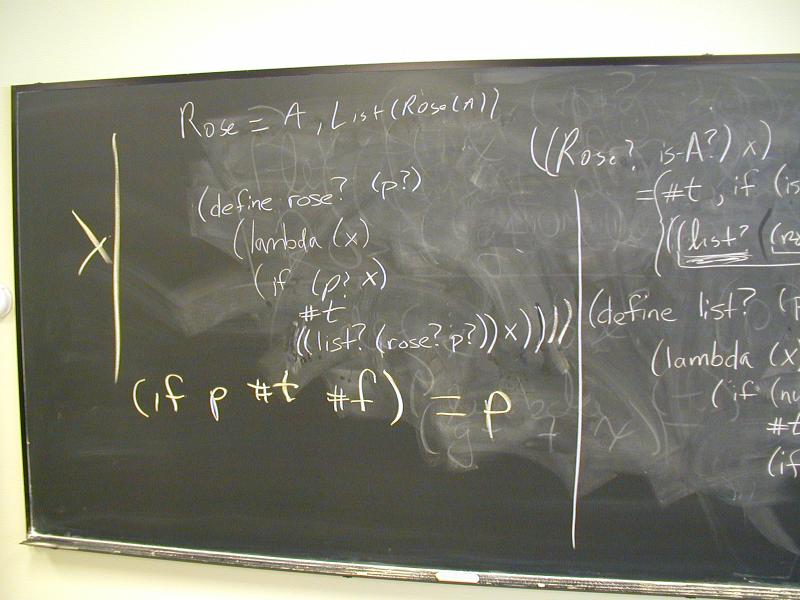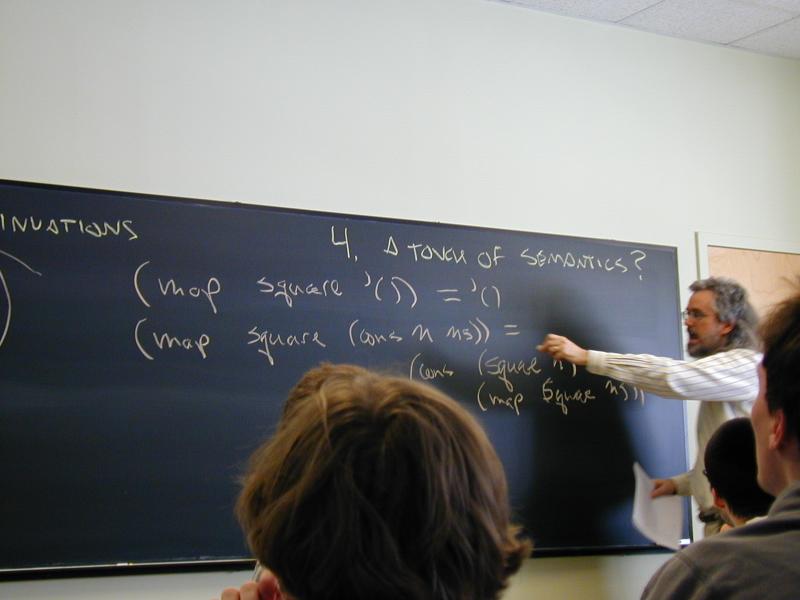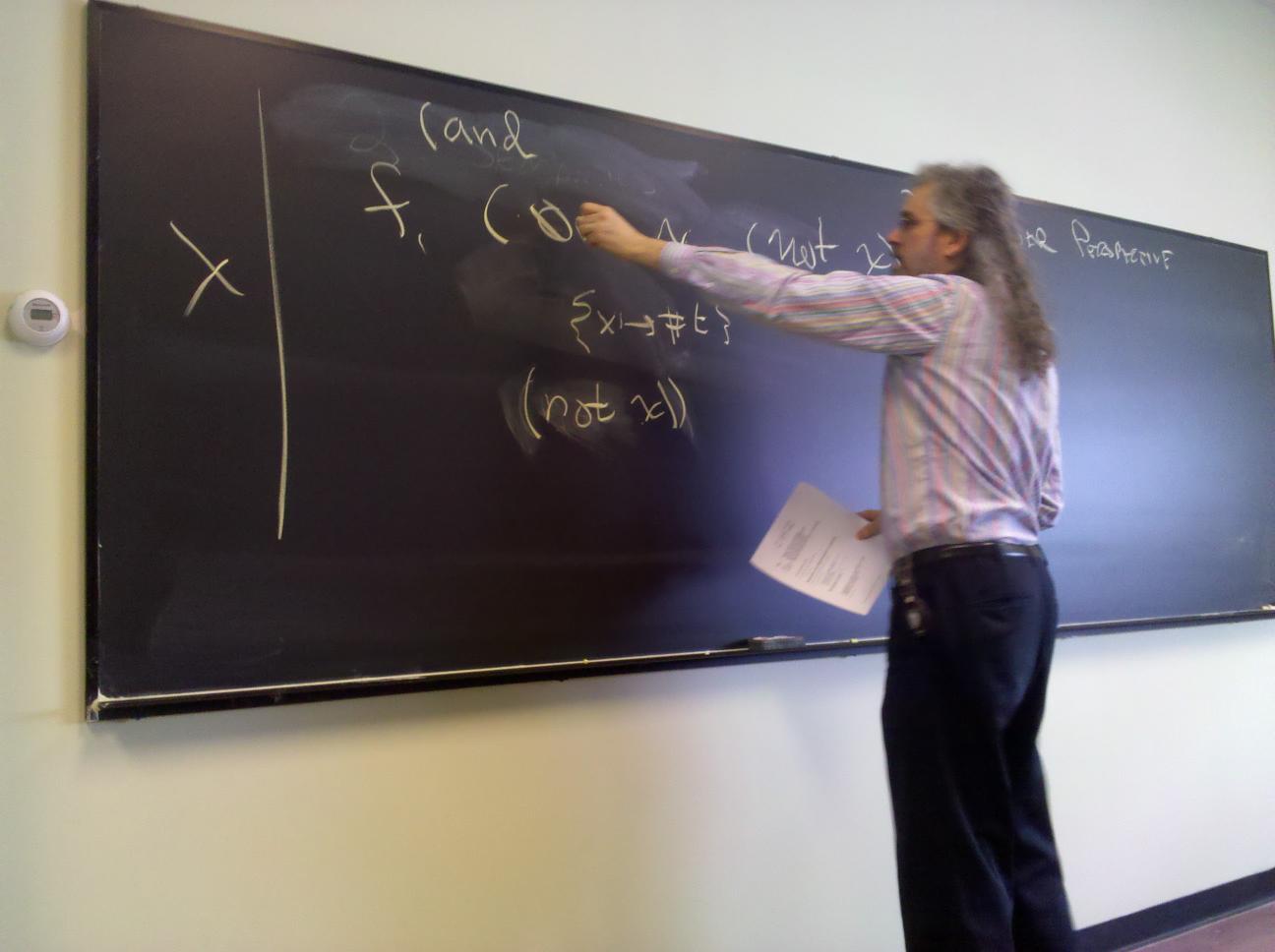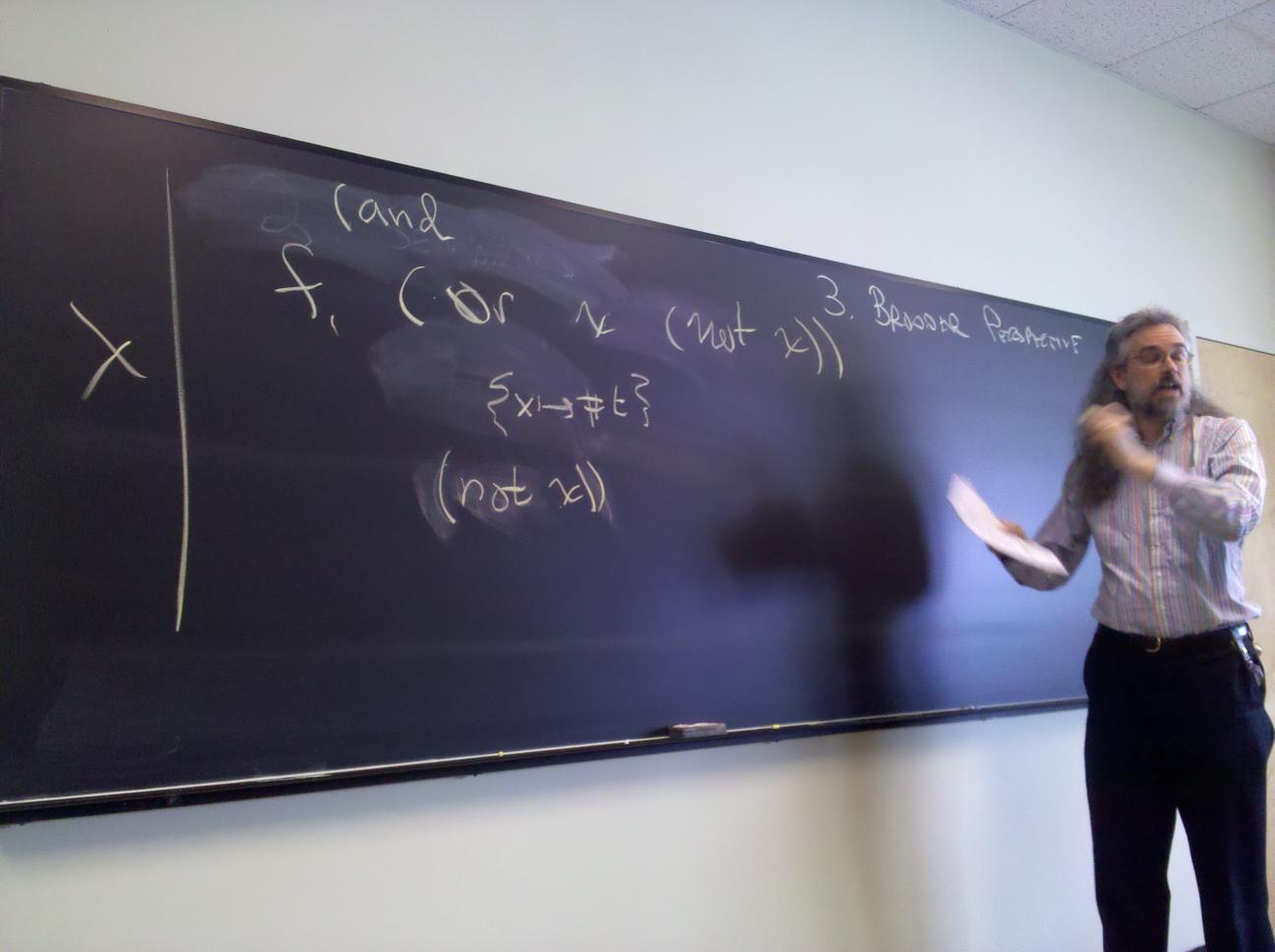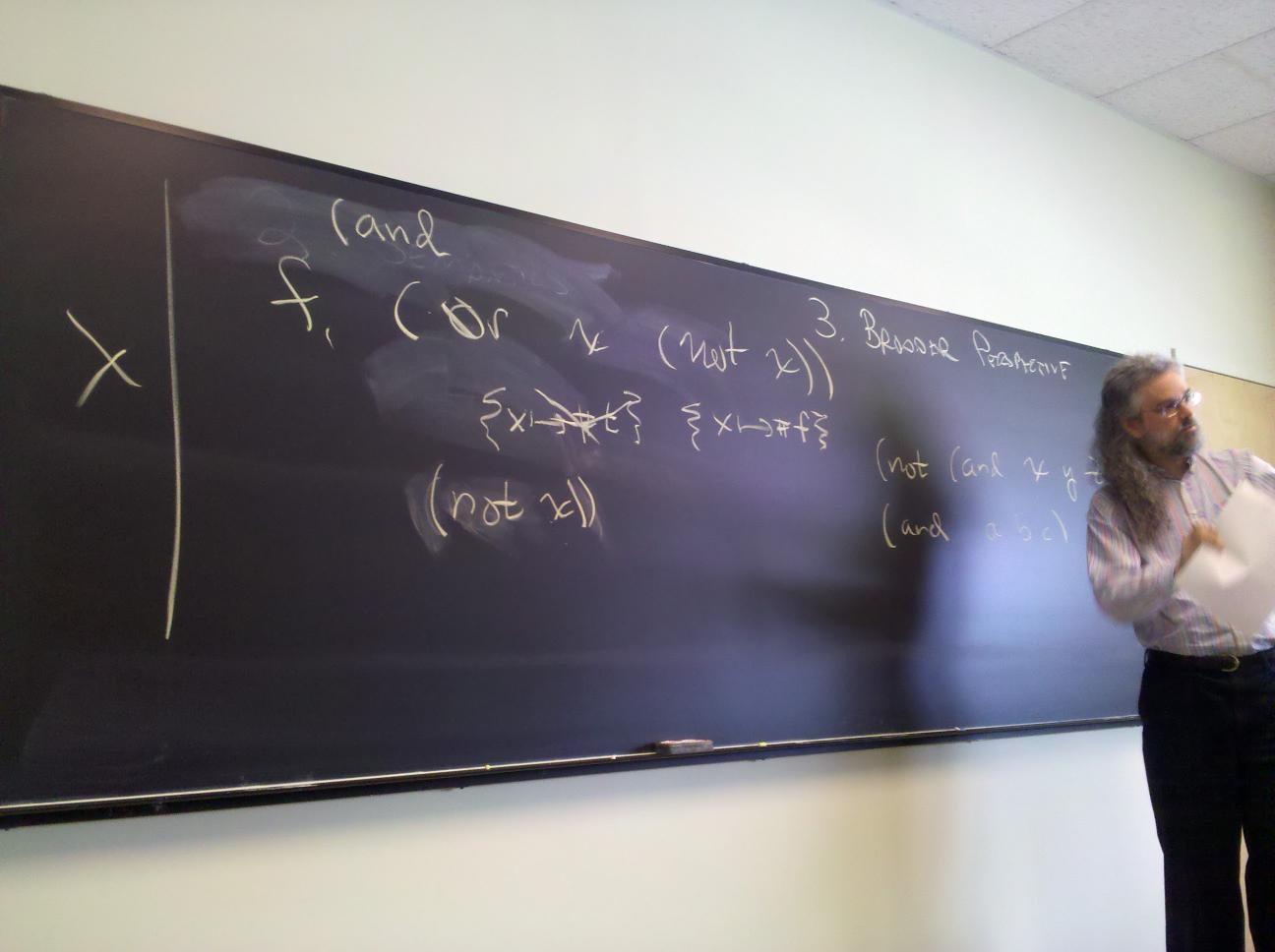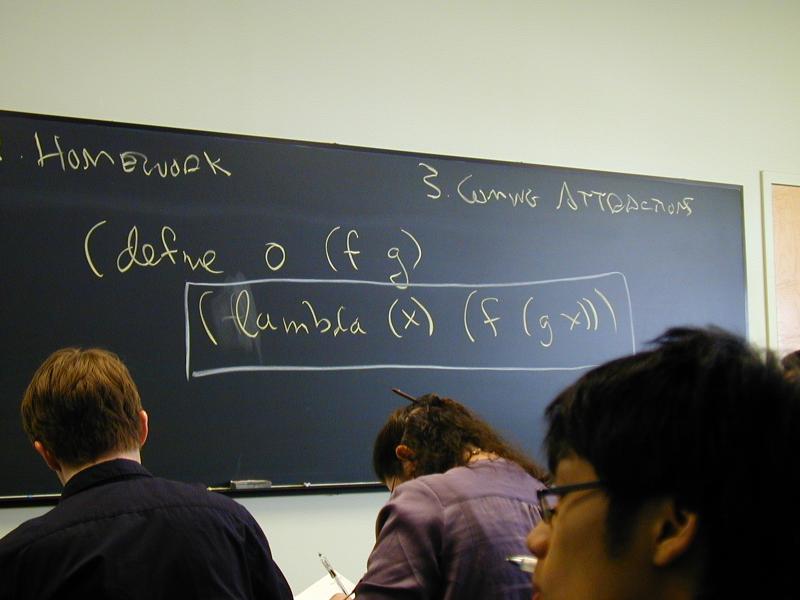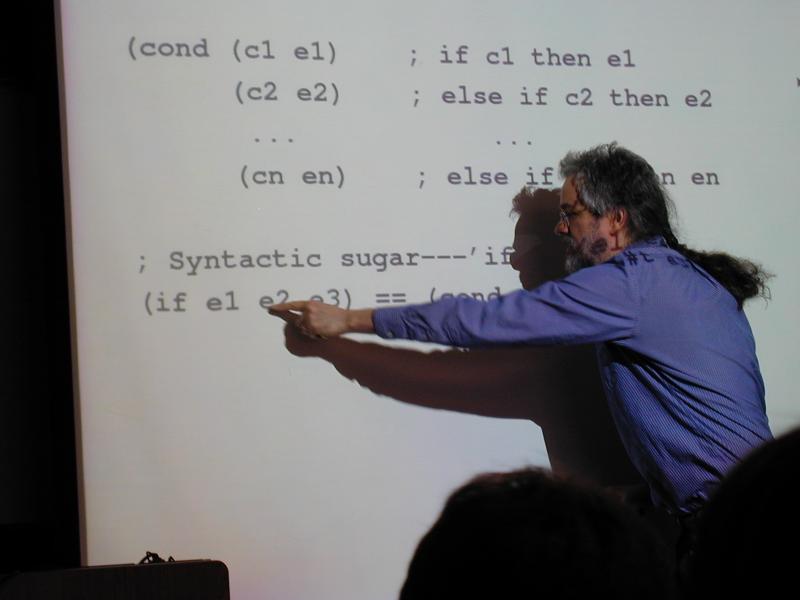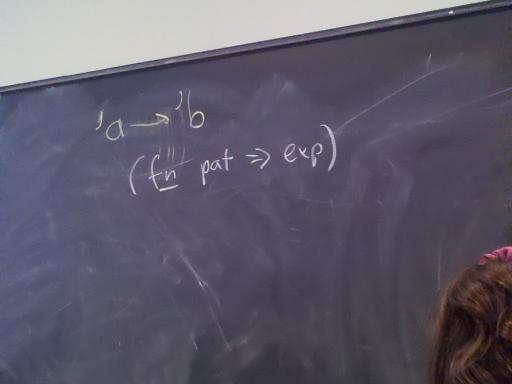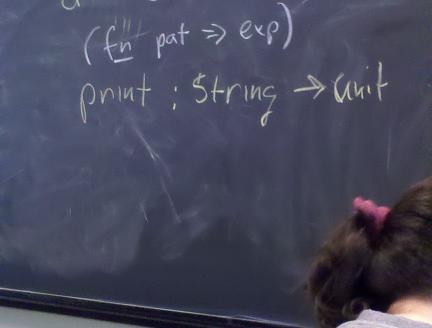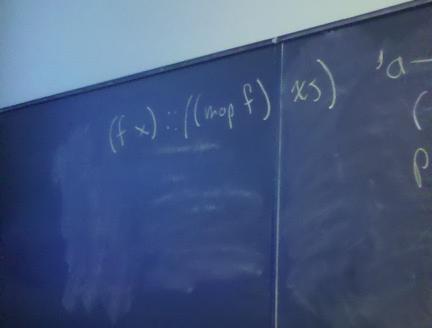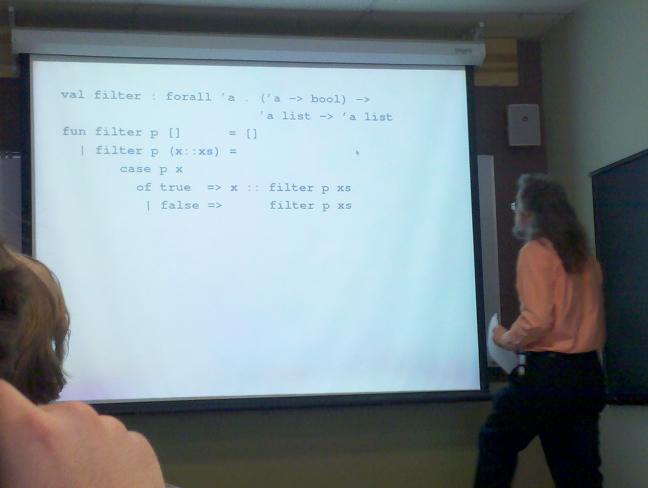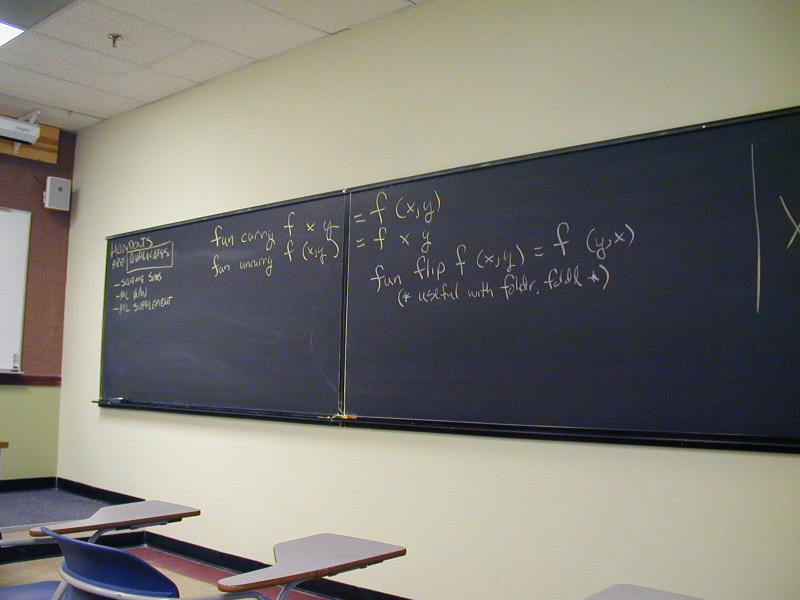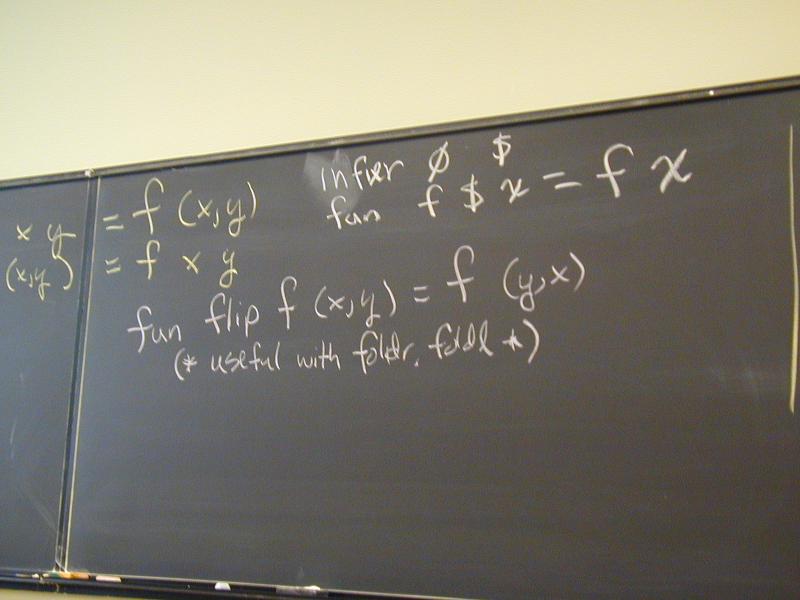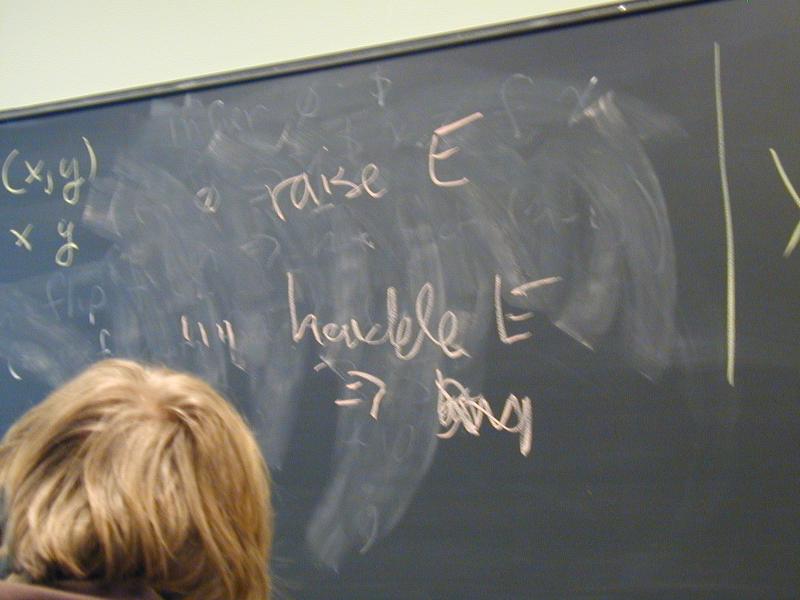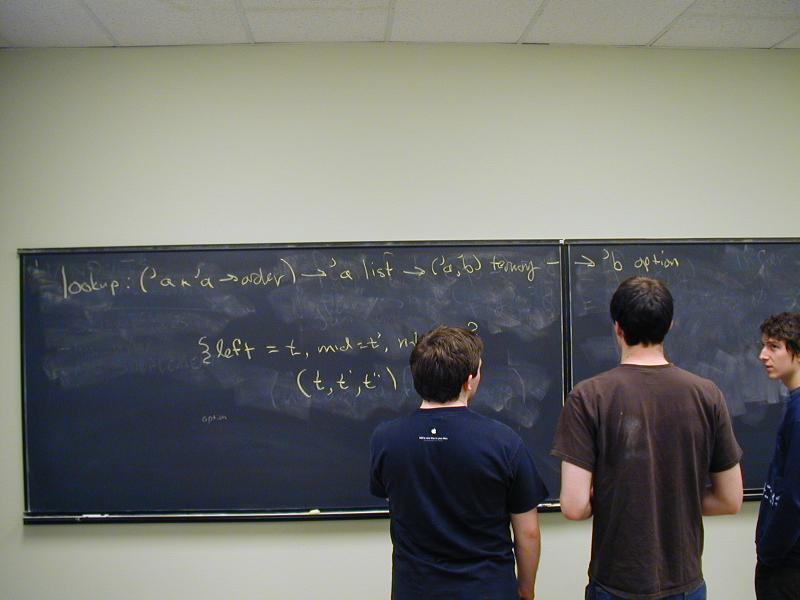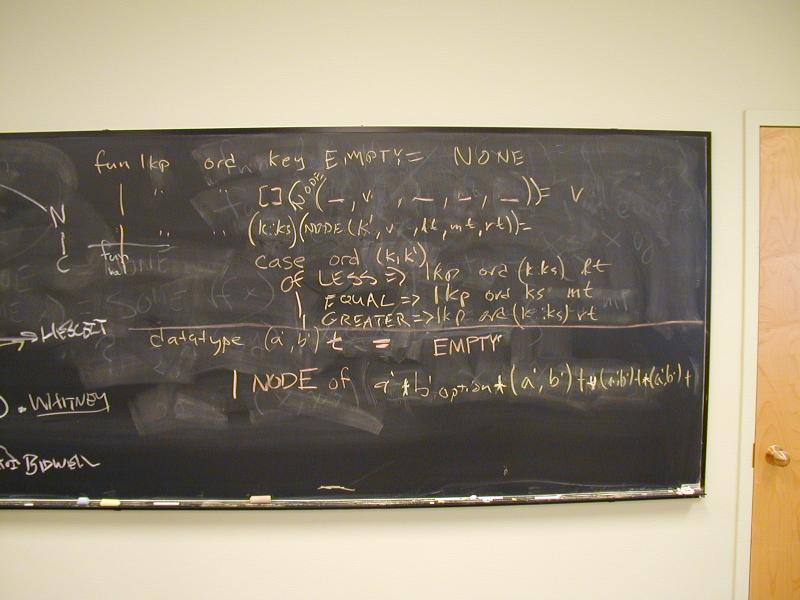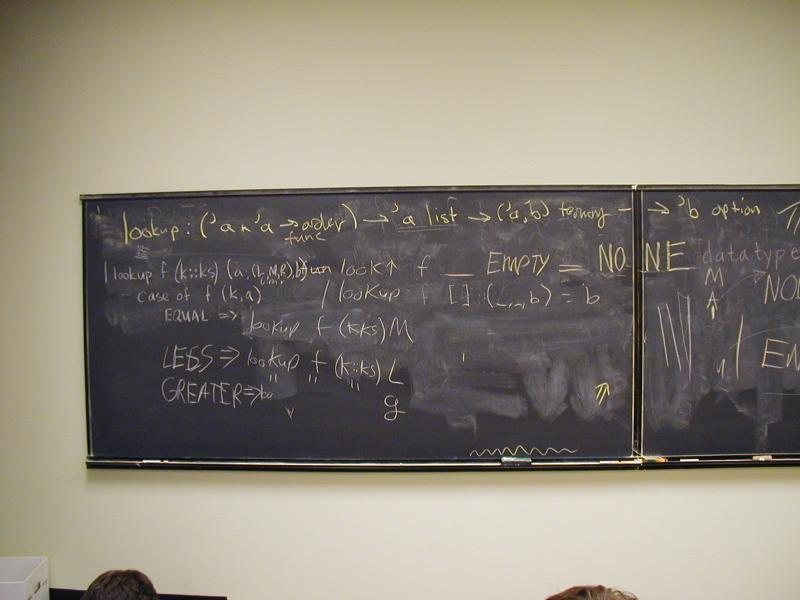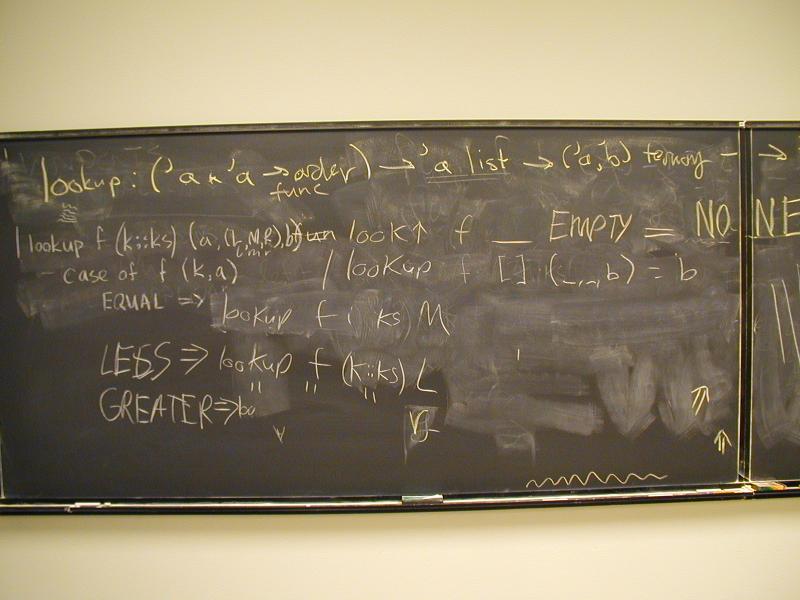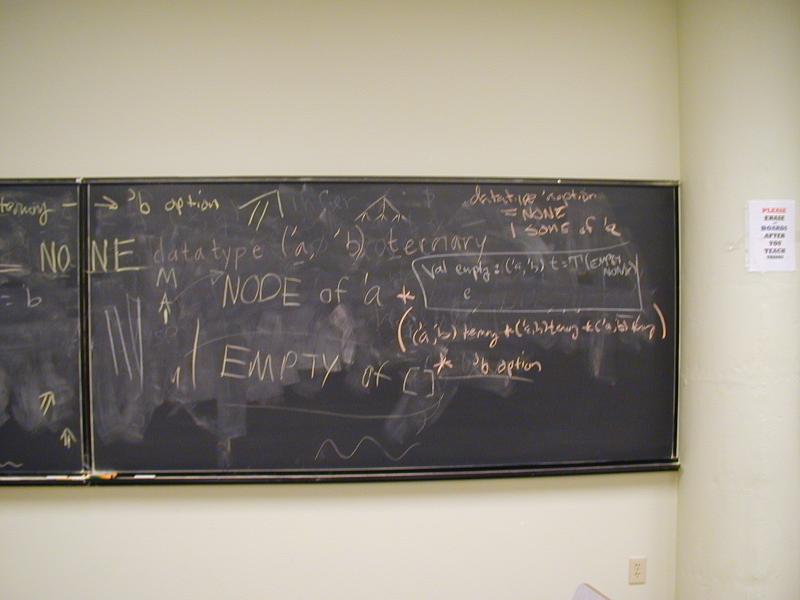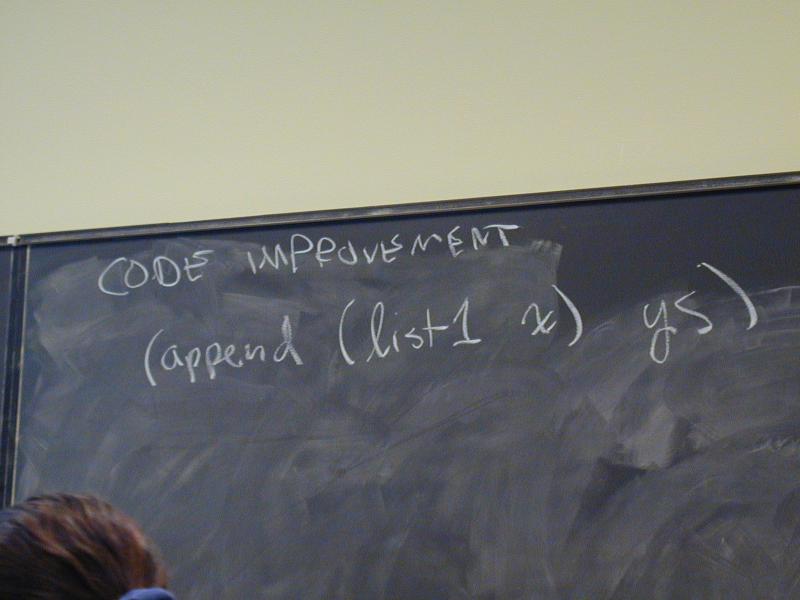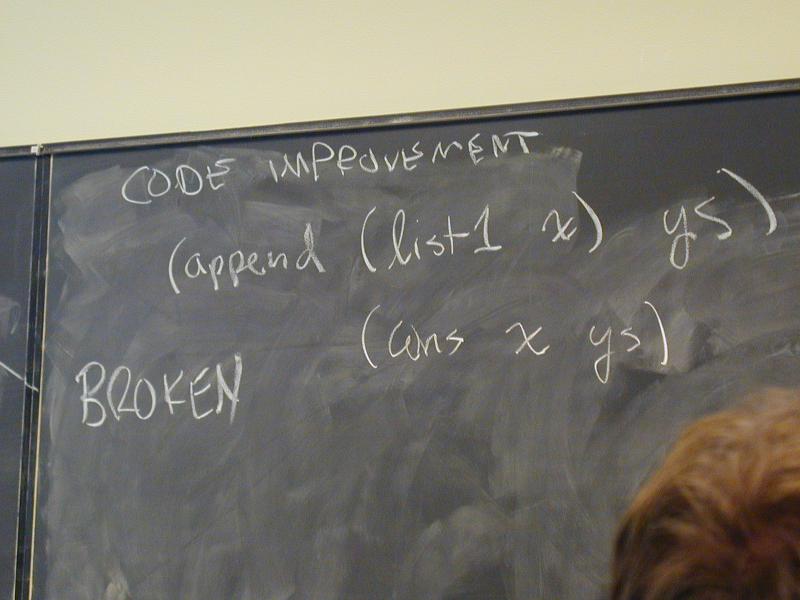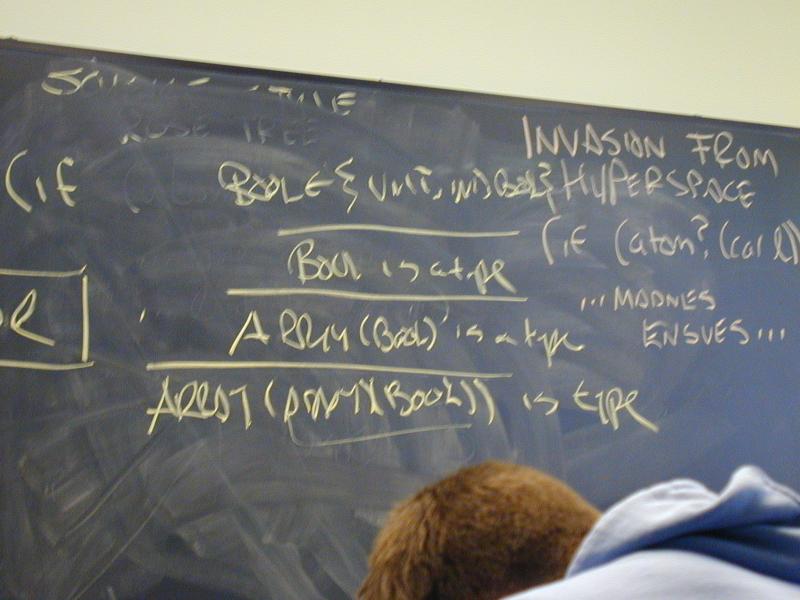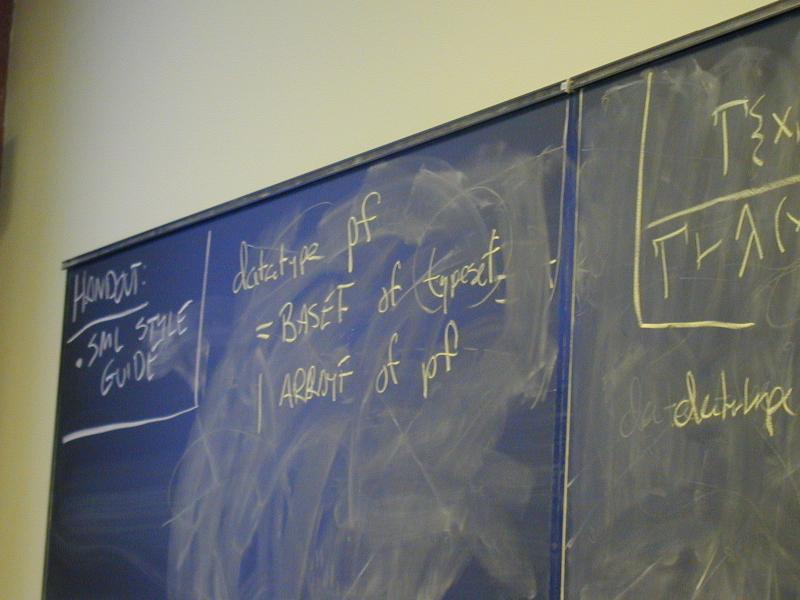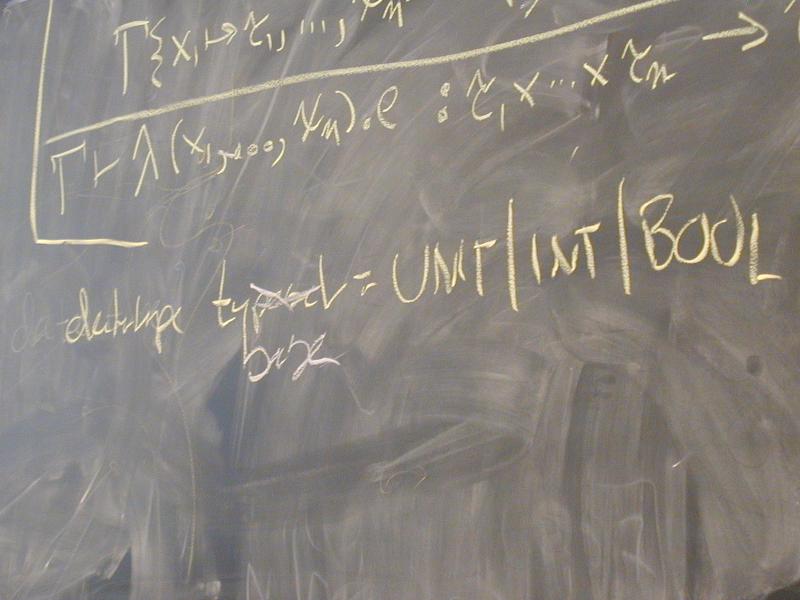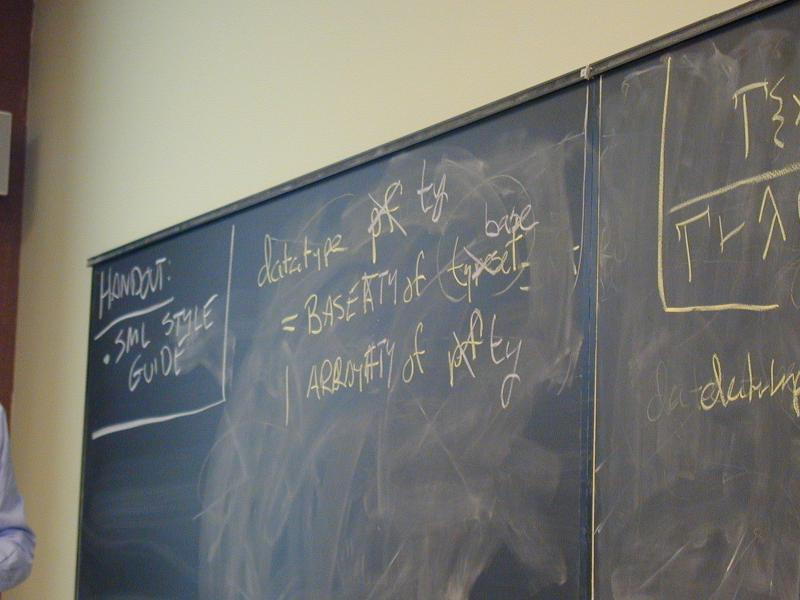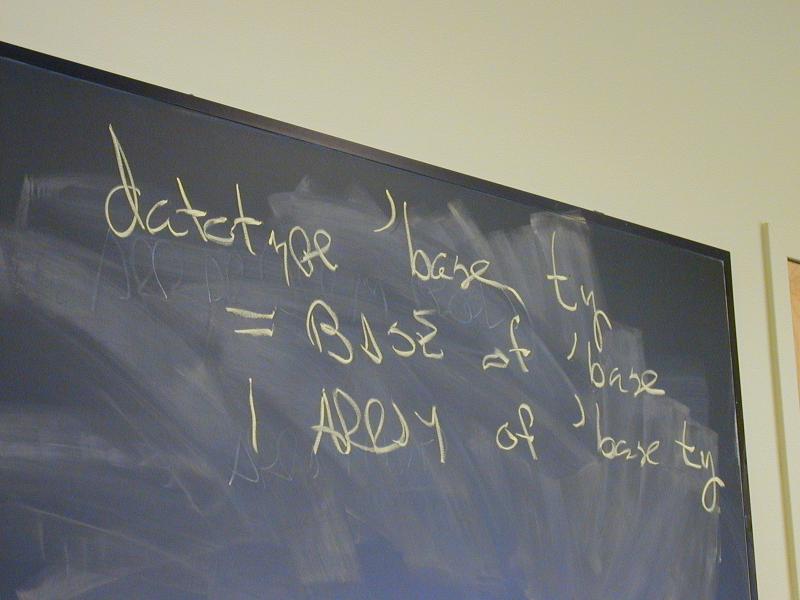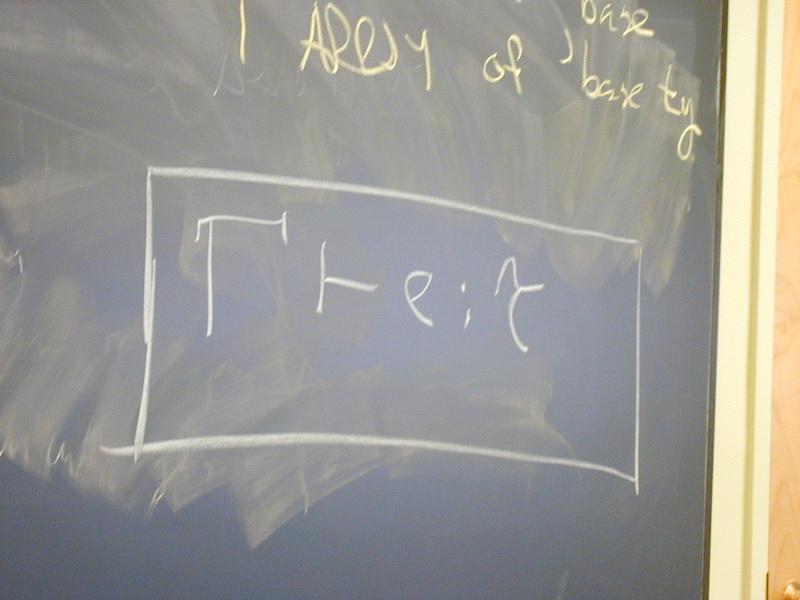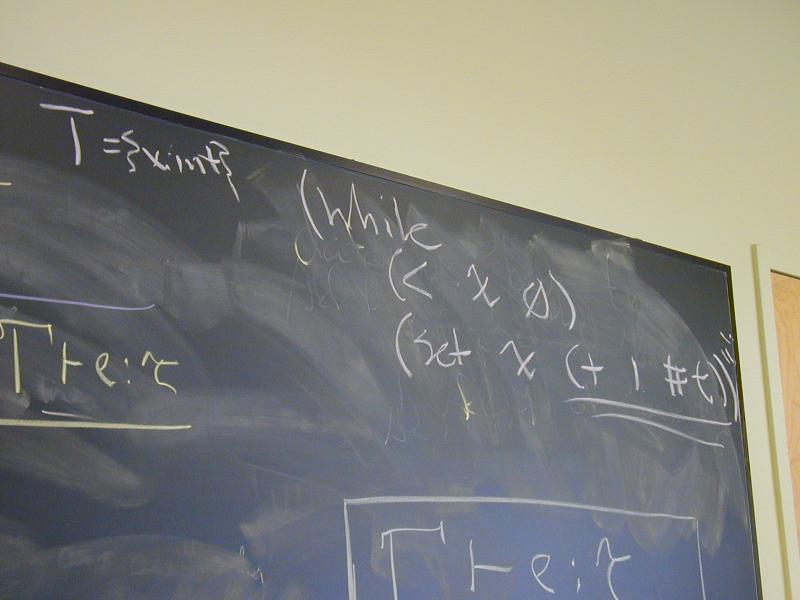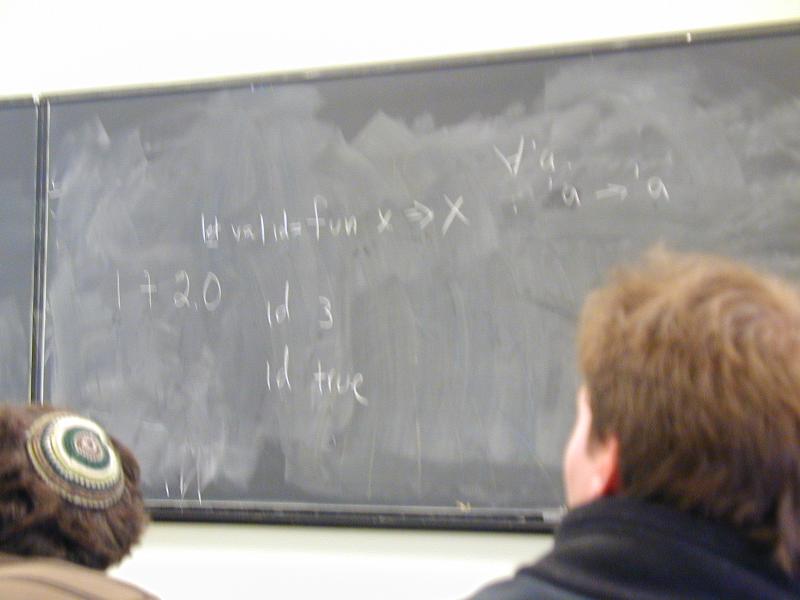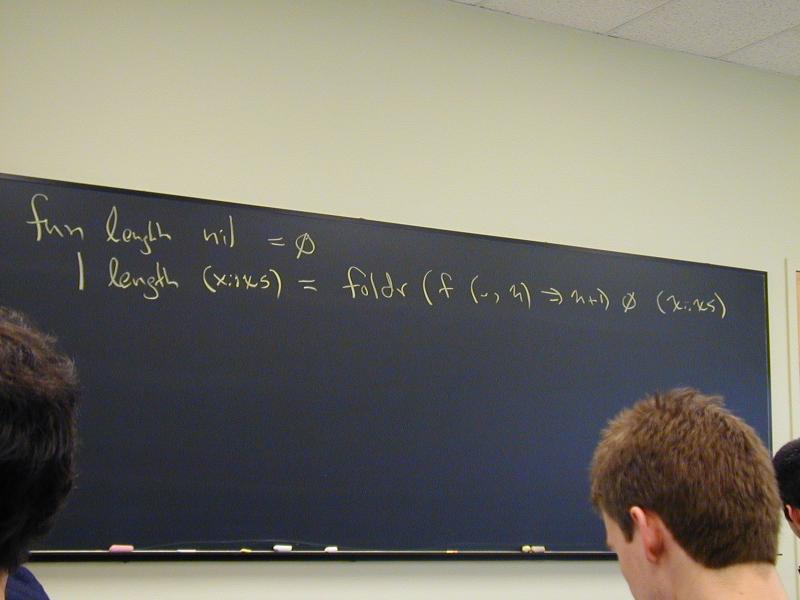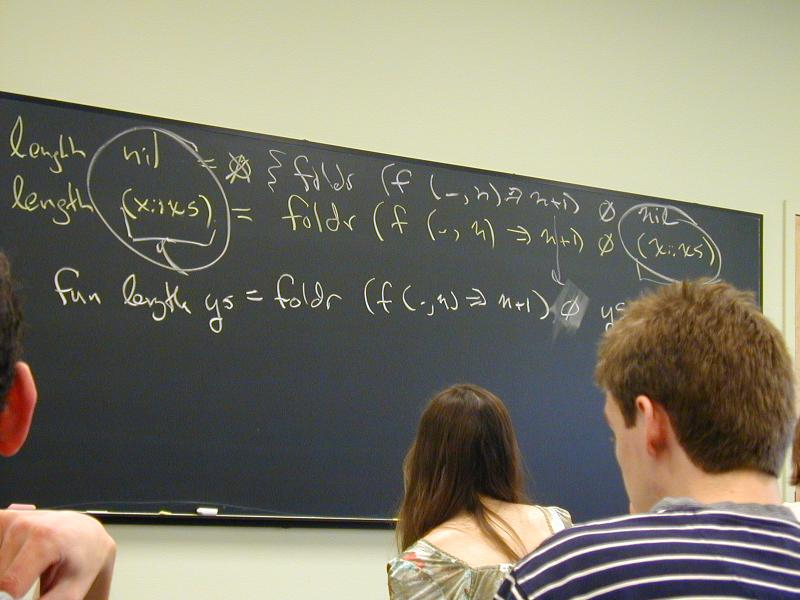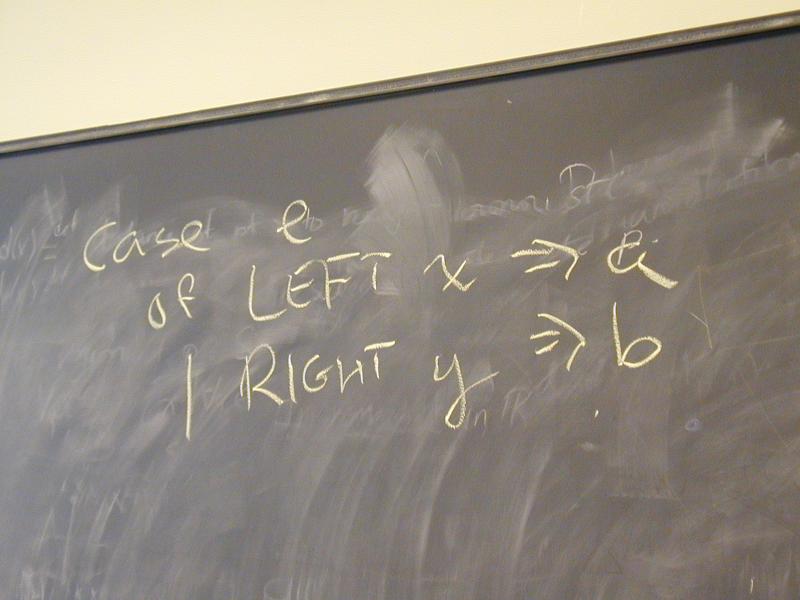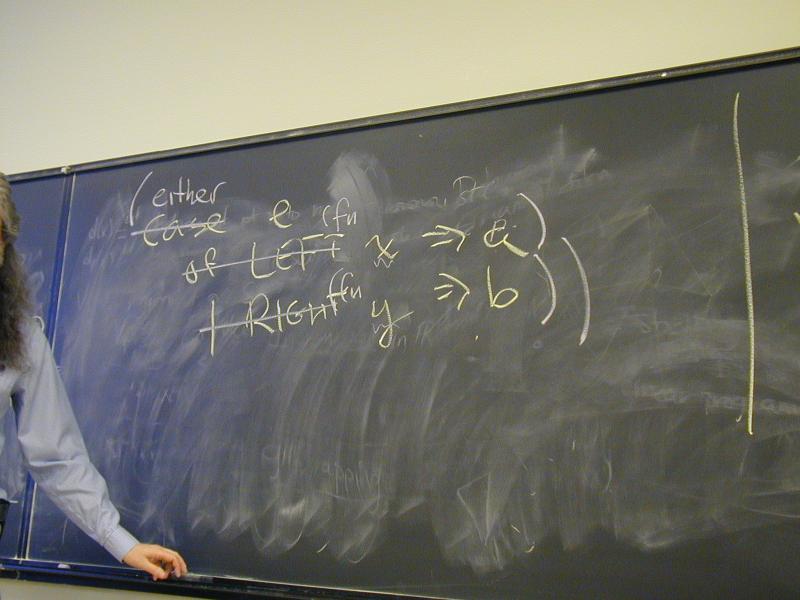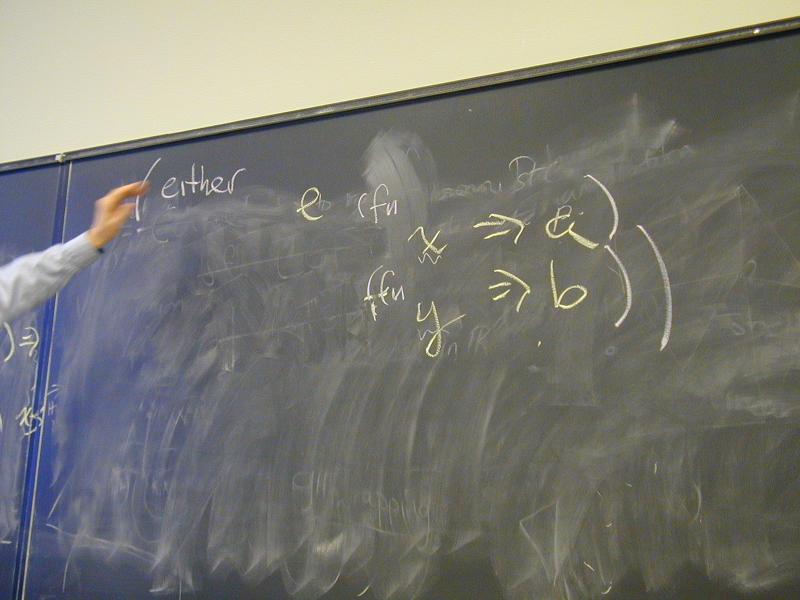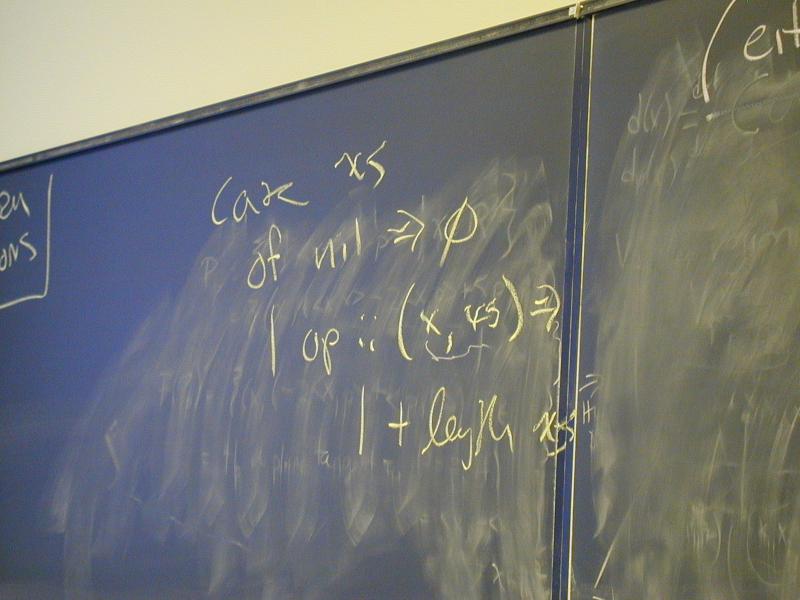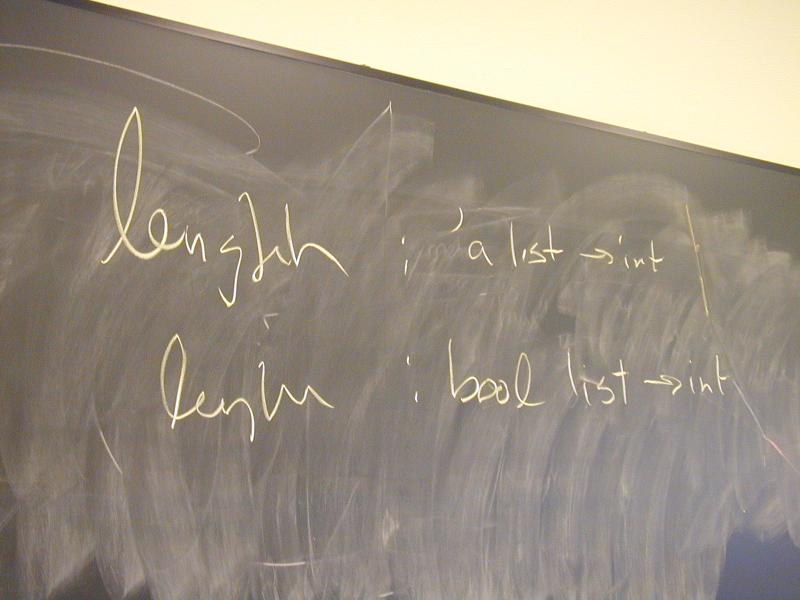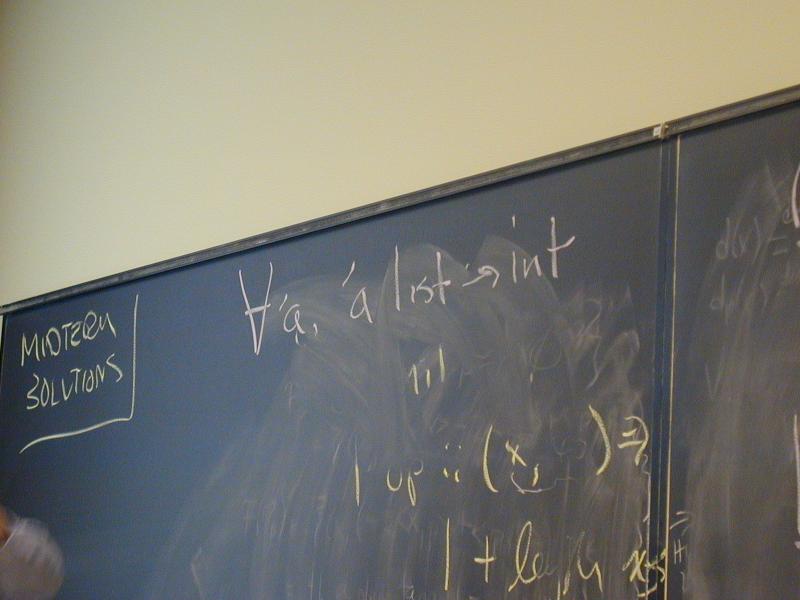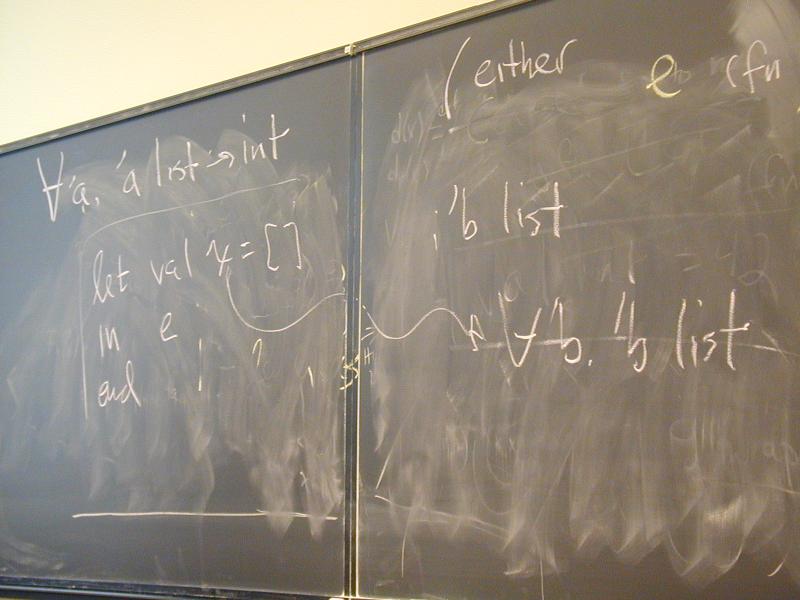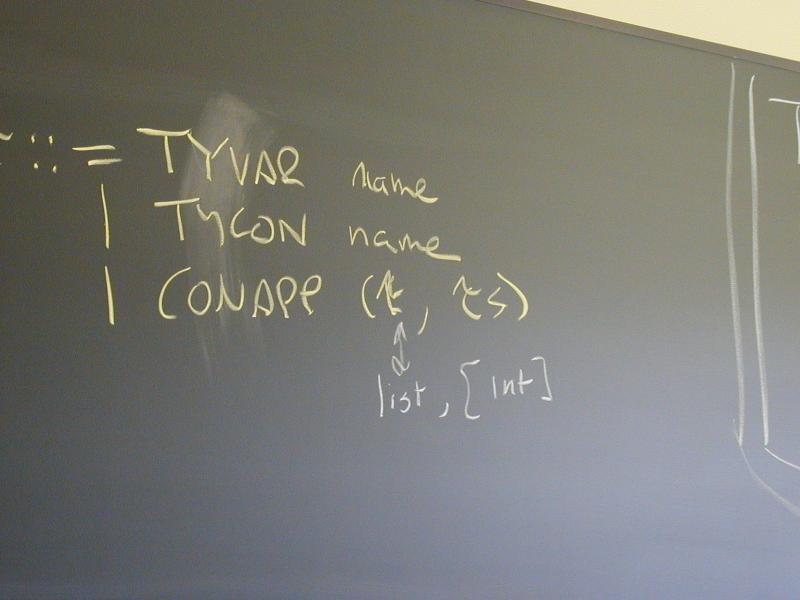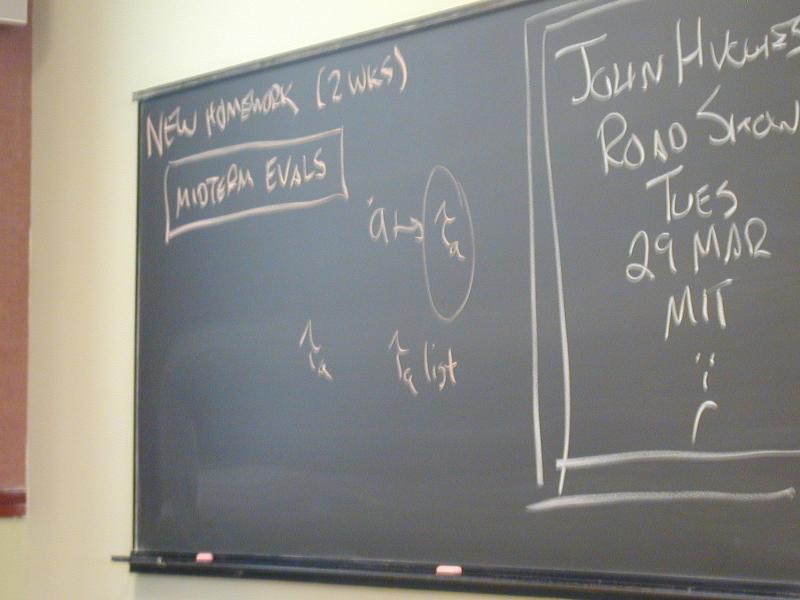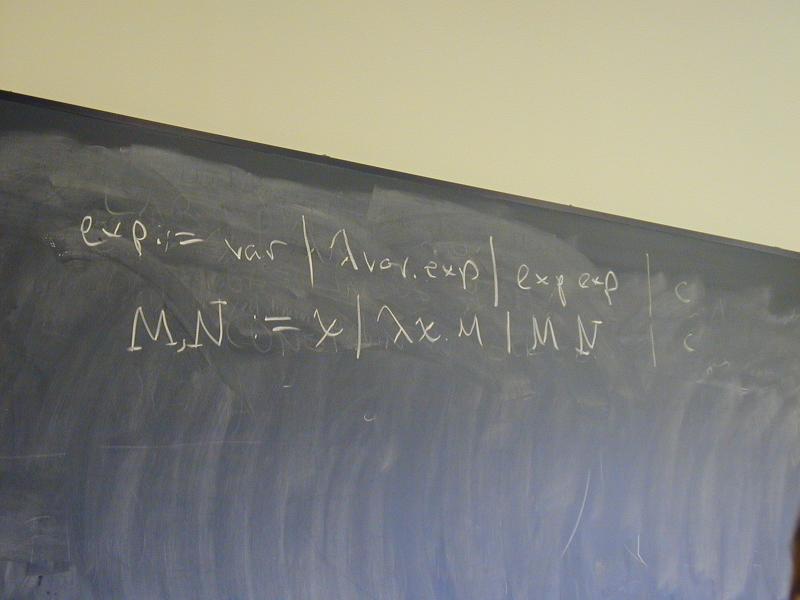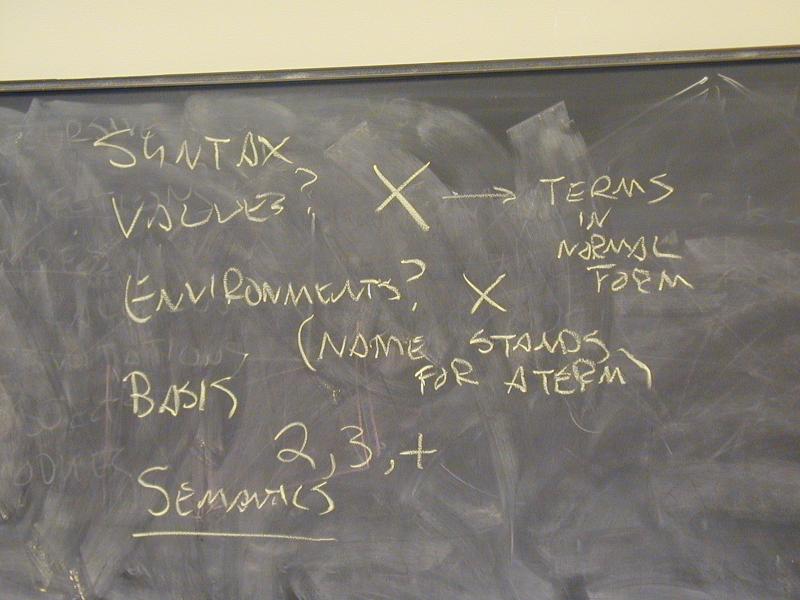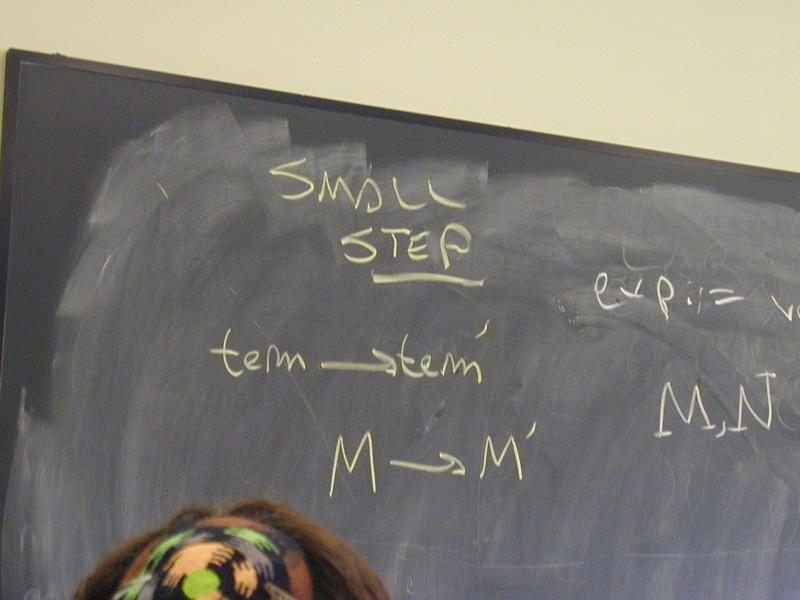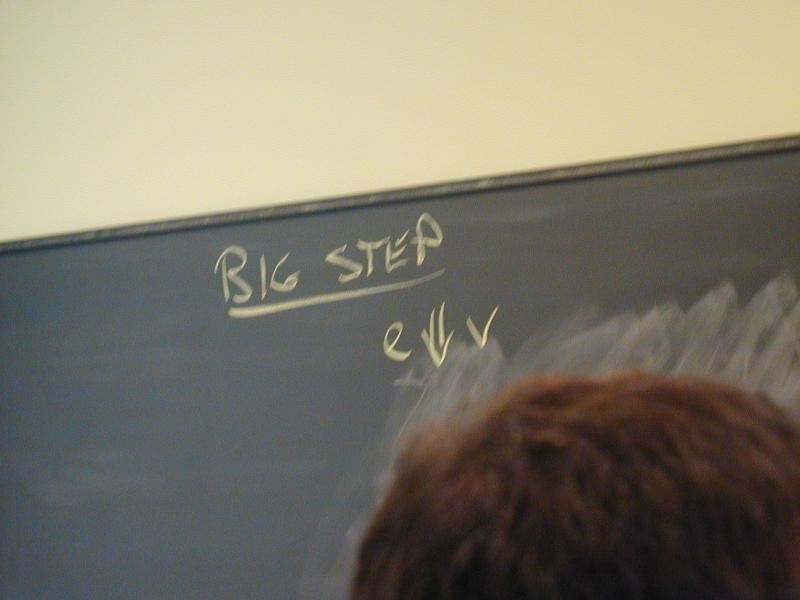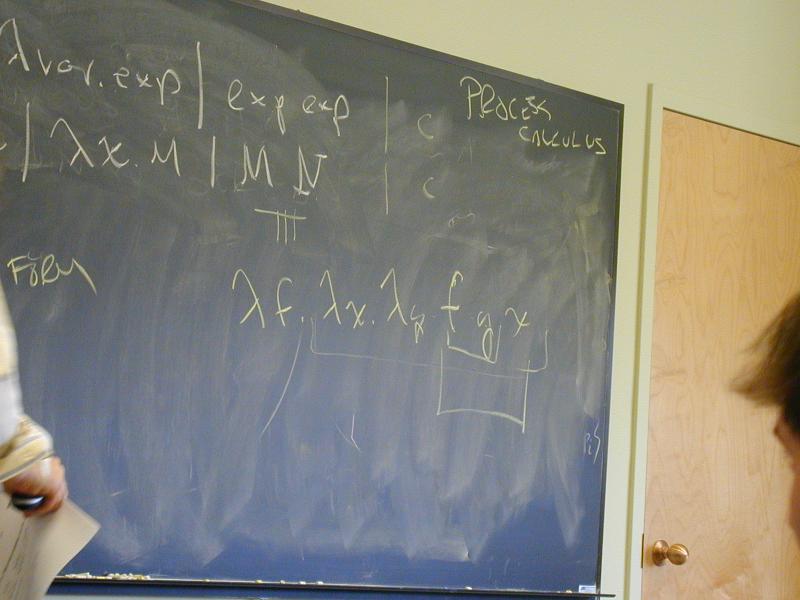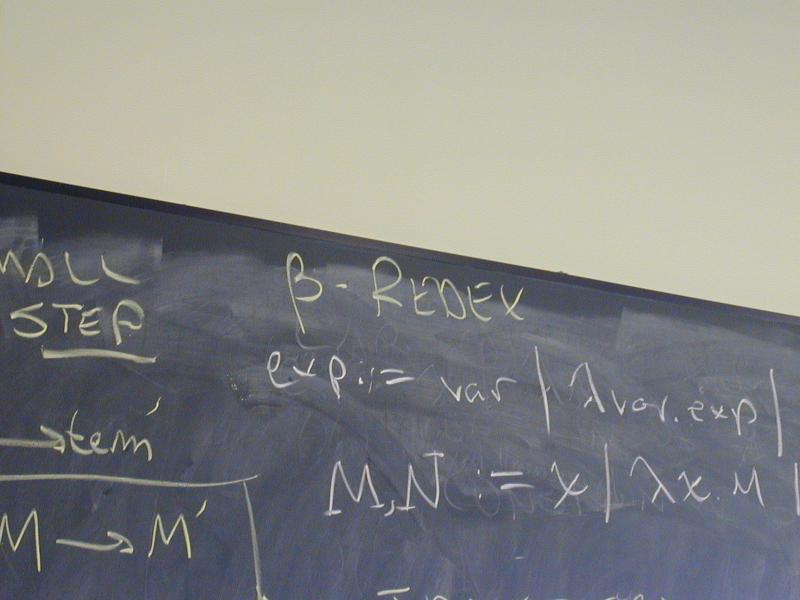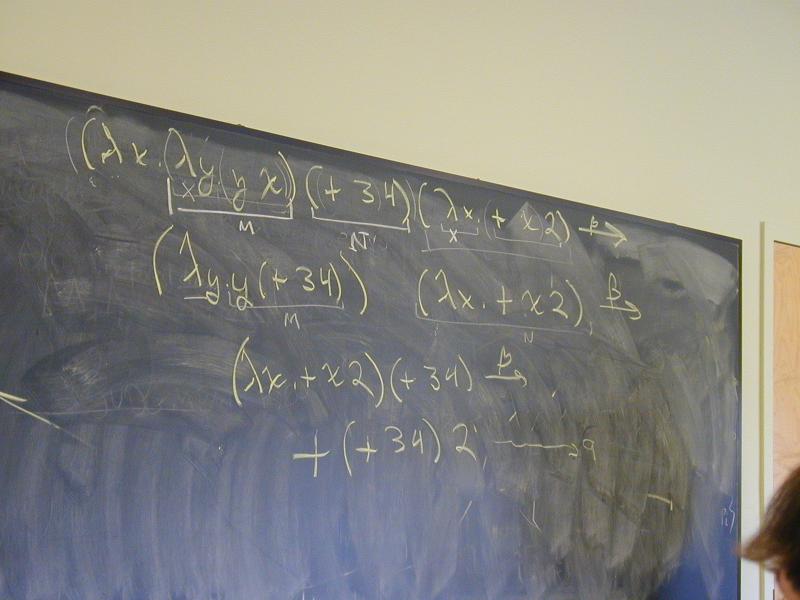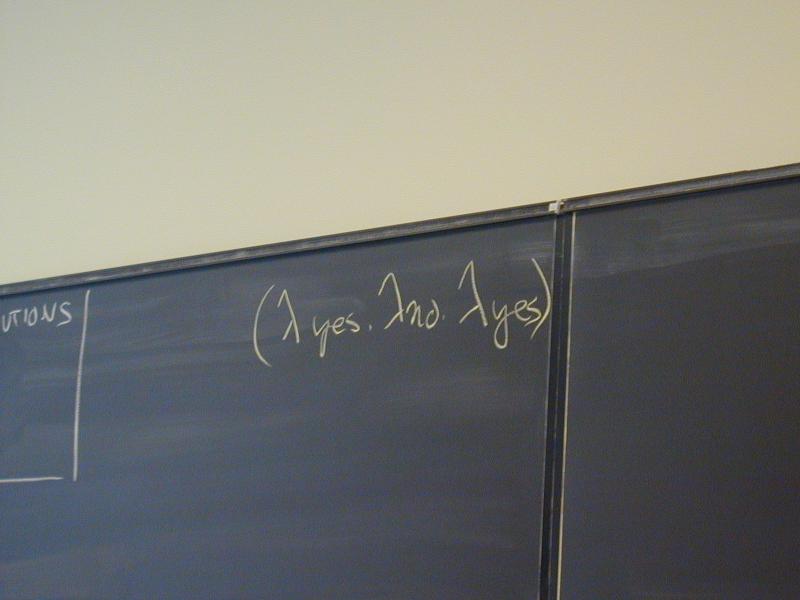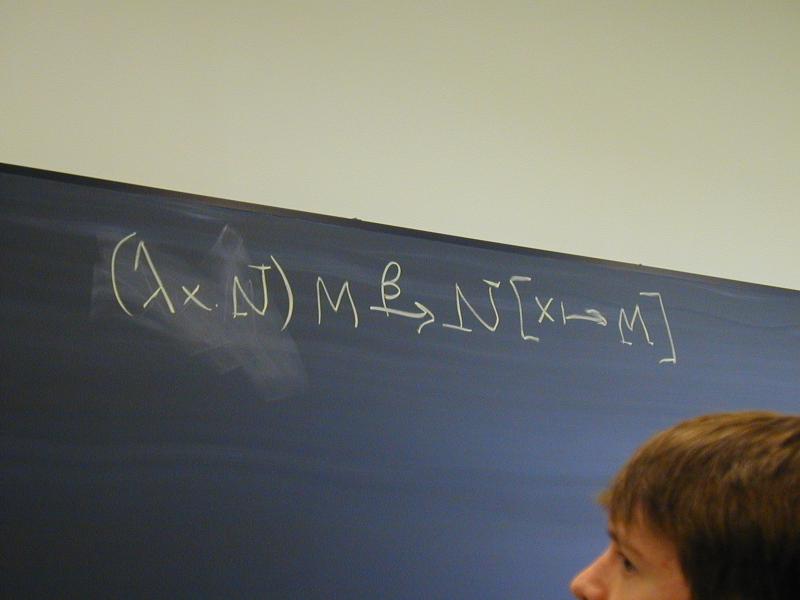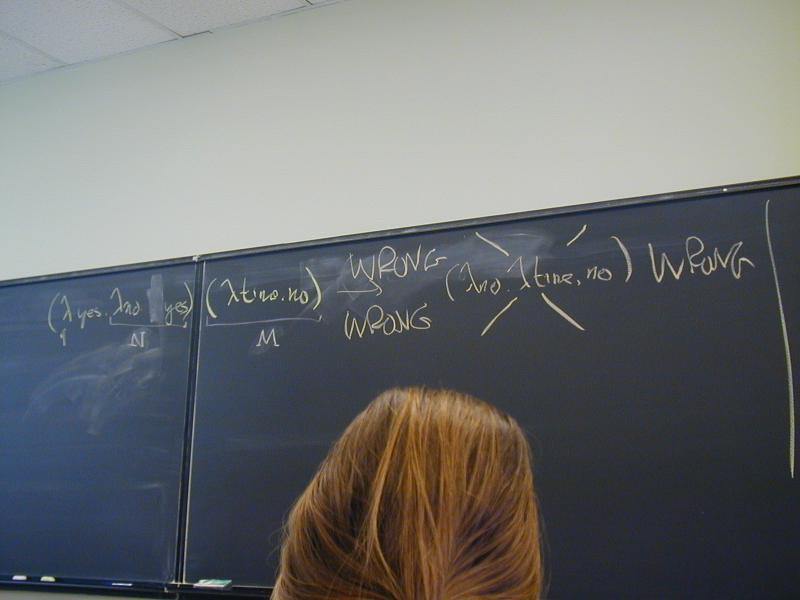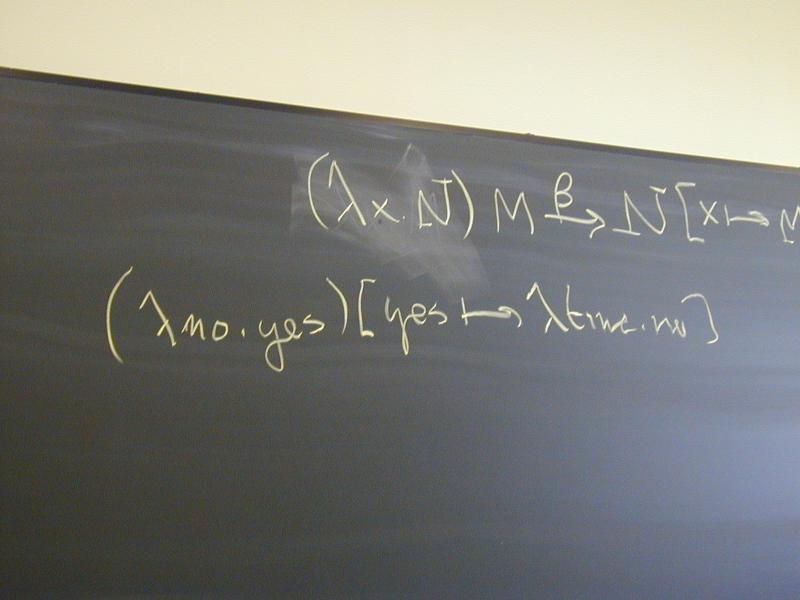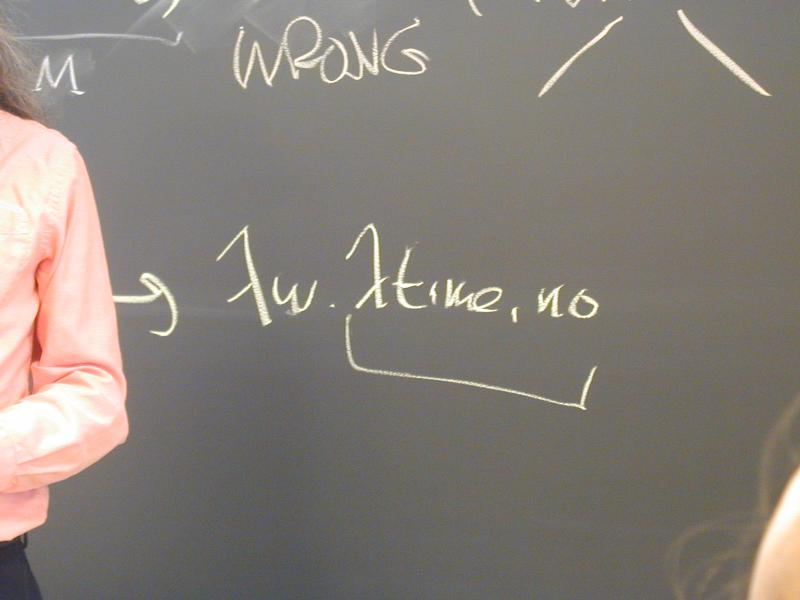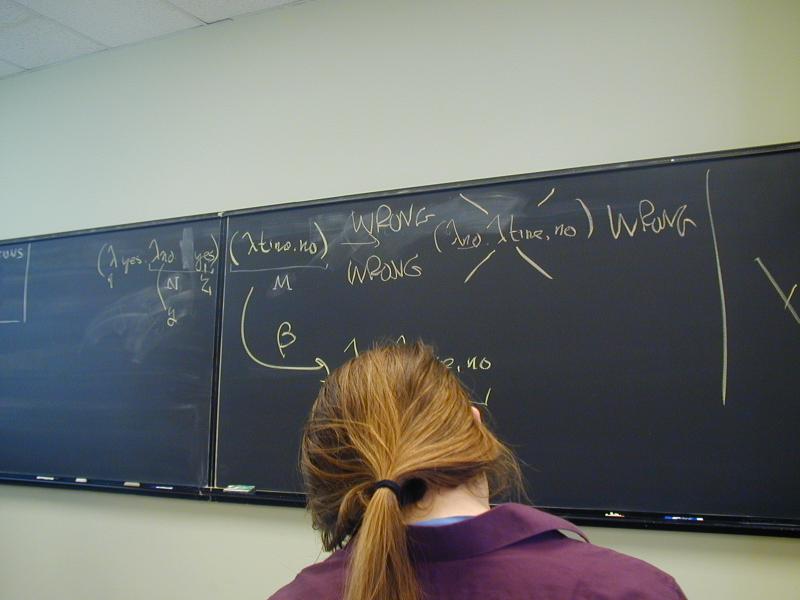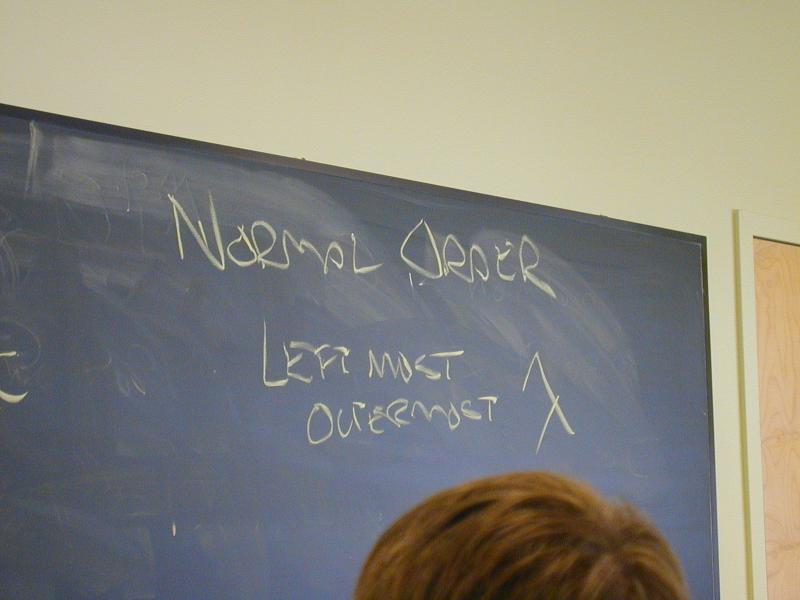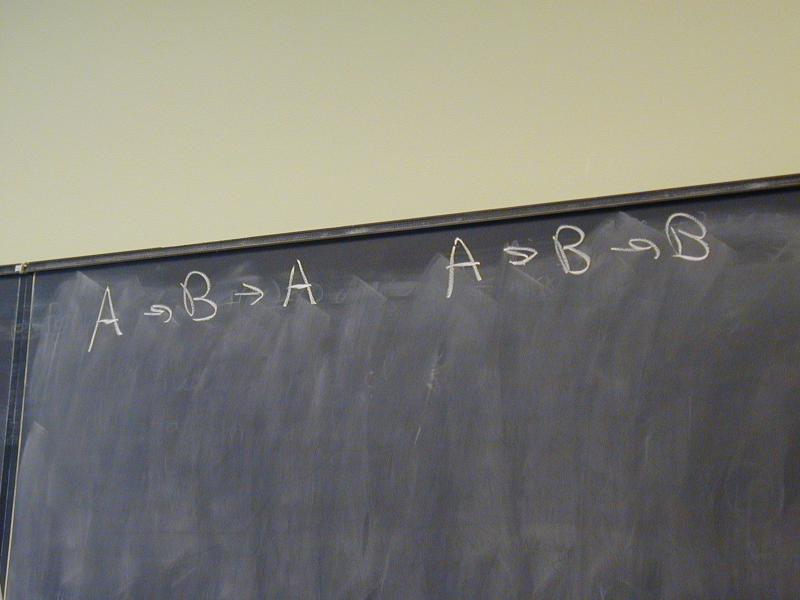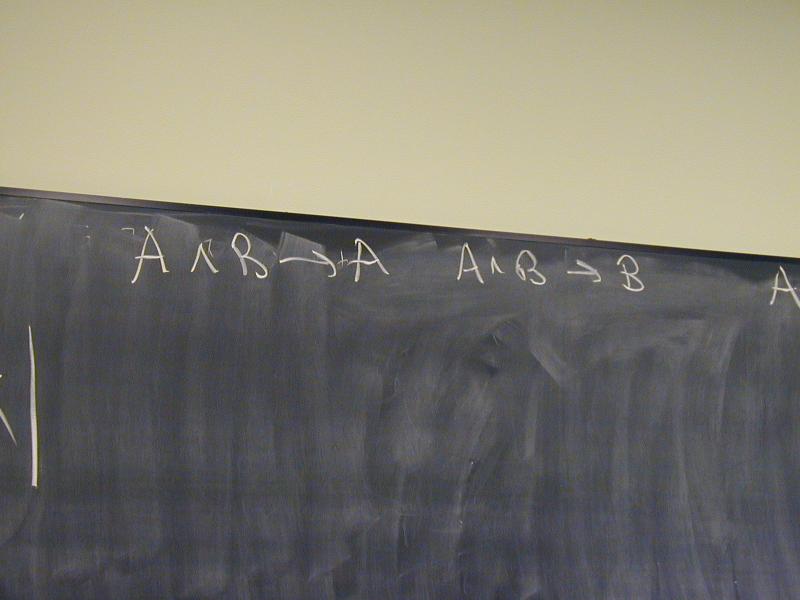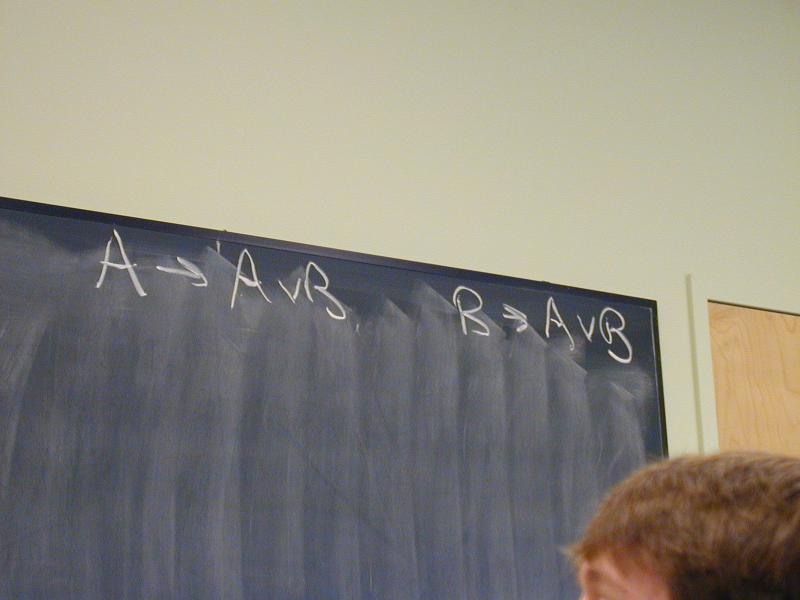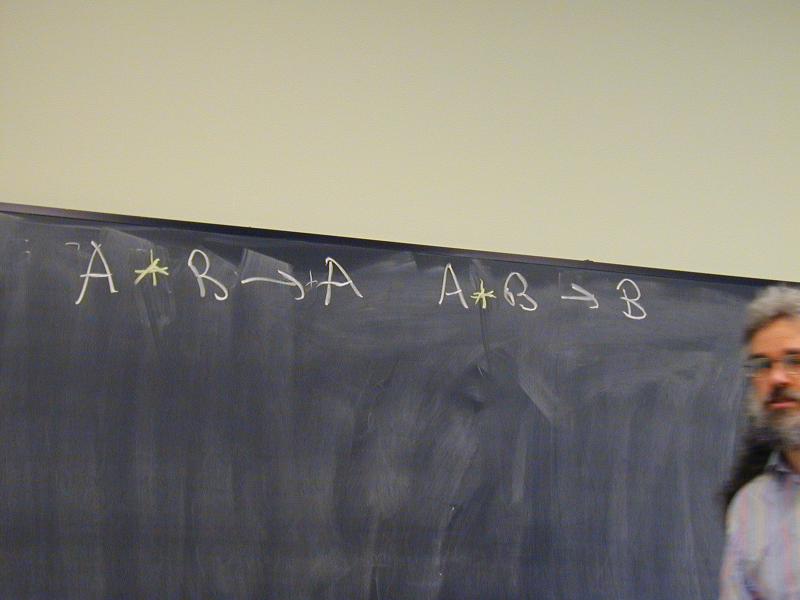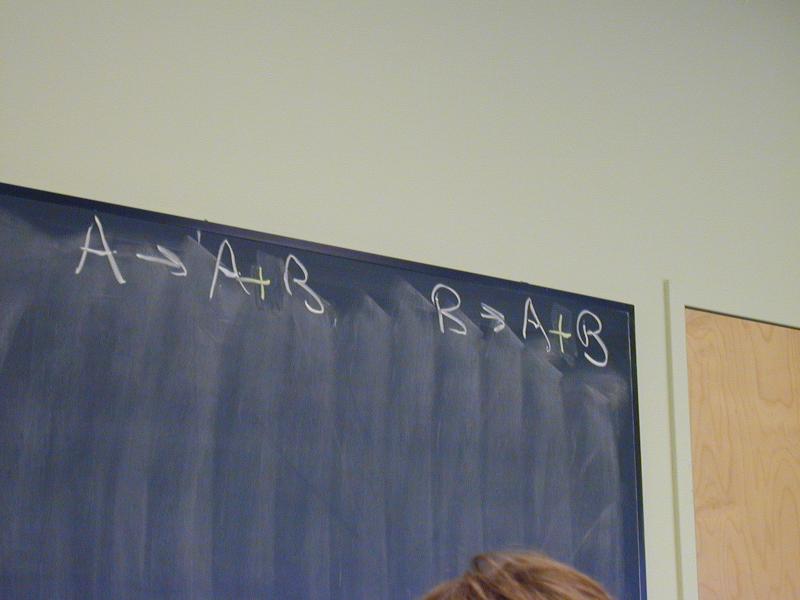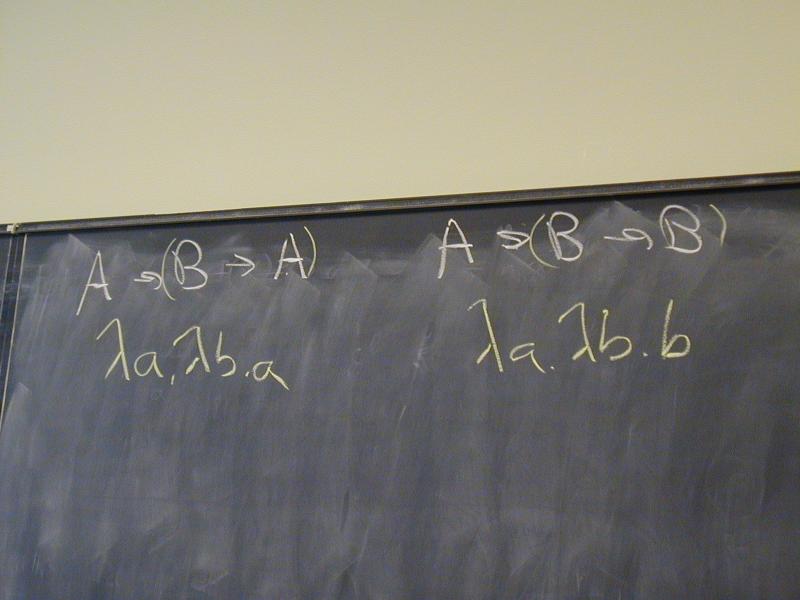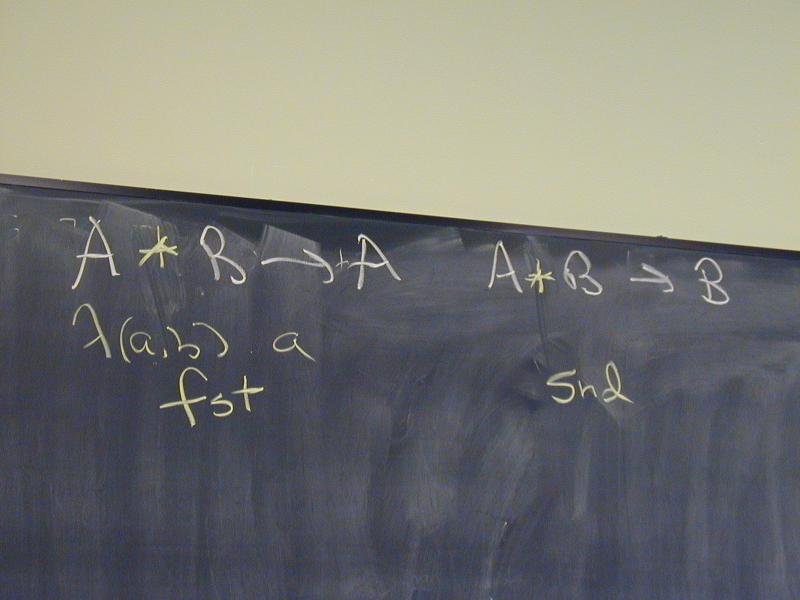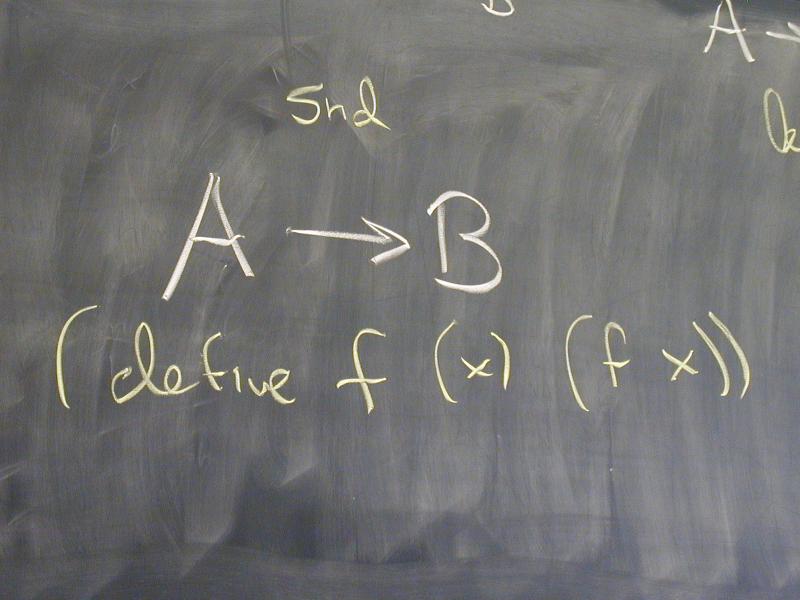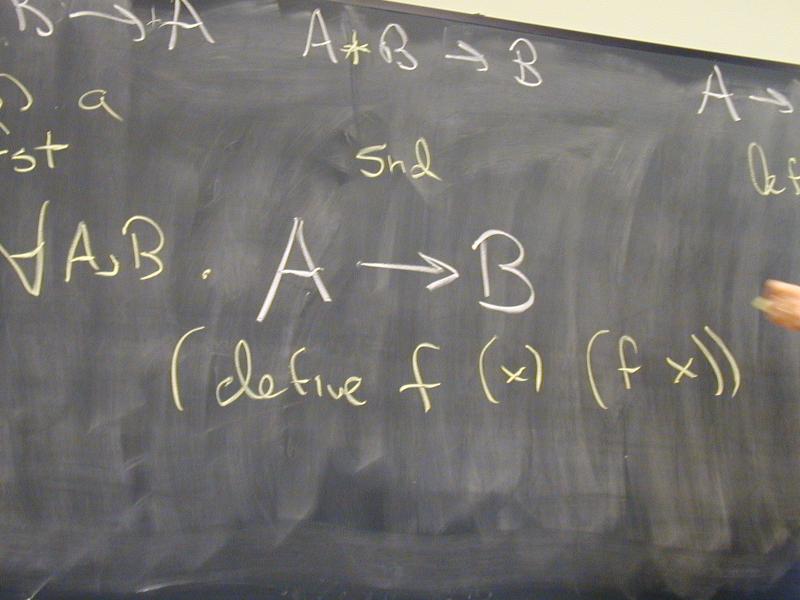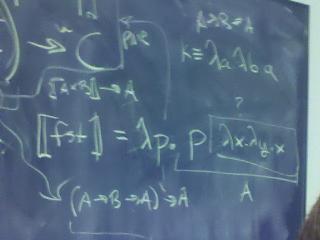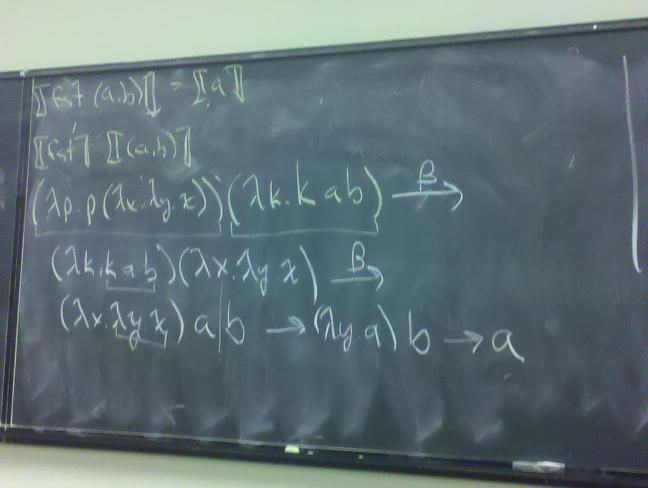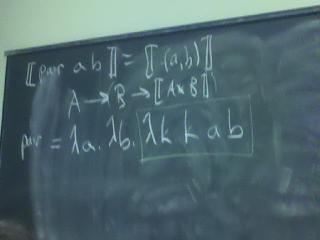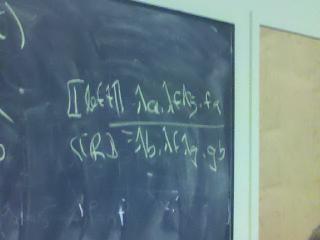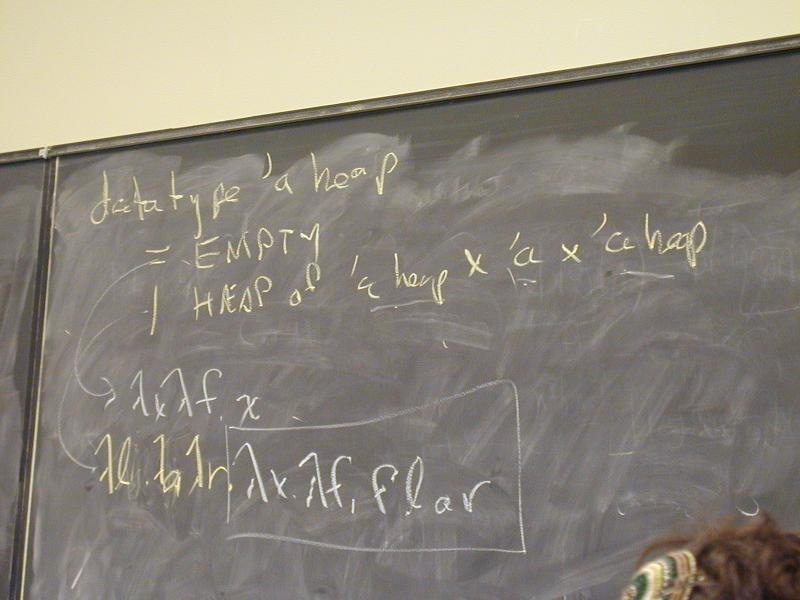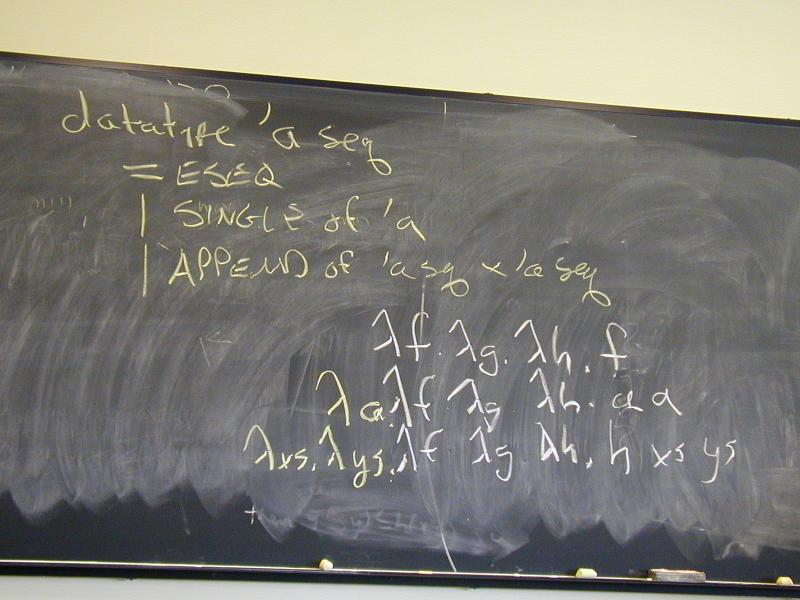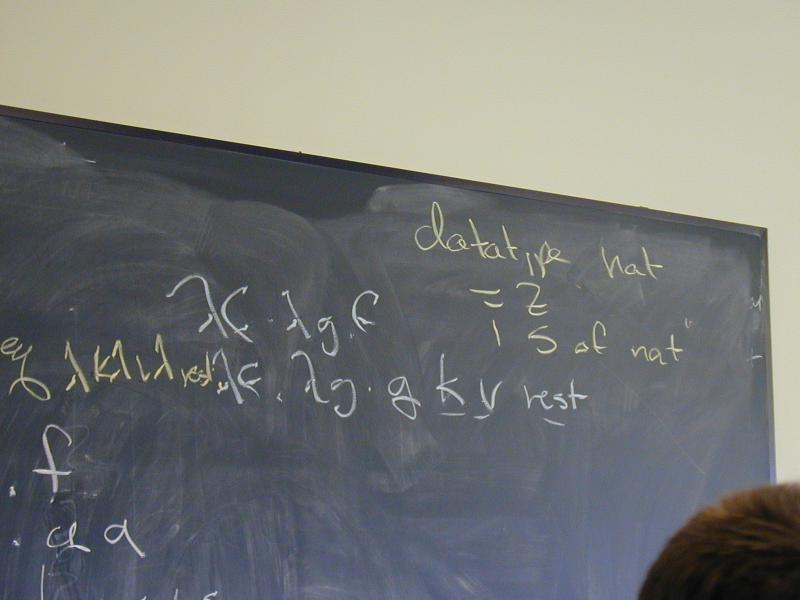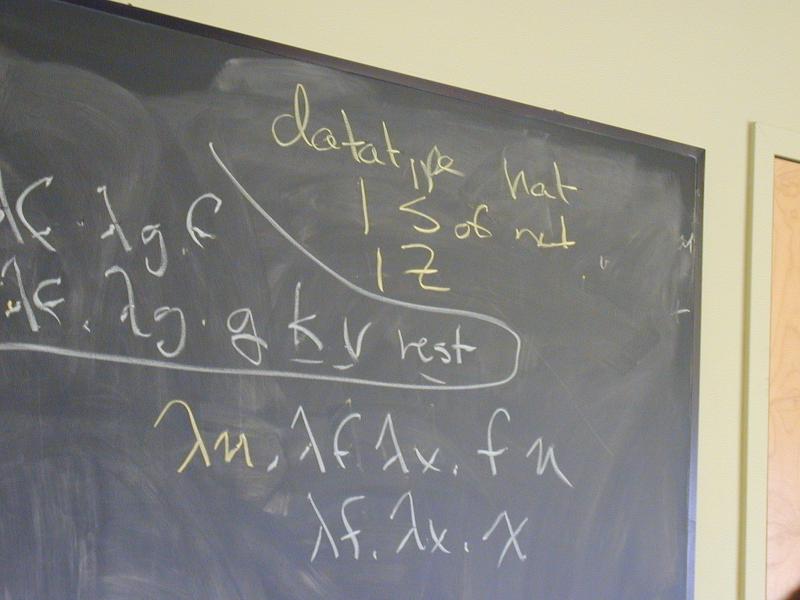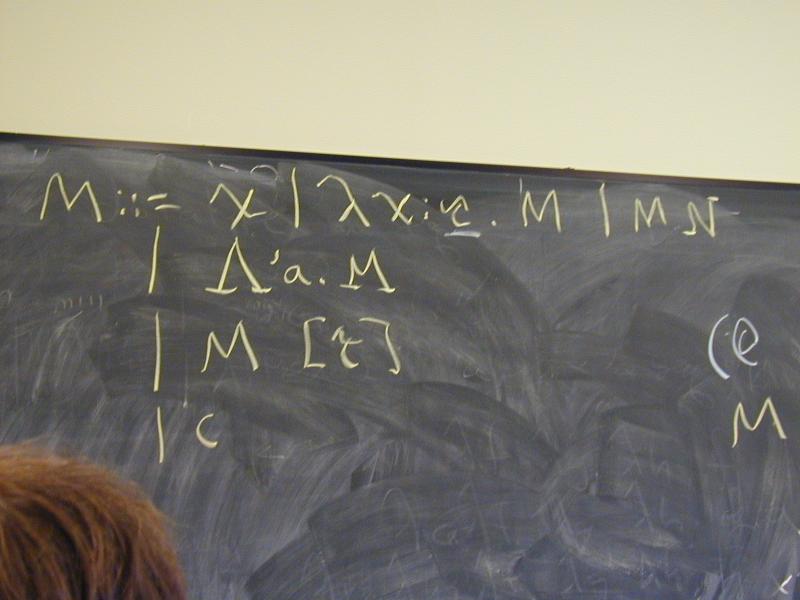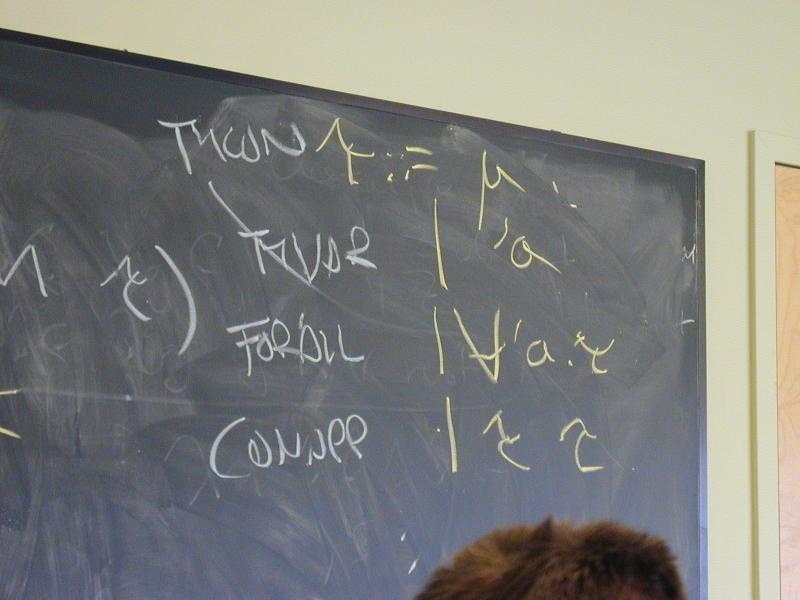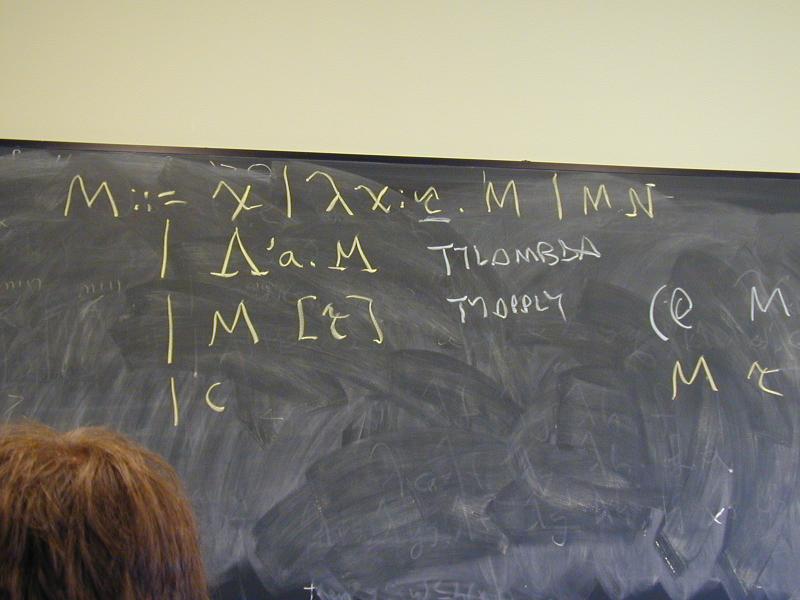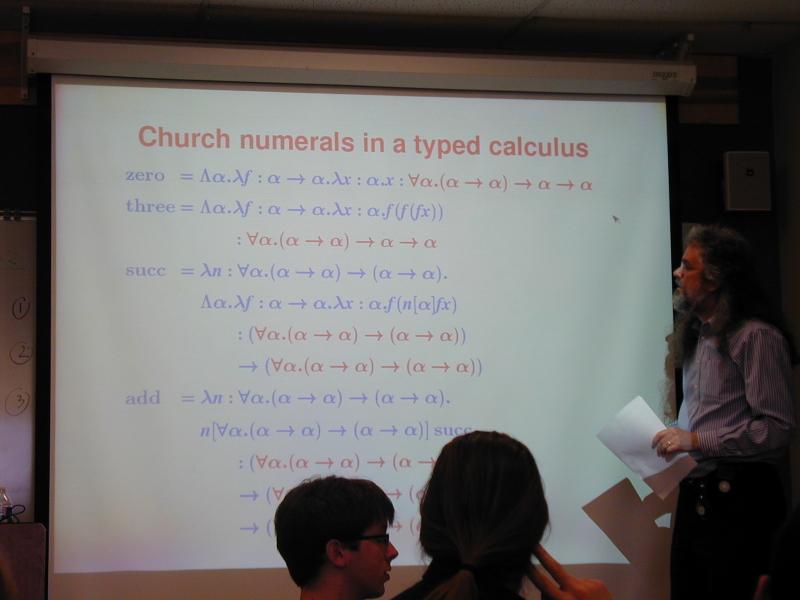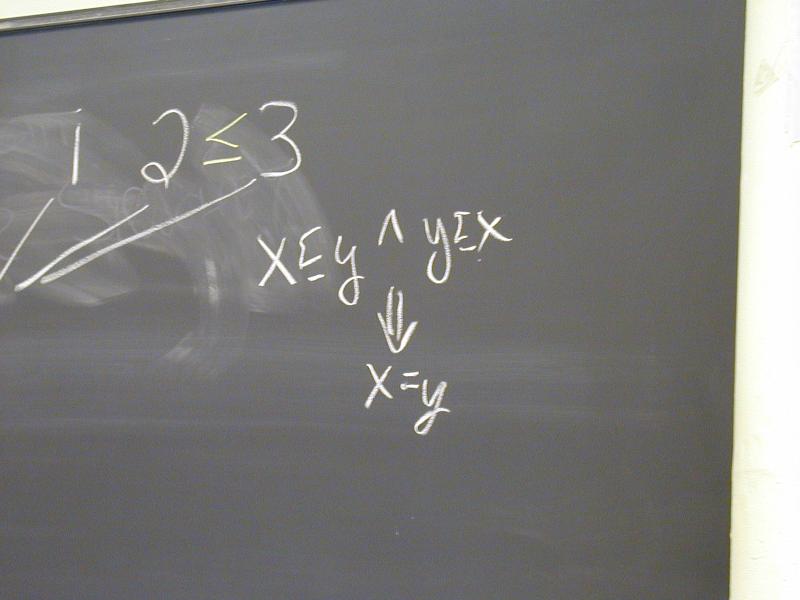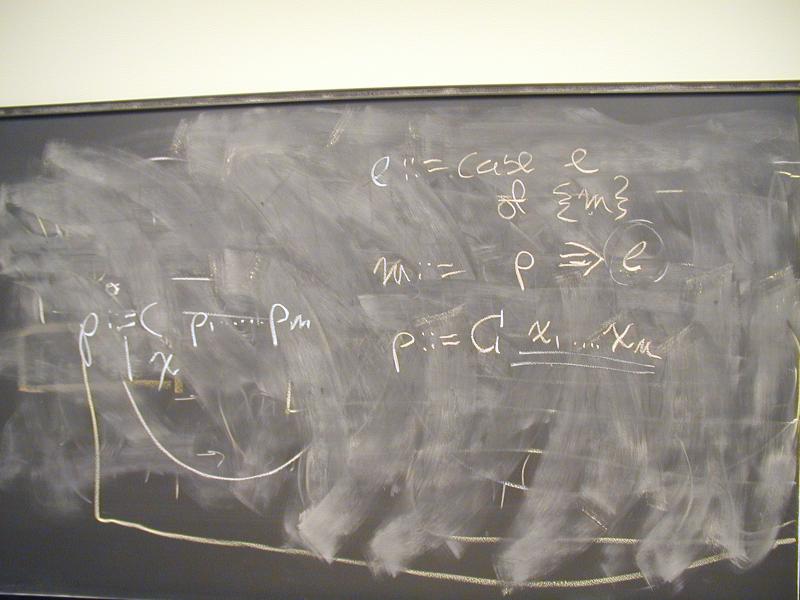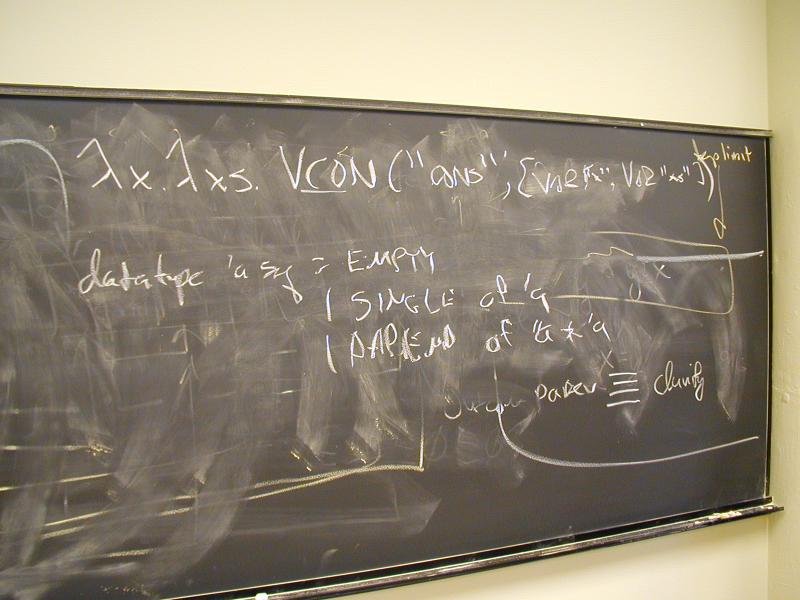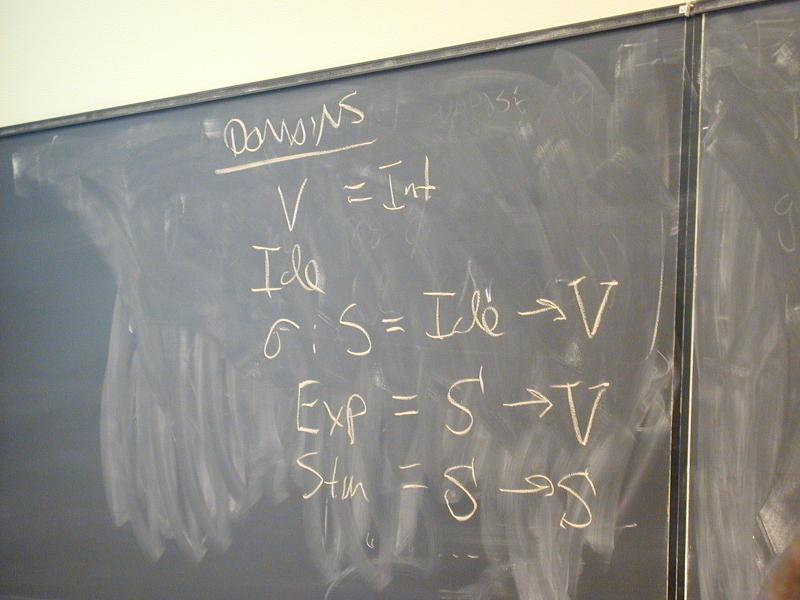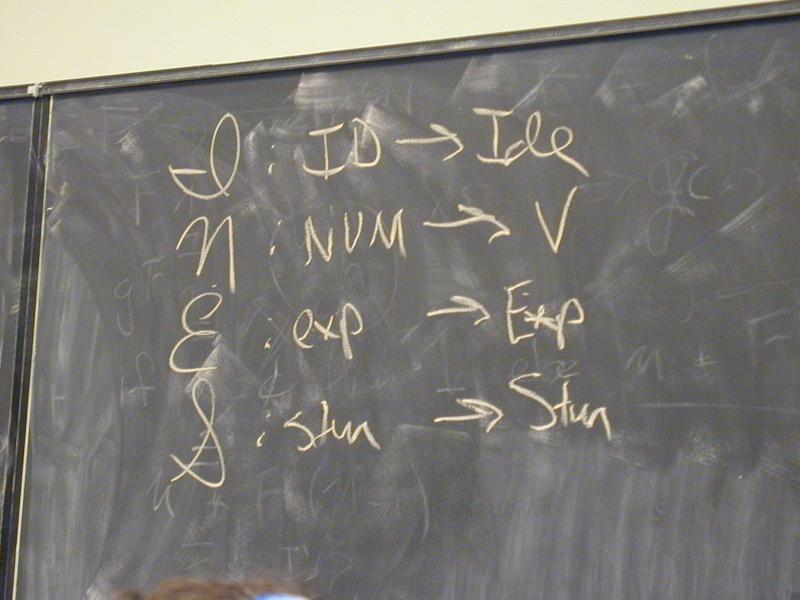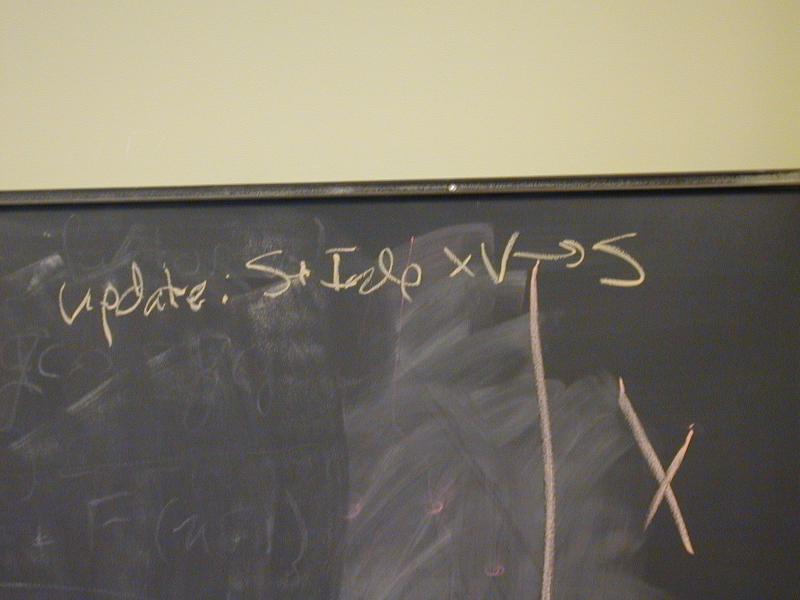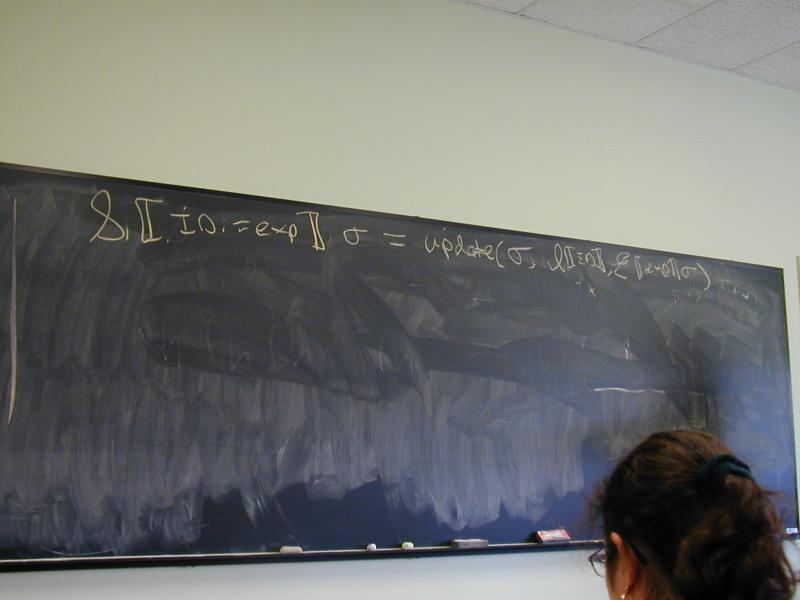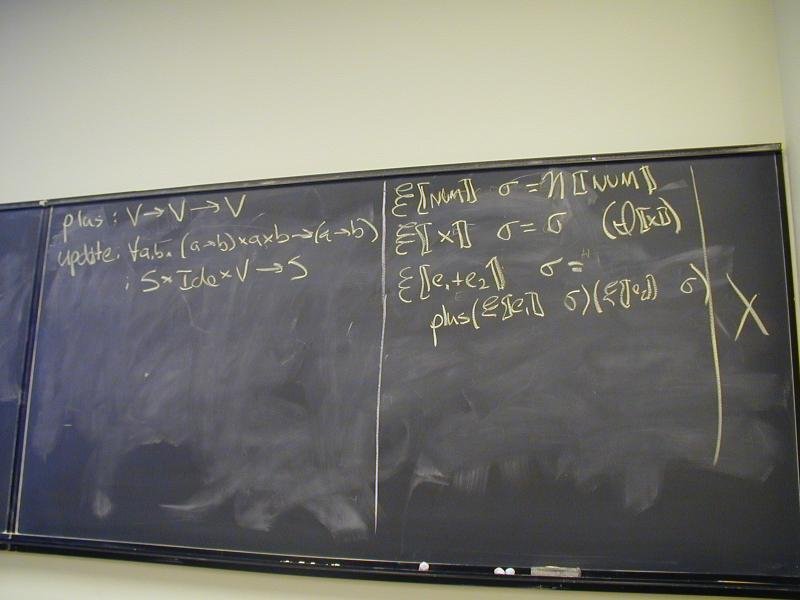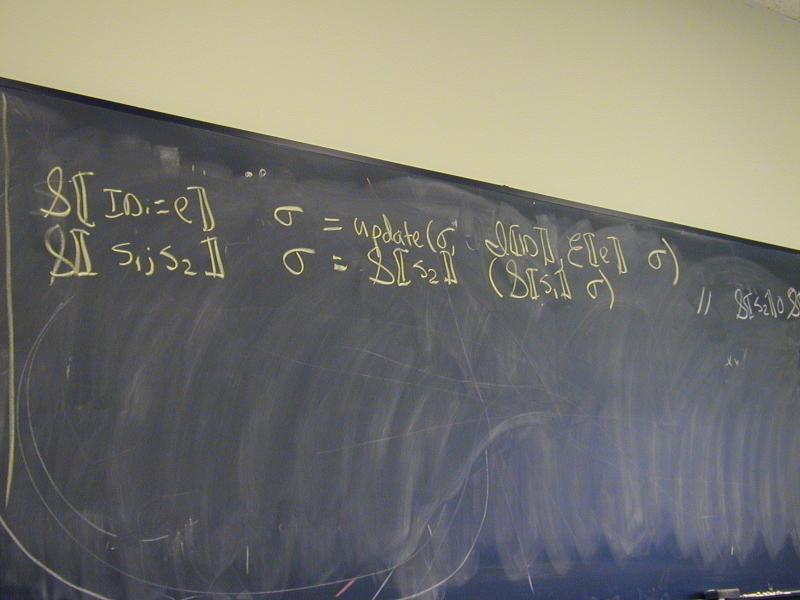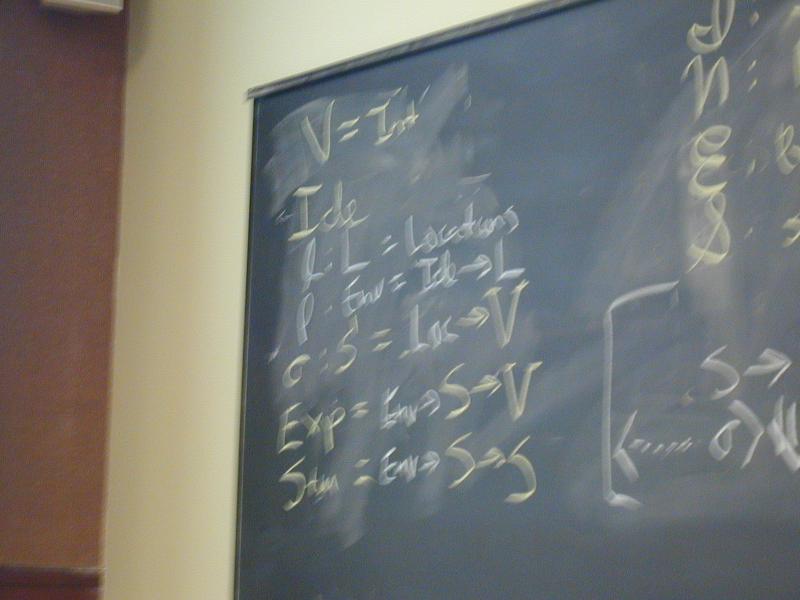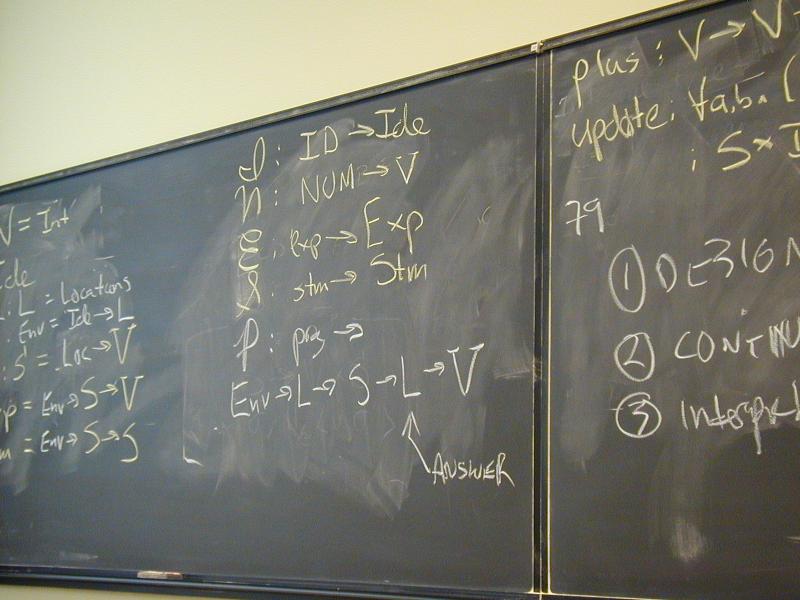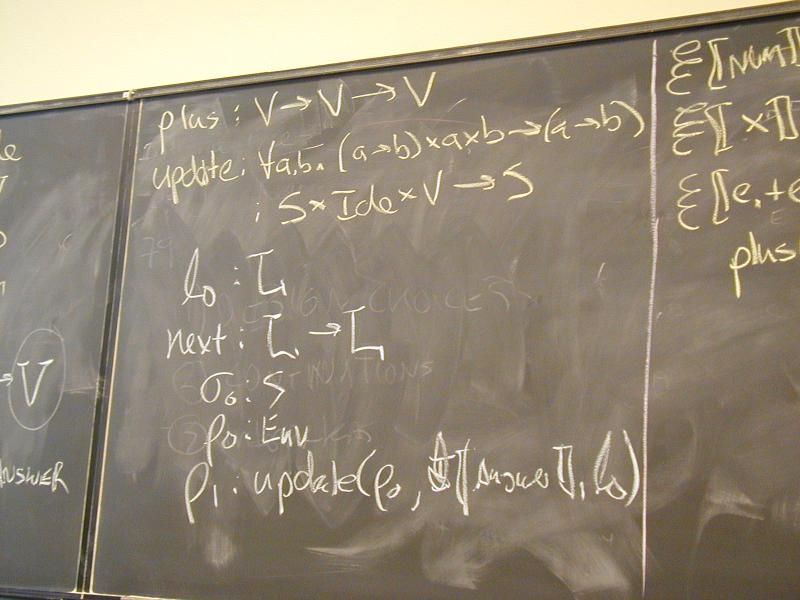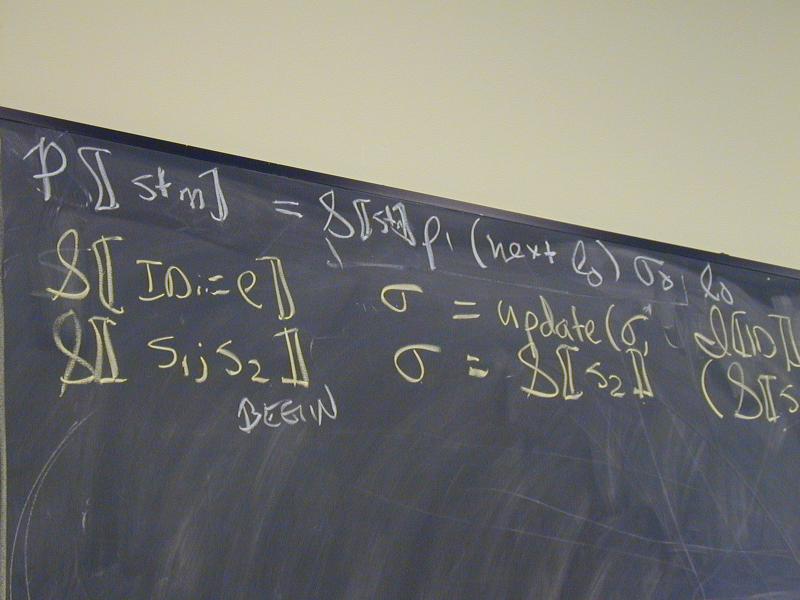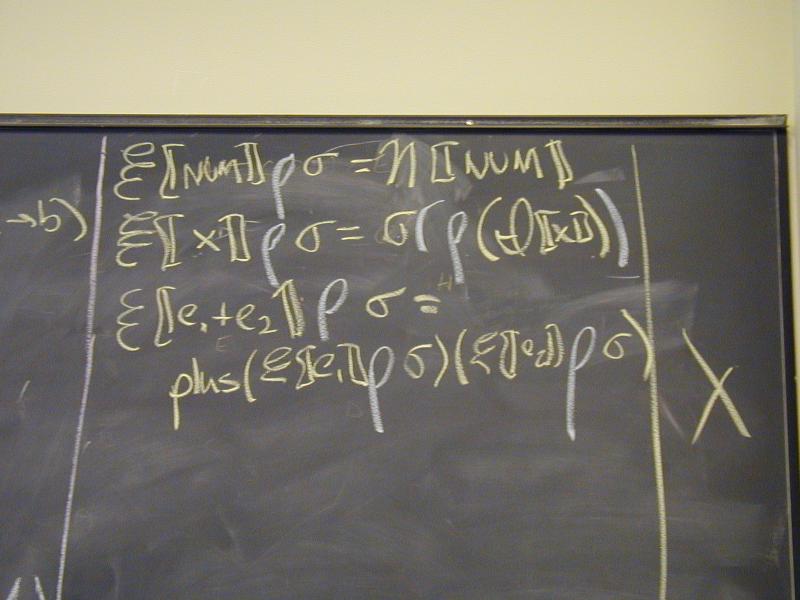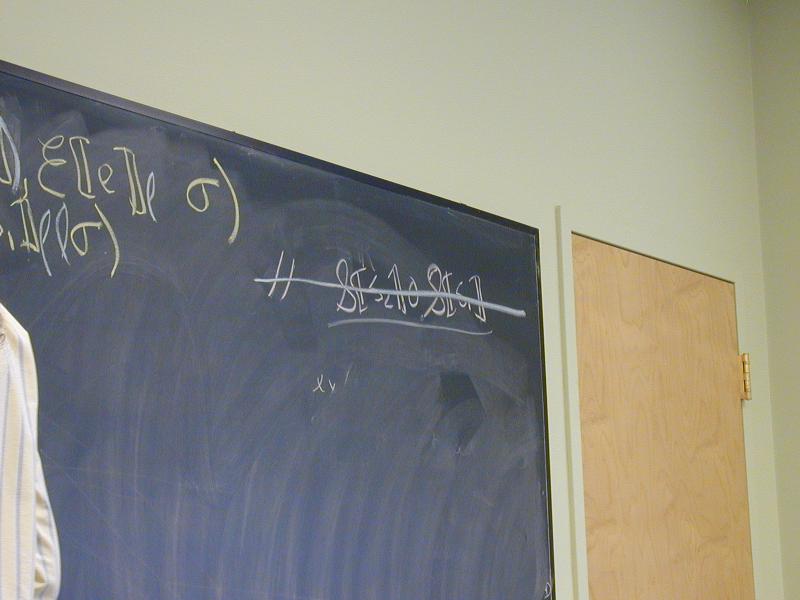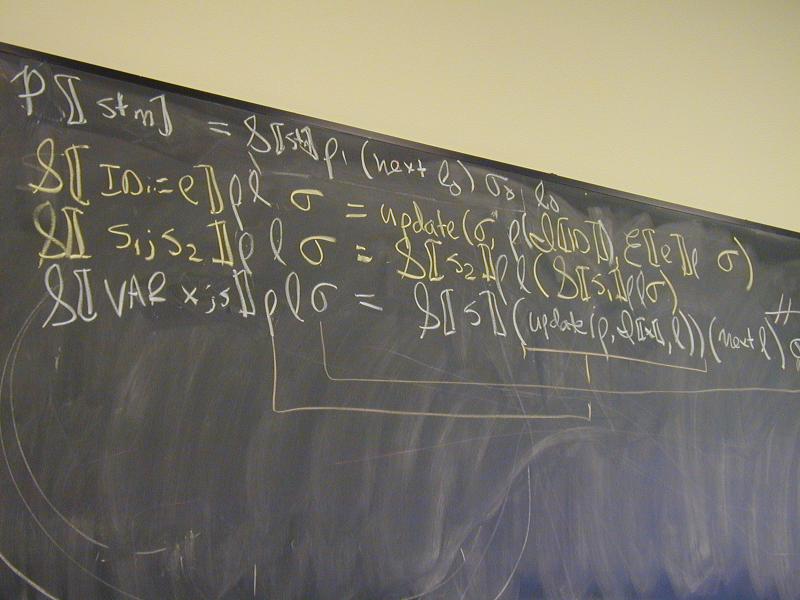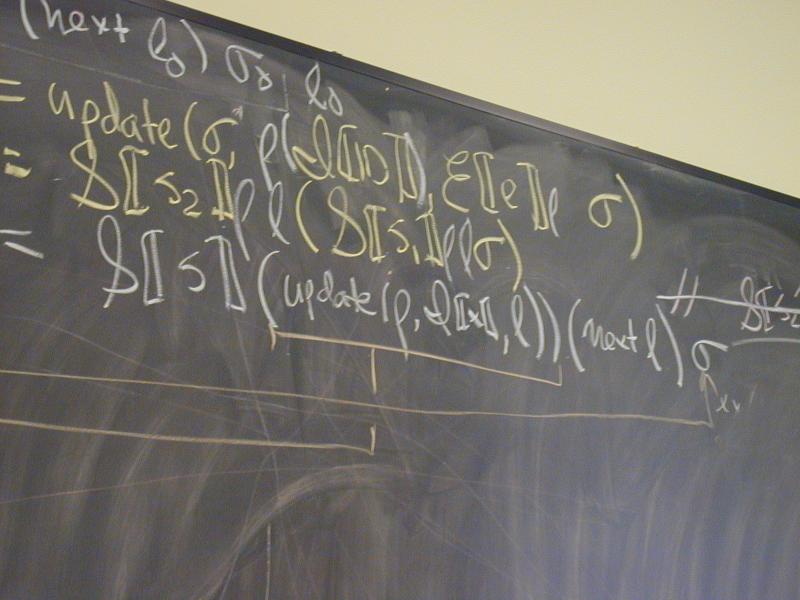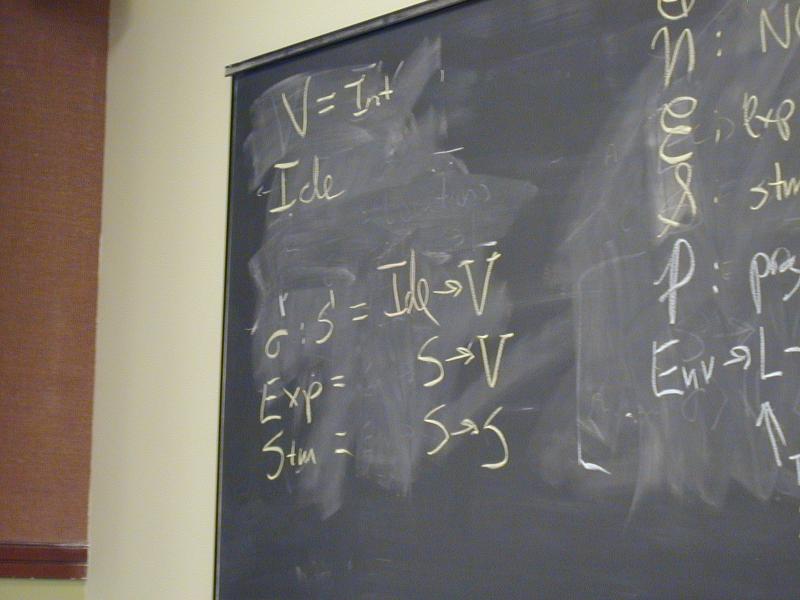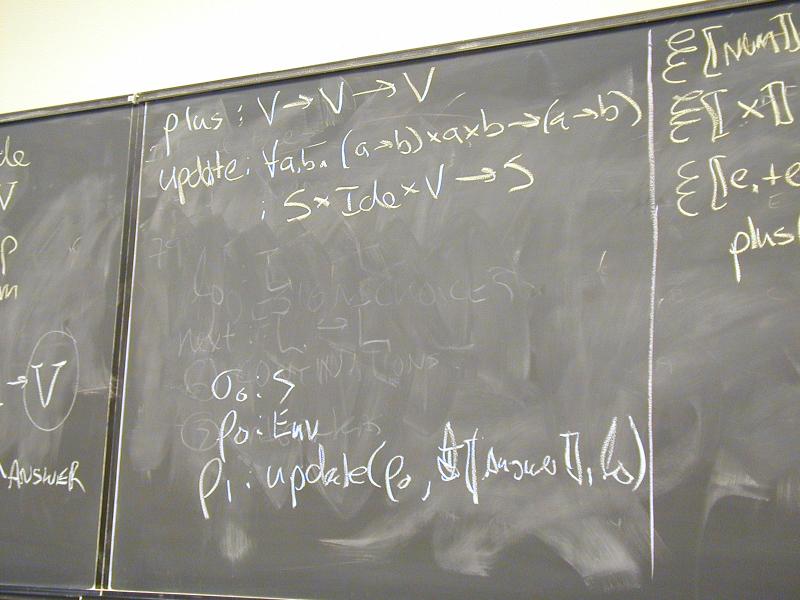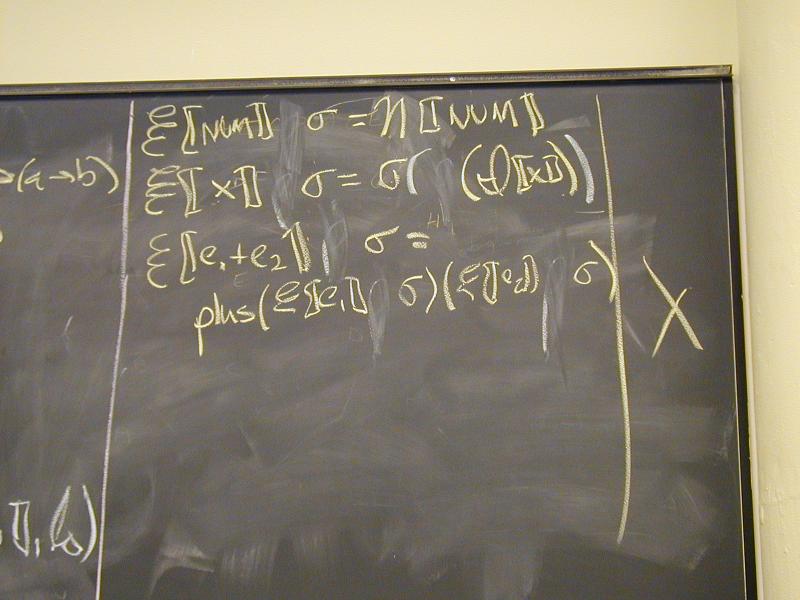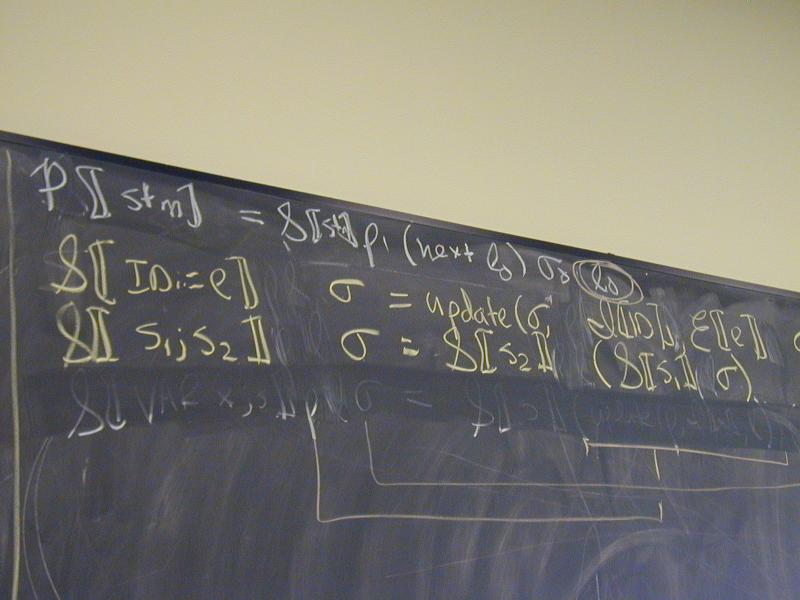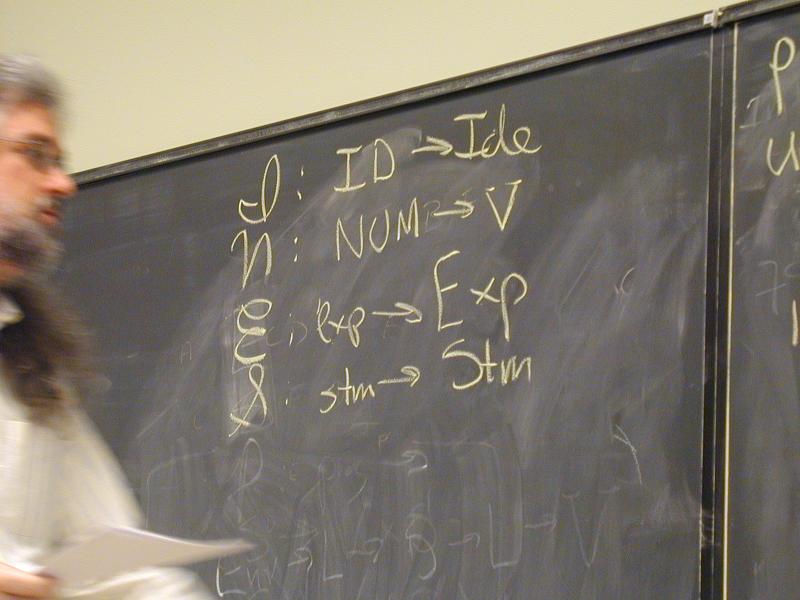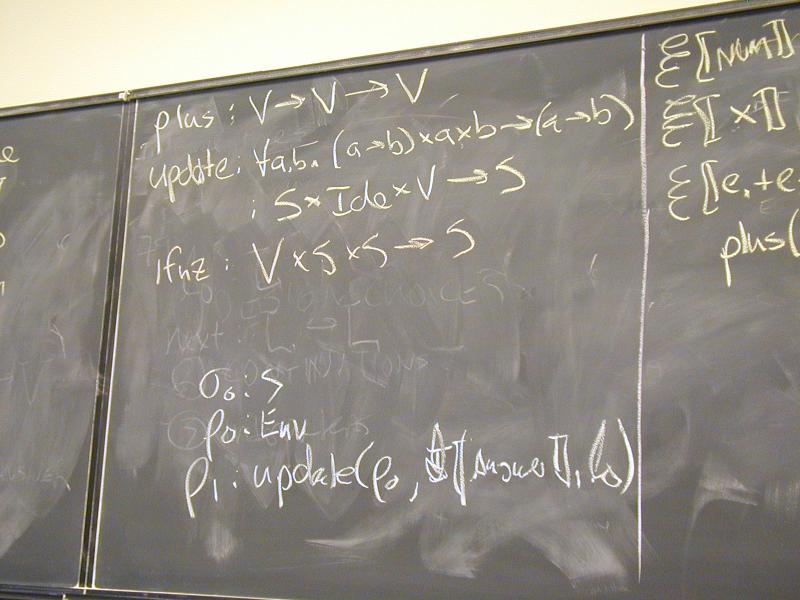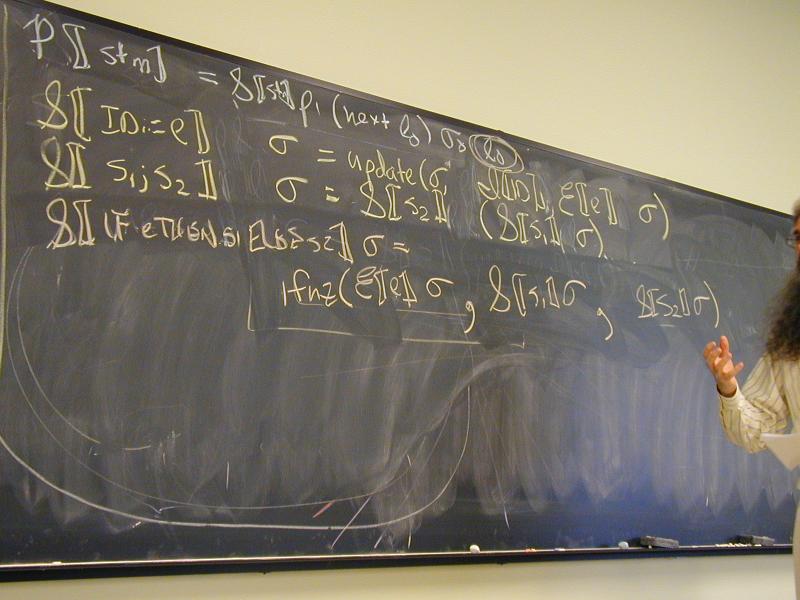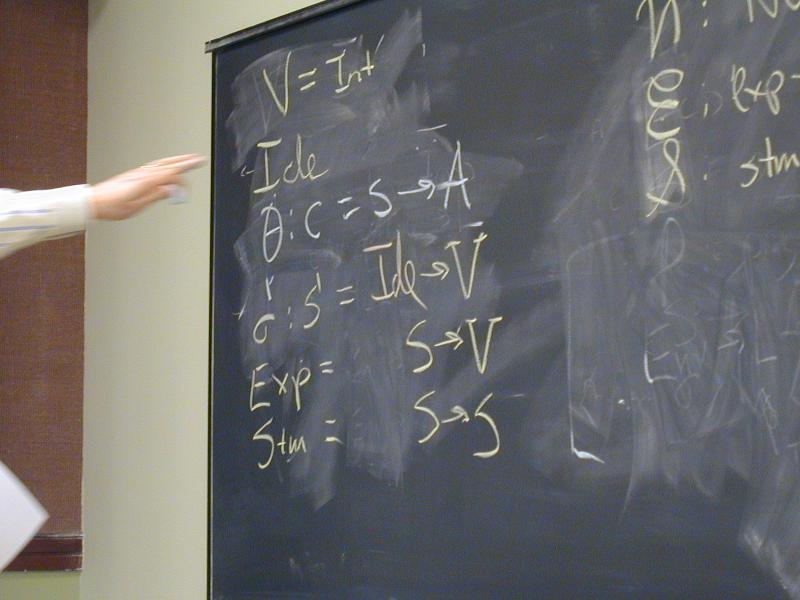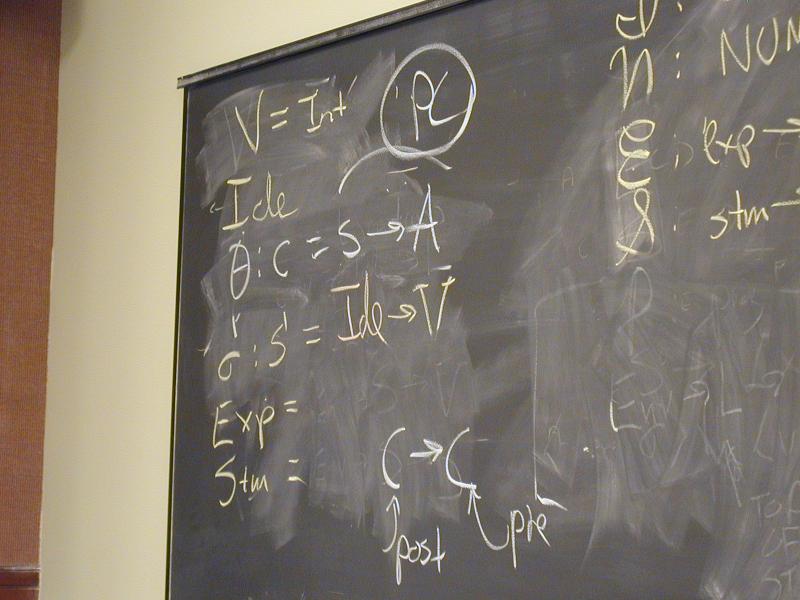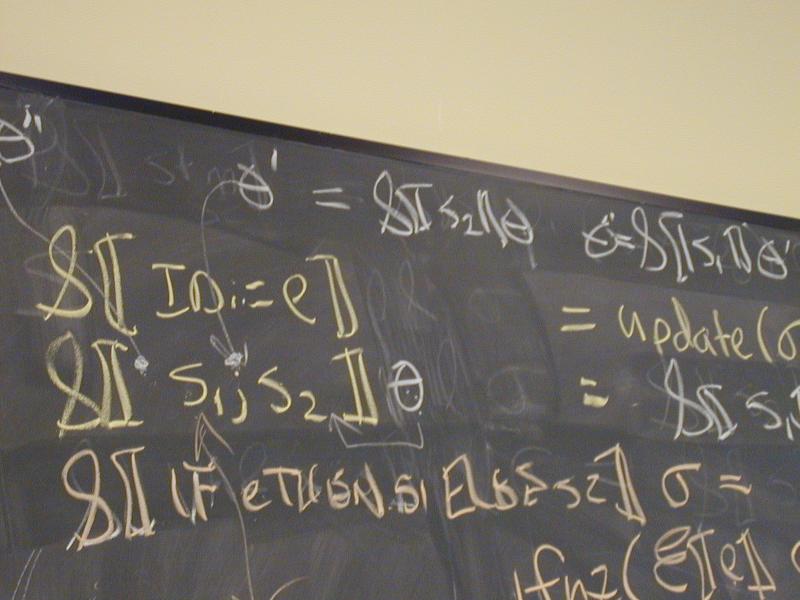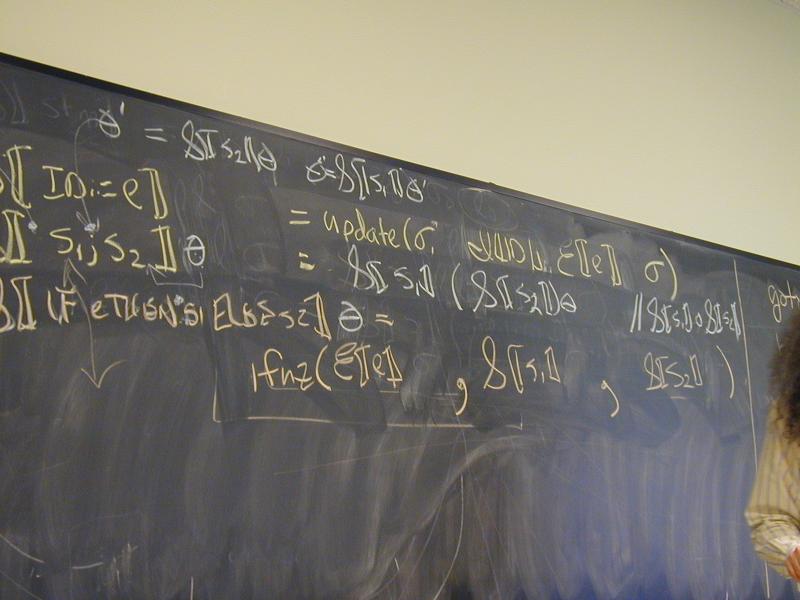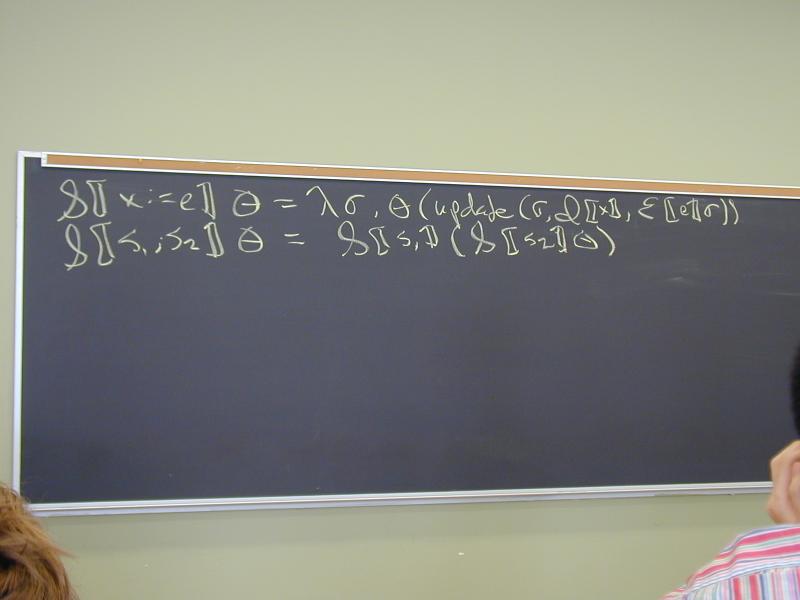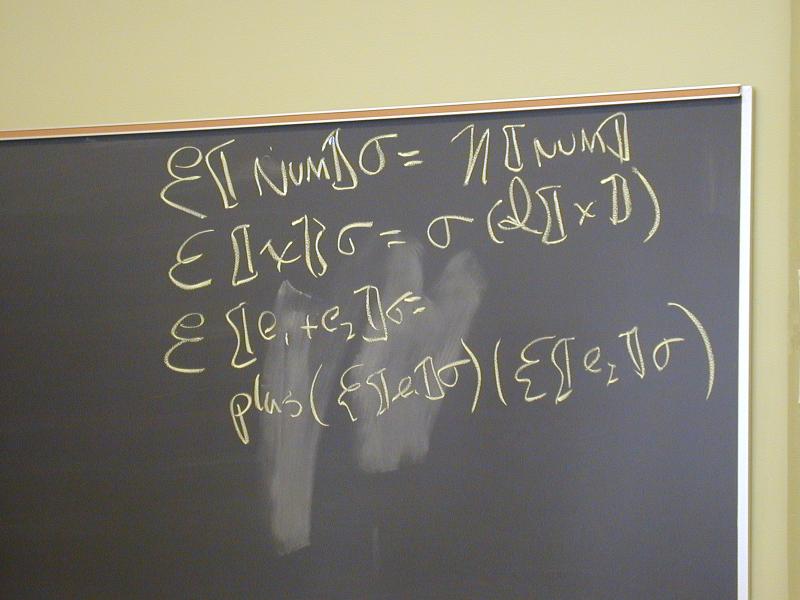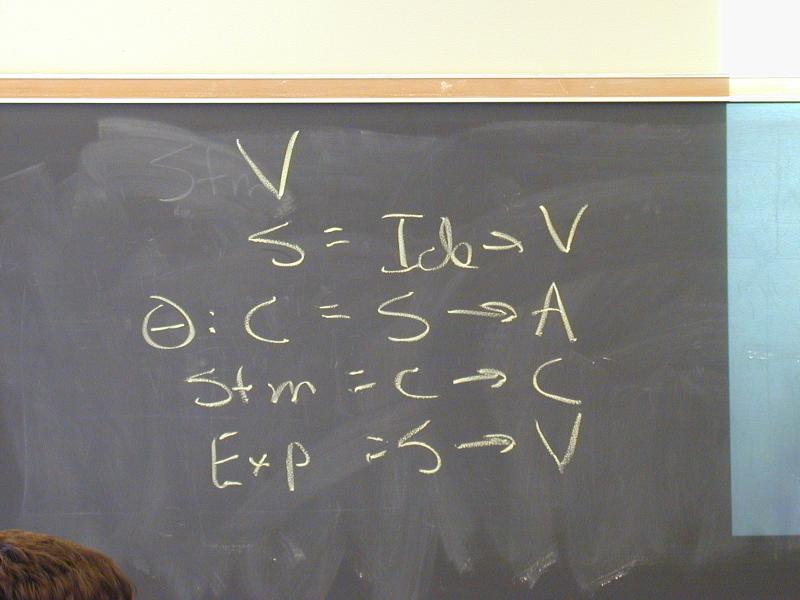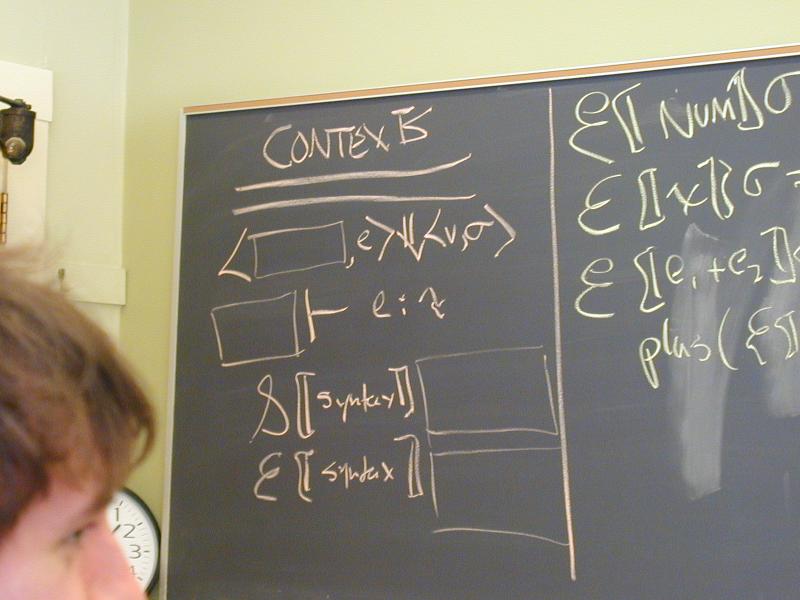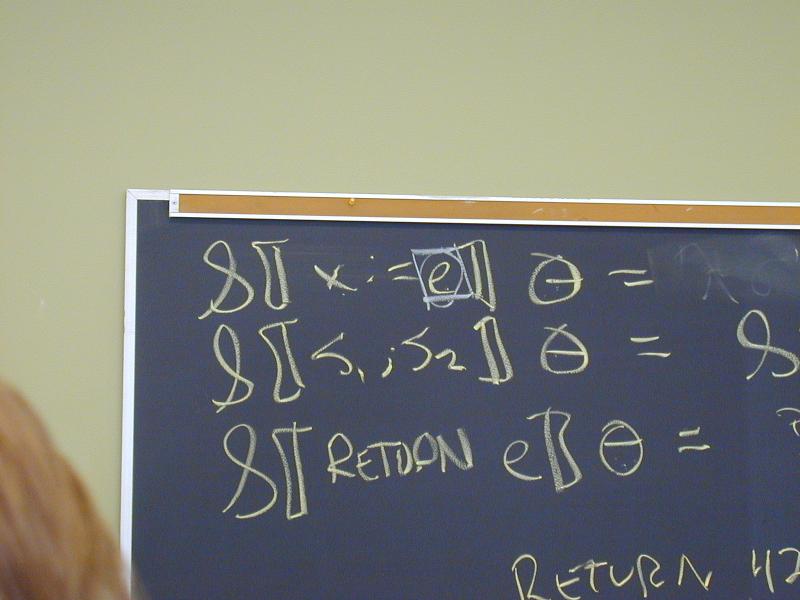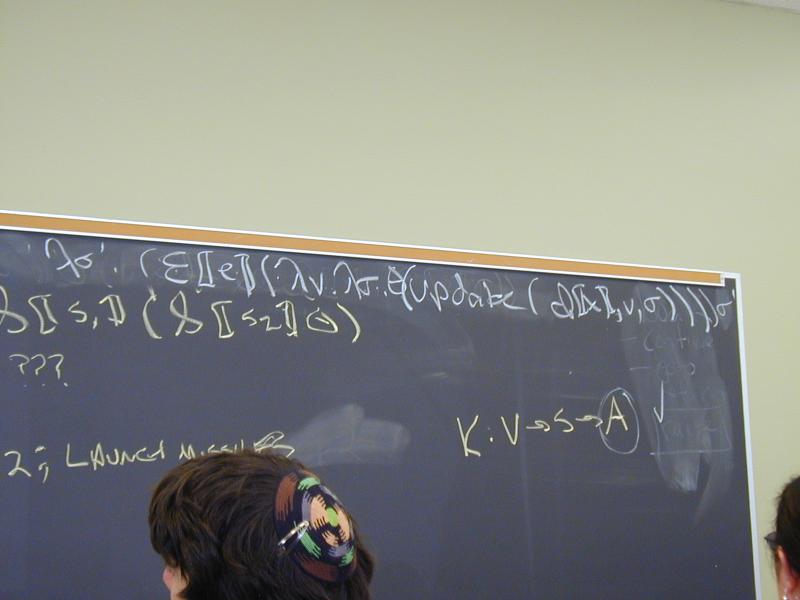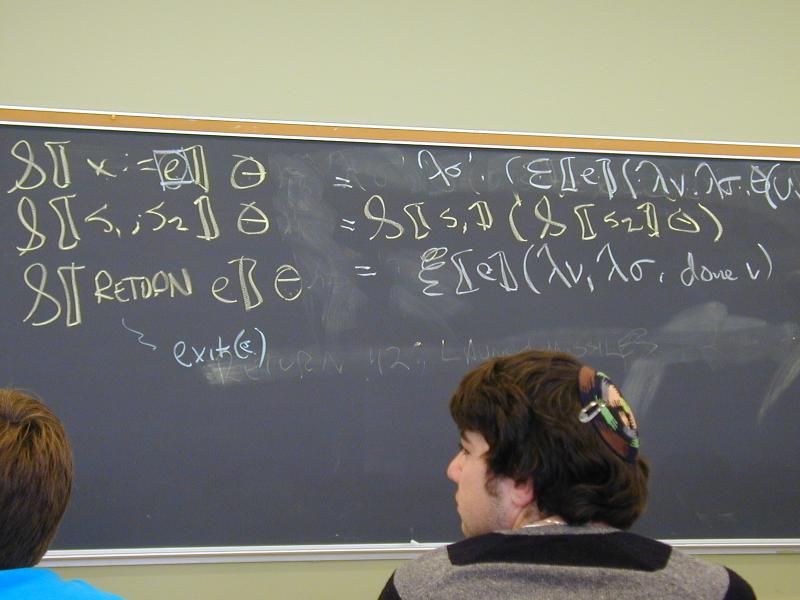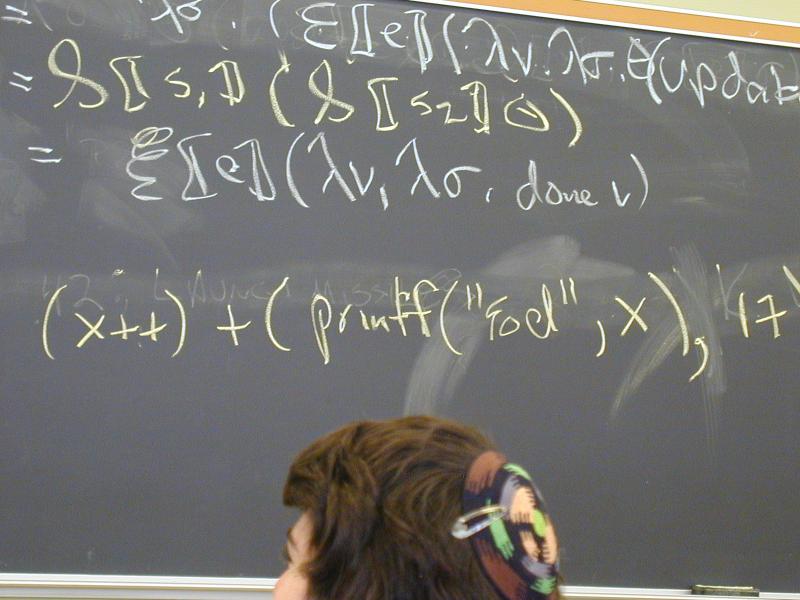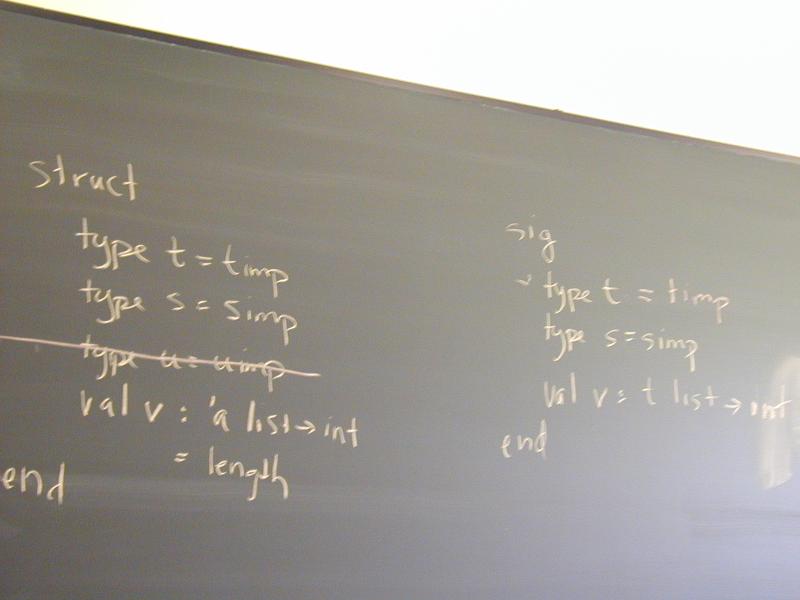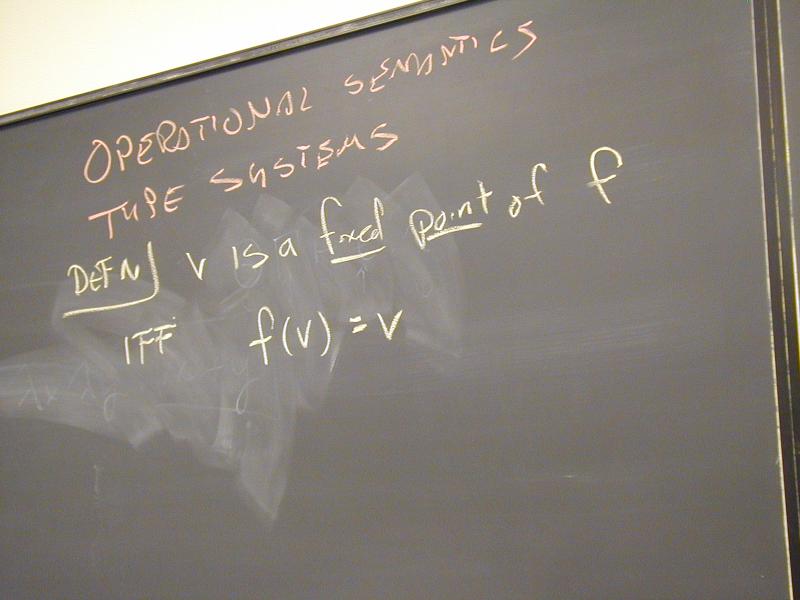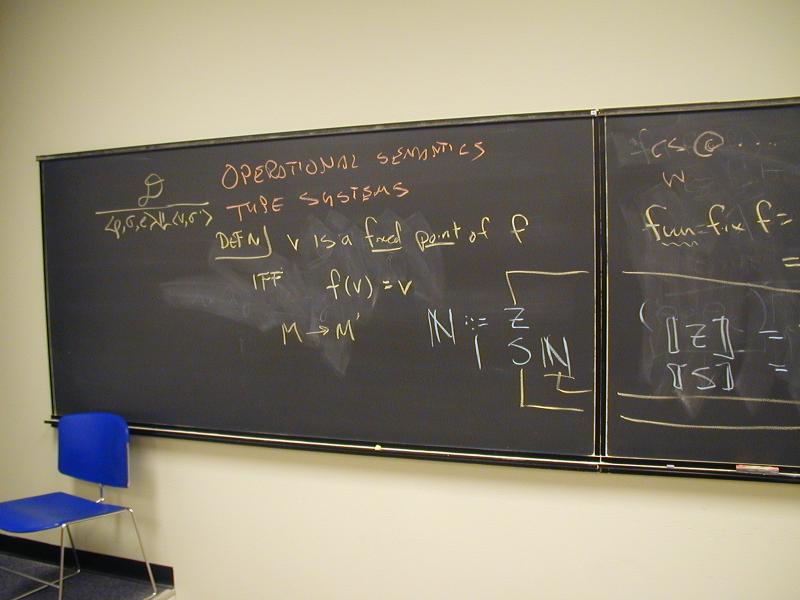Topic of study: the stuff software is made of
- Thousands
- Each one unique
- Why do you suppose so many?
Conclusion: make it easier to write programs that really work
- An invaluable skill for all you software practitioners
Reading: Paul Graham, especially the "Blub Paradox"
In public: a language should express computations
- Precisely
- At a high level
- In a way we can reason about
So, no more uncivilized low-level C, and no more C++ that no mortal being can understand
In the pub: professionals are keenly interested in their code
Your language can make you or break you.
New ways of thinking about programming
Become a sophisticated consumer, aware of old wine in new bottles
Double your productivity
Bonus: preparation for advanced study
Intellectual tools you need to understand, evaluate, and use languages effectively
Notations of the trade (source of precision, further study)
Learn by doing:
- Lots of short programs
- High power-to-weight ratio (lots of thought per line)
(Just as intellectually challenging as COMP 40, but in an entirely different direction.
Whorf's hypothesis applies
There aren't that many great features, and you will see them over and over
You'll choose features, and therefore languages, to fit your needs
Some are more powerful than others
The Blub paradox: habit blinds us to power
You're perfectly happy using Blub.
Would you use Haskell, Lisp, or Icon? No! That's equivalent to Blub, plus weird stuff nobody uses.
Blub looks good enough only if you think in Blub.
In Comp 105,
Only the most powerful features need apply
We explode your brain so you can think differently
You'll know you're doing it right if at first your head hurts terribly, then you have a breakthrough moment and it all seems pleasant afterwards
To say more with less (expressive power):
- First-class functions
- Continuations
- Type inference
- Pattern matching
To promote reliability and reuse:
- Type polymorphism
- Abstract data types
- Modules and "generics"
- Objects and inheritance
Describing it all precisely:
- Operational semantics (daily tool of the trade)
- Denotational semantics (sheer beauty of the ideas, source of much code)
Three lectures per week: 50% more cracks at tough ideas
No cadre of teaching assistants: material is new to everyone except me and Professor Guyer
Instead, small-group section once a week led by Engineering Fellow:
- Mandatory
- Eight students per section
- Every Fellow is a practicing engineer
- Most Fellows work extensively with programming languages
- This is your chance to ask questions, get help, discuss what is going on in small groups
Syllabus and schedule are works in progress:
- Course has to serve everyone from fresh out of 15/22 to grad students
- I want to see how things go
You must get my book
Homework will be frequent and challenging:
- Many small programming problems
- Some theory problems, more like a math problem set
- The occasional larger project, like a type checker or a game solver
- Submit electronically
- Theory is easier to do by hand; scan it and include PDF
Both individual and pair work:
- All problems should be discussed with others
(Essential to your success)
- Discussions must be acknowleged
- Most problems must be completed individually
- Do not allow anyone else to see your code
For some problems larger in scope, you will work in pairs
Be very careful to separate your pair work and your individual work. (Last term in COMP 40, major violation of academic integrity with severe penalties.)
Other policies and procedures in handout and on web - You are responsible!
This topic marries programming and mathematics.
If you're going to enjoy the course,
- You should enjoy programming (15)
- You should also like math (22, sort of---induction and proofs)
- You should be willing to work hard







Goal: make comparisons easy by eliminating superficial differences
- Any differences that remain must be important!
No new language ideas. Instead, imperative programming with an IMPerative CORE:
Idea of LISP syntax:
Two syntactic categories: definitions, expressions (no statements!)
An Impcore program is a sequence of definitions [possible demo here]
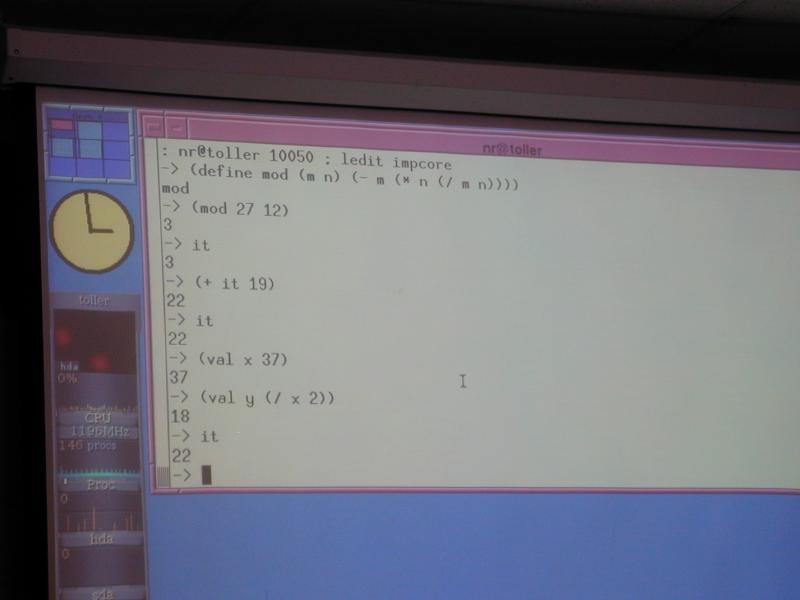
(define mod (m n) (- m (* n (/ m n))))
Compare
int mod (int m, int n) {
return m - n * (m / n);
}
Or
(val n 99)
Compare
int n = 99;
Also, expressions at top level (definition of it)
No statements means expression-oriented:
(if e1 e2 e3)
(while e1 e2)
(set x e)
(begin e1 ... en)
(f e1 ... en)
Each one has a value and may have side effects!
Functions may be primitive (+ - * / = < > print)
or defined with (define f ...).
The only type of data is "machine integer" (deliberate oversimplification)
Scopes also called "names spaces"; we will call them "environments" because that's the pointy-headed theory term---and if you want to read some of the exciting theory papers, pointy-headed theory has to be second nature.
Impcore has 2 levels of environments for variables: globals, formals
There are no local variables
- Just like awk; if you need temps, use extra formal parameters
- For homework, you'll add local variables
Functions live in their own environment (not shared with variables)
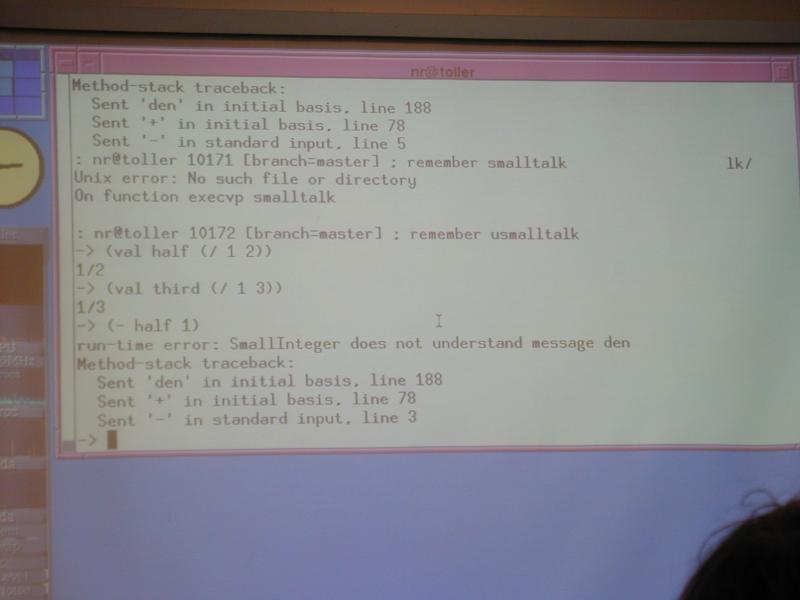
Abuse of separate name spaces: [online demo if possible]
-> (val f 33)
33
-> (define f (x) (+ x x))
f
-> (f f)
66
def ::= (val x exp)
| exp
| (define f (formals) e)
| (use filename)
exp ::= integer-literal
| variable-name
| (set x exp)
| (if exp1 exp2 exp3)
| (while exp1 exp2)
| (begin exp1 ... expn)
| (op exp1 ... expn)
op ::= function-name | primitive-name
Exp = LITERAL (Value)
| VAR (Name)
| SET (Name name, Exp exp)
| IFX (Exp cond, Exp true, Exp false)
| WHILEX (Exp cond, Exp exp)
| BEGIN (Explist)
| APPLY (Name name, Explist actuals)
Notice that there is one kind of "application" for both user-defined and primitive functions.
C code:
typedef struct Exp *Exp;
typedef enum {
LITERAL, VAR, SET, IFX, WHILEX, BEGIN, APPLY
} Expalt; /* which alternative is it? */
struct Exp { // only two fields: 'alt' and 'u'!
Expalt alt;
union {
Value literal;
Name var;
struct { Name name; Exp exp; } set;
struct { Exp cond; Exp true; Exp false; } ifx;
struct { Exp cond; Exp exp; } whilex;
Explist begin;
struct { Name name; Explist actuals; } apply;
} u;
};
Example AST for (f x (* y 3)) (using Explist)
Example Ast for (define abs (x) (if (< x 0) (- 0 x) x)) (using Namelist)
Trick question:
What's the value of (* y 3)? OK, what's its meaning?
Environment associates each variable with one value
Greek letter rho, mapping { x1 |--> n1, ..., xk -> nk }
Environment is a finite map, aka partial function (theorists love functions):
x in dom rho // x is defined in environment rho rho(x) // the value of x in environment rho
First, an abstract type. (For 40 vets: like a Hanson Table_T, only simpler because it's monomorphic.)
typedef struct Valenv *Valenv;
Valenv mkValenv(Namelist vars, Valuelist vals);
int isvalbound(Name name, Valenv env);
Value fetchval(Name name, Valenv env);
void bindval(Name name, Value val, Valenv env);
Implementation uses pair of lists. Consider
(val x 1)
(val y 2)
(val z 3)
Global environment xi says
nl -> z -> y -> x
vl -> 3 -> 2 -> 1
Representing environments efficiently a key challenge for language implementor. (You'll tackle Exercise 18.)
Let's simplify to
exp ::= numeral
| (op exp exp)
op :: + | - | * | /
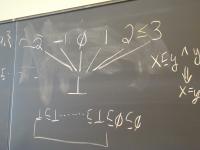
There's no such thing as a "recursive definition." Instead there are only recursion equations and solutions.
Consider
E = Z union { op | e1 in E, e2 in E, op in { +, -, *, / } } / \ e1 e2
What is the intersection of all sets satisfying this equation?
- Every set satisfying the equation contains Z
- So therefore every set contains 3 and 5
- So therefore every set contains (+ 3 5)
- And so it goes
Tricky bit: proving the intersection is not empty
Solution is called an "initial algebra" and we won't go there.
Key fact: in any expression, child expressions are smaller
Therefore, recursive functions on expressions terminate
(provided they make recursive calls on child expressions).
This is called structural recursion.
Structural recursion is the simplest known argument for
a. Writing recursive functions
b. Proving they terminate
An expression is evaluated wrt environment (composition of xi, phi, rho)
In our interpreters, implemented by structural recursion
Base cases:
Questions
syntactic categories and judgement forms
what are the judgment forms?
what's the mathematical interpretation?
what's the operational interpretation?
what's a derivation?
what's a syntactic proof?
what's a metatheoretic proof?
Example: what changes the environment?
- Hypothesis: evaluating an expression that does not contain
set cannot change the contents of the environment
Metatheory gives interesting facts with easy proofs.
What is the inductive definition of the natural numbers?
To discover recursive functions, write algebraic laws:
exp x 0 = 1
exp x (n + 1) = x * (exp x n)
Can you find a direction in which something gets smaller?
Another example:
binary 0 = 0
binary (2n + 1) = binary n .. 1
binary (2n + 0) = binary n .. 0
Right-hand sides in arithmetic?
binary (2n + 1) = 10 * binary n + 1
binary (2n + 0) = 10 * binary n + 0
Which direction gets smaller? What's the code?
Expression, statement, definition, declaration, type
Lots of environments:
- global variables
- functions
- parameters
- local variables?
Typical complexity!
About any language, you can ask these questions:
What is the abstract syntax? What are the syntactic categories, and what are the terms in each category?
What are the values? What do expressions/terms evaluate to?
What environments are there? That is, what can names stand for?
How are terms evaluated? What are the judgments? (What are the rules?)
What's in the initial basis? Primitives and otherwise, what is built in?
Two new kinds of data:
Pointer to automatically managed cons cell (mother of civilization)
The function closure: not just a datum, a feature
(The setting is Scheme)
LISP, circa 1960; Scheme, circa 1975
Applicative programming ('define a function' vs 'write a program')
('evaluate a function' vs 'run a program')
Instead of mutating machine state, just compute with values
requires higher-quality values
Addition by subtraction:
Easier to develop code by case analysis over structure of data
Easier to reason about code (no set -- environments never change)
Powerful tools for composing functions (coming soon)
Syntax (ultimate simple, no operator precedence)
The standard data type is recursive: S-Expressions
The standard control structure is (recursive) function call
Programs as data within the language
Automatic memory management (anything else would be uncivilized)
Values are S-expressions.
Comforting lies:
An S-expression is a symbol or a literal integer or a literal Boolean or a list of S-expressions.
A list of S-expressions is either - the empty list '() - an S-expression followed by a list of S-expressions
Like any other abstract data type
creators create new values of the type
producers make new values from existing values
observers examine values of the type
mutators change values of the type
N.B. creators + producers = constructors
No mutators in uScheme
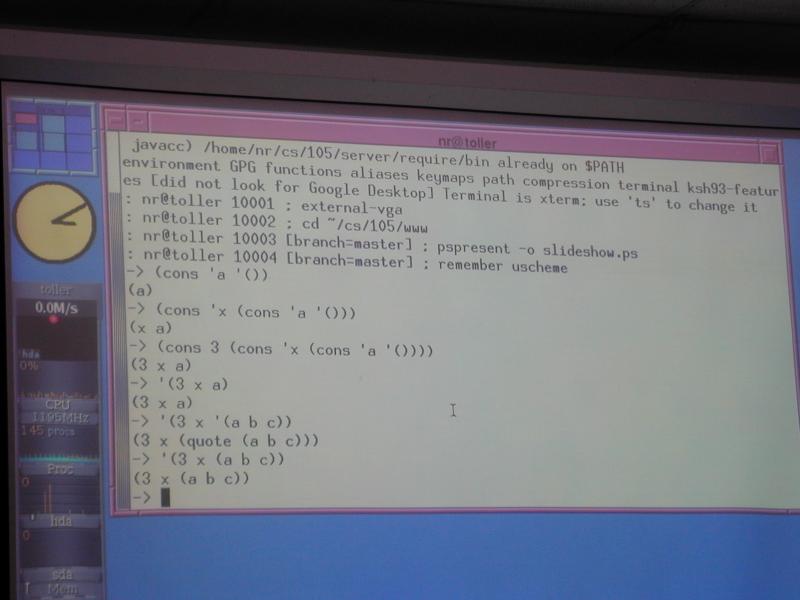
Creators and producers: nil and cons
'()
(cons S' S)
More examples:
(cons 'a '())
(cons 'a '(b))
Note the literal '(b).
Observers: car, cdr, null?, pair? (also known as "first" and "rest", "head" and "tail", and many other names)
Algebraic laws of lists:
(null? '()) == ...
(null? (cons v vs)) == ...
(car (cons v vs)) == ...
(cdr (cons v vs)) == ...
Do these laws hold more generally?
(car (cons e1 e2)) = ...
What about
set (strengthen our metatheorem from Monday: if the program has no set ...)printerrornontermination
More S-expression observers:
number?
symbol?
| symbol literal | symbol? | --- |
| integer literal | number? | --- |
| cons | pair? | car, cdr |
| '() | null? | ---
|
More observers: <, =, >
Equality: number, symbol, Boolean, nil---never cons cells










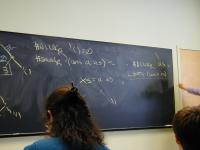


Inductively defined data type: small set satisfying this equation:
Inductive definition of lists:

Any list is therefore constructed with nil or with cons.
- How can you tell the difference?
- What, therefore, is the structure of a function that consumes a list?
Example: length
Polymorphic means "operating on values of many types"
The primitive equal? is polymorphic but returns false on cons cells
It is useful only for comparing atoms
*** Atoms and polymorphic equality ***
(define atom? (x)
(or (number? x)
(or (symbol? x)
(or (boolean? x)
(null? x)))))
(define equal? (s1 s2)
(if (or (atom? s1) (atom? s2))
(= s1 s2)
(and (equal? (car s1) (car s2))
(equal? (cdr s1) (cdr s2)))))
Allocation is the big cost.
Algebraic law for append, by cases, what is xs ys?
'() .. ys == ys
(x .. xs) .. ys == x .. (xs .. ys)
(cons x xs) .. ys = (cons x (xs .. ys))
From there to
*** Equations and function for append ***
(append '() ys) == ys
(append (cons z zs) ys) == (cons z (append zs ys))
(define append (xs ys)
(if (null? xs) ys
(cons (car xs) (append (cdr xs) ys))))
Why does it terminate?
How many cons cells are allocated?
(N.B. You won't find xs in the book; that update missed the print deadline. The book calls a list l, which is not as good.)
Other laws
(append (list1 x) ys) = ???
(if p #t #f) = ???
What about list reversal?
reverse '() = '()
reverse (x .. xs) = reverse xs .. reverse x = reverse xs .. x
And the code?
*** Naive list reversal ***
(define reverse (xs)
(if (null? xs) '()
(append (reverse (cdr xs))
(list1 (car xs)))))
How many cons cells are allocated?
Let's try a new algebraic law:
reverse (x .. xs) .. zs = reverse xs .. x .. zs = reverse xs .. (cons x zs)
reverse '() .. zs = zs
The code
*** Reversal by accumulating parameters ***
(define revapp (xs zs)
(if (null? xs) zs
(revapp (cdr xs) (cons (car xs) zs))))
(define reverse (xs) (revapp xs '()))
Parameter zs is the accumulating parameter.
(A powerful, general technique.)
Implementation: list of key-value pairs
'((k1 v1) (k2 v2) ... (kn vn))
Picture with spine of cons cells, car, cdar, caar, cadar.
*** A-list observer: find ***
(define caar (xs) (car (car xs)))
(define cdar (xs) (cdr (car xs)))
(define cadar (xs) (car (cdar xs)))
(define find (x alist)
(if (null? alist) '()
(if (equal? x (caar alist))
(cadar alist)
(find x (cdr alist)))))
*** A-list producer: bind ***
(define bind (x y alist)
(if (null? alist)
(list1 (list2 x y))
(if (= x (caar alist))
(cons (list2 x y) (cdr alist))
(cons (car alist)
(bind x y (cdr alist))))))
*** A-list example ***
-> (find 'Room '((Course 105) (Room H111A)
(Instructor Ramsey)))
H111A
-> (val nr (bind 'Office 'Extension-006
(bind 'Courses '(105)
(bind 'Email 'comp105-staff '()))))
((Email comp105-staff) (Courses (105)) (Office Extension-006))
-> (find 'Office nr)
Extension-006
-> (find 'Favorite-food nr)
()
Notes:
- attribute can be a list or any other value
- 'nil' stands for 'not found'
*** Laws of assocation lists ***
(find k (bind k v l)) = v
(find k (bind k' v l)) = (find k l), provided k != k'
(find k '()) = '() --- bogus!
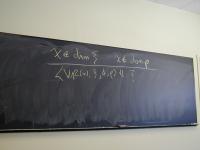






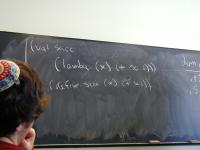
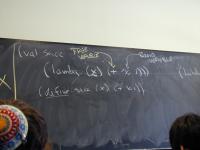




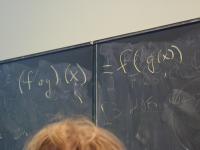

Depth, not breadth.
Today:
- Homework review
- First-class, higher-order functions (definitely)
- Classic higher-order functions that consume lists (probably not)
Notes:
The people upstairs broke clang. I think I fixed it.
If you are only getting started, you are in for a rough week.
Local variables: the two honorable choices
Simplify, simplify, simplify
Accumulating parameters can improve efficiency but are usually less readable.
Delay by snow means Andrew and I just started reading yesterday.
Option: Show your theory work to your section leader.
Metatheory is a powerful, wonderful tool, but you can get by with some soft spots in your understanding.
Important: understand and use operational semantics as a descriptive tool. You must understand this completely.
Example: undeclared variables:
x notin dom xi x notin dom rho
---------------------------------------
<VAR(x), xi, phi, rho> evals < ???? >
*** Introduce local names into environment ***
(let ((x1 e1)
...
(xn en))
e)
Evaluate e1 through en, bind answers to x1, ... xn
- Name intermediate results (simpler code, less error prone)
Creates new environment for local use only:
rho {x1 |-> v1, ..., xn |-> vn}
Also let* (one at a time) and letrec (local recursive functions)
Note that we really have definititions and it might be easier to read if McCarthy had actually used definition syntax, which you'll see in ML, Haskell, and other functional languages:
*** What McCarthy should have done ***
(let ((val x1 e1)
...
(val xn en))
e)
Things that should offend you about Impcore:
Look up function vs look up variable requires different interfaces!
To get a variable, must check 2 or 3 environments.
- Can't create a function without giving it a name:
- High cognitive overhead
- A sign of second-class citizenship
All these problems have one solution: lambda
From Church's lambda-calculus:
(lambda (x) (+ x x))
"The function that maps x to x plus x"
At top level, like define. (Or more accurately, define is a synonym for lambda.)
In general, \x.E or (lambda (x) E)
x is bound in E- other variables are free in
E
The ability to "capture" free variables is what makes it interesting:
(lambda (x) (+ x y)) ; means what??
What matters is that y can be a parameter or let-bound variable of an enclosing functions.
- Can tell at compile time what is captured.
- To understand why anyone cares, you'll need examples
First example:
*** A zero-finder ***
(define findzero-between (f lo hi)
; binary search
(if (>= (+ lo 1) hi)
hi
(let ((mid (/ (+ lo hi) 2)))
(if (< (f mid) 0)
(findzero-between f mid hi)
(findzero-between f lo mid)))))
(define findzero (f) (findzero-between f 0 100))
findzero-between is a higher-order function because it takes another function as an argument. You can do this in C.
*** Function escapes! ***
-> (define to-the-n-minus-k (n k)
(let
((x-to-the-n-minus-k (lambda (x)
(- (exp x n) k))))
x-to-the-n-minus-k))
-> (val x-cubed-minus-27 (to-the-n-minus-k 3 27))
-> (x-cubed-minus-27 2)
-19
to-the-n-minus-k is a higher-order function because it returns another (escaping) function as a result. Much more interesting!
*** No need to name the escaping function ***
-> (define to-the-n-minus-k (n k)
(lambda (x) (- (exp x n) k)))
-> (val x-cubed-minus-27 (to-the-n-minus-k 3 27))
-> (x-cubed-minus-27 2)
-19
*** The cube root of 27 and the square root of 16 ***
-> (findzero (to-the-n-minus-k 3 27))
3
-> (findzero (to-the-n-minus-k 2 16))
4
*** What's an "escaping" function? ***
-> (define to-the-n-minus-k (n k)
(lambda (x) (- (exp x n) k)))
"Escape" means "outlive the activation in which the lambda was evaluated."
Escaping and lifetimes are some of those universal decisions every programmer has to think about.
Where are n and k stored???
- Values that escape have to be allocate on the heap
C programmers do this explicitly with malloc
In a language with first-class, nested functions, part of the semantics of lambda
Closures:

Operational semantics of closures:

Preview: in math, what is the following equal to?
(f o g)(x) == ???
Another algebraic law, another function:
*** Functions create new functions ***
-> (define o (f g) (lambda (x) (f (g x))))
-> (define even? (n) (= 0 (mod n 2)))
-> (val odd? (o not even?))
-> (odd? 3)
-> (odd? 4)
Imposing your will on S-expressions
Board:
LIST(A) = UNIT u A * LIST(A)
ALIST(K, V) = LIST( { (list2 k v) | k in K, v in V } )
Not every S-expression is a list:

Rose trees ($k$-ary trees):

Board:
ROSE(A) = A u LIST(ROSE(a))
Your job:
Figure out the recursion pattern that goes with ROSE trees.
For problem 20 and problem T, don't wait for continuations
(figure out now what is the inductive definition of an algebraic formula)
Write formula?. Write satisfies?.
On your own:
- Section 3.3.6
- Section 3.9.1
Q: What can you do if you write a function that consumes a function?
A: apply it!
You can't mutate or modify a function, but you can create as many new ones as you like:
*** SLIDE ***
-> (define o (f g) (lambda (x) (f (g x))))
*** Classic functional technique: Currying ***
-> (val positive? (lambda (y) (< 0 y)))
-> (positive? 3)
-> (val <-curried (lambda (x) (lambda (y) (< x y))))
-> (val positive? (<-curried 0)) ; "partial application"
-> (positive? 0)
No need to Curry by hand!:
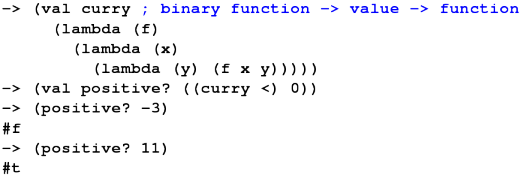
What's the algebraic law for curry?
... (curry f) ... = ... f ...
Keeping in mind all you can do with a function is apply it?
*** Bonus content: vulnerable variables? ***
-> (val seed 1)
-> (val rand (lambda ()
(set seed (mod (+ (* seed 9) 5) 1024)))))
-> (rand)
14
-> (rand)
131
-> (set seed 1)
1
-> (rand)
14
*** Bonus: Lambda as abstraction barrier! ***
-> (val mk-rand (lambda (seed)
(lambda ()
(set seed (mod (+ (* seed 9) 5) 1024))))))
-> (val rand (mk-rand 1))
-> (rand)
14
-> (rand)
131
-> (set seed 1)
error: set unbound variable seed
-> (rand)
160
Capture common patterns of computation
exists?, all? (is there a number?)filter (take only the numbers?)map (add 1 to every element)- foldr (general)
Folds also called reduce, accum, "catamorphism"
Algebraic law:
(exists? p? '()) == ???
(exixts? p? '(cons a as)) == ???
*** SLIDE ***
-> (define exists? (p? xs)
(if (null? xs)
(if (p? (car xs))
(exists? p? (cdr xs)))))
-> (exists? pair? '(1 2 3))
-> (exists? pair? '(1 2 (3)))
-> (exists? ((curry =) 0) '(1 2 3))
-> (exists? ((curry =) 0) '(0 1 2 3))
Problem: Give me a list of numbers; return only the even elements.
What are the laws?
(filter even? '()) == ???
(filter even? '(cons a as)) == ???
(filter even? '(cons a as)) == ???
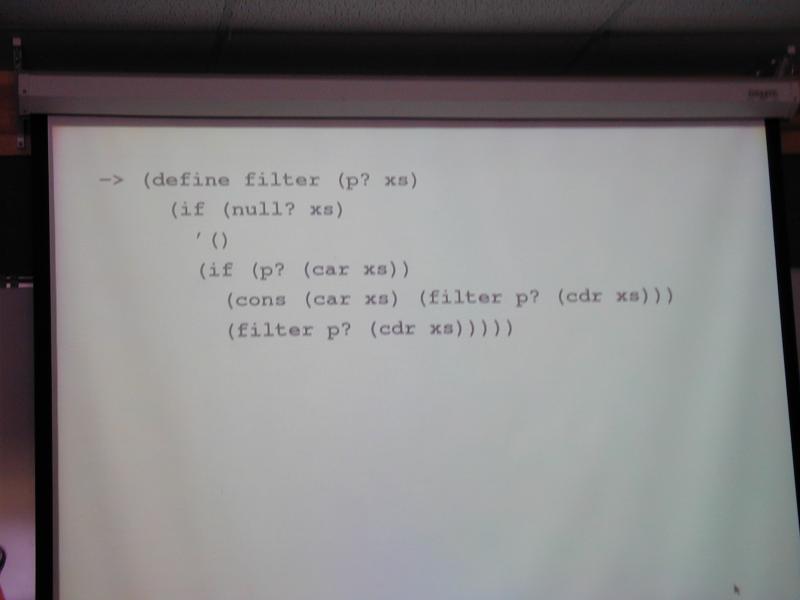
*** SLIDE ***
-> (define filter (p? xs)
(if (null? xs)
'()
(if (p? (car xs))
(cons (car xs) (filter p? (cdr xs)))
(filter p? (cdr xs)))))
-> (filter (lambda (n) (> n 0)) '(1 2 -3 -4 5 6))
(1 2 5 6)
-> (filter (lambda (n) (<= n 0)) '(1 2 -3 -4 5 6))
(-3 -4)
-> (filter ((curry <) 0) '(1 2 -3 -4 5 6))
(1 2 5 6)
-> (filter ((curry >=) 0) '(1 2 -3 -4 5 6))
(-3 -4)
*** List filtering: composition revisited ***
-> (val positive? ((curry <) 0))
<procedure>
-> (filter positive? '(1 2 -3 -4 5 6))
(1 2 5 6)
-> (filter (o not positive?) '(1 2 -3 -4 5 6))
(-3 -4)
Problem: square every element of a list.
What are the laws?
(map square '()) ==
(map square (cons a as)) ==
*** SLIDE ***
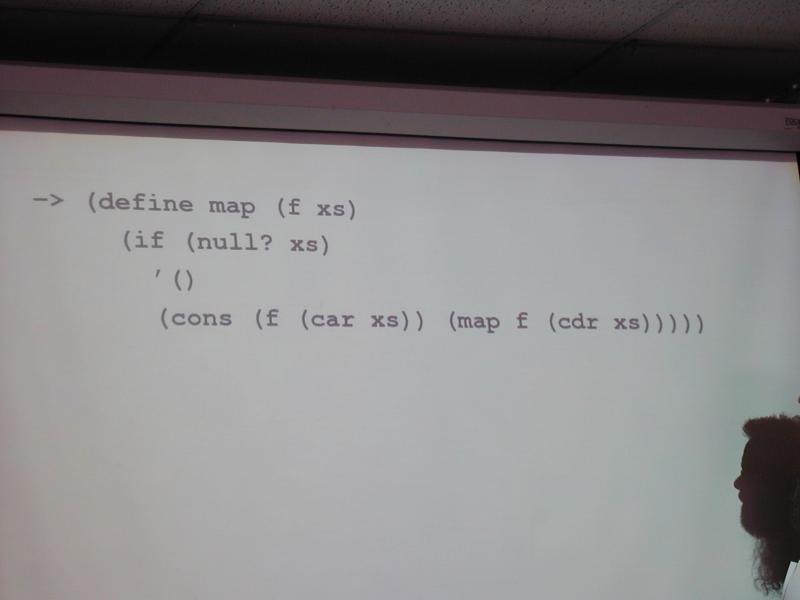
-> (define map (f xs)
(if (null? xs)
'()
(cons (f (car xs)) (map f (cdr xs)))))
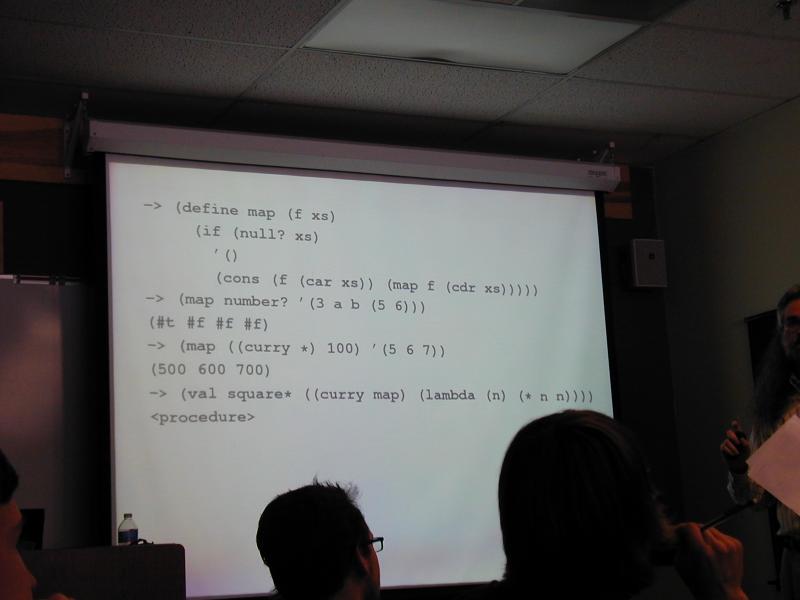
-> (map number? '(3 a b (5 6)))
(#t #f #f #f)
-> (map ((curry *) 100) '(5 6 7))
(500 600 700)
-> (val square* ((curry map) (lambda (n) (* n n))))
<procedure>
-> (square* '(1 2 3 4 5))
(1 4 9 16 25)

Another view of operator folding:

foldr is a catamorphism
- Any recursively defined data type has one!
Another catamorphism: foldl associates to left
*** Existence, by laws ***
(exists? p? '()) == #f
(exists? p? '(cons a as)) == (p? a) \/ (exists p? as)
*** Filter, by laws ***
(filter p? '()) == '()
(filter p? '(cons a as)) == (cons a (filter p? as)),
if (p? a)
(filter p? '(cons a as)) == (filter p? as),
otherwise
*** Filter, by code ***
-> (define filter (p? xs)
(if (null? xs)
'()
(if (p? (car xs))
(cons (car xs) (filter p? (cdr xs)))
(filter p? (cdr xs)))))
-> (filter ((curry <) 0) '(1 2 -3 -4 5 6))
(1 2 5 6)
-> (filter ((curry >=) 0) '(1 2 -3 -4 5 6))
(-3 -4)
What have we got:
- Predicates and lists
- Search for an element of a list
- Keep a sublist
What we haven't got:
- Functions that return something more general than yes or no
Problem: square every element of a list.
What are the laws?
(map square '()) ==
(map square (cons a as)) ==
*** SLIDE ***
-> (define map (f xs)
(if (null? xs)
'()
(cons (f (car xs)) (map f (cdr xs)))))
-> (map number? '(3 a b (5 6)))
(#t #f #f #f)
-> (map ((curry *) 100) '(5 6 7))
(500 600 700)
-> (val square* ((curry map) (lambda (n) (* n n))))
<procedure>
-> (square* '(1 2 3 4 5))
(1 4 9 16 25)

* SLIDE* -> (define foldr (plus zero xs) (if (null? xs) zero (plus (car xs) (foldr plus zero (cdr xs))))) -> (val sum (lambda (xs) (foldr + 0 xs))) -> (val prod (lambda (xs) (foldr * 1 xs))) -> (sum '(1 2 3 4)) 10 -> (prod '(1 2 3 4)) 24
Another view of operator folding:
foldr is a catamorphism
- Any recursively defined data type has one!
Another catamorphism: foldl associates to left
Direct style - last action is to return a value
Continuation-passing style - last action is to "throw" value to a continuation
- Not like a call (it never returns)
- Think "goto with arguments"
Simulate with an ordinary tail call.
How functions finish:

Problem in interface design:
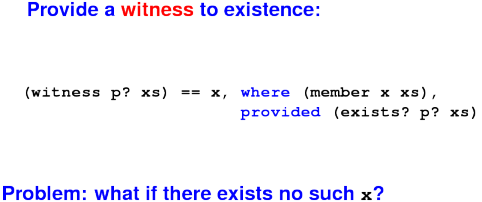
Ideas?
Bad choices:
- nil
- special symbol
'fail
- run-time error
Good choice:
- exception (not in uScheme)
Solution: new interface:

*** Coding \lit{witness} with continuations ***
(define witness-cps (p? xs succ fail)
(if (null? xs)
(fail)
(let ((x (car xs)))
(if (p? x)
(succ x)
(witness-cps p? (cdr xs) succ fail)))))
Example use: instructor lookup:

*** Simple continuations at work ***
-> (val 2011s '((Ramsey 105)(Hescott 170)(Chow 116)))
-> (instructor-info 'Ramsey 2011s)
(Ramsey teaches 105)
-> (instructor-info 'Chow 2011s)
(Chow teaches 116)
-> (instructor-info 'Souvaine 2011s)
(Souvaine is-not-on-the-list)
Crucial question:

Review: CPS as an interface:
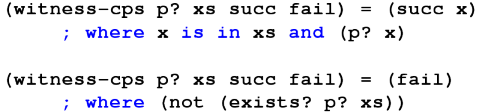
Writing code in CPS:

{Continuations for search problems}:

Concluding remark (board): functions are cheap
- Macros!
- Cond expressions (solve nesting problem)
- Mutation
- Garbage collection
- Tail calls
- Applications and assessment
A Scheme program is just another S-expression
- Define functions that manipulate them at compile time
- Macro hygiene ensures macro parameters don't interfere with program variables
- Used to implement
and, let, others...
*** Real Scheme Conditionals ***
(cond (c1 e1) ; if c1 then e1
(c2 e2) ; else if c2 then e2
... ...
(cn en) ; else if cn then en
; Syntactic sugar---'if' is a macro:
(if e1 e2 e3) == (cond (e1 e2)
(#t e3))
A call in tail position.
What is tail position?
Tail position is defined inductively:
- The body of a function is in tail position
- When
(if e1 e2 e3) is in tail position, so are e2 and e3
- When
(let (...) e) is in tail position, so is e, and similary for letrec and let*.
- When
(begin e1 ... en) is in tail position, so is en.
Anything in tail position is the last thing executed!
Key idea is tail-call optimization!
Tail-call optimization:

Example of tail position:

Example of tail position:

Question: how much stack space is used by the call?
Another example of tail position:
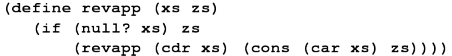
Another example of tail position:
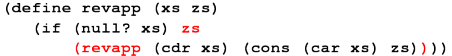
Question: how much stack space is used by the call?
A third example of tail position:
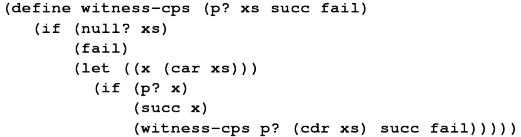
A third example of tail position:
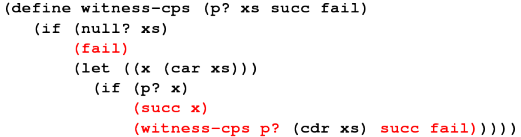
Question: how much stack space is used by the call?
Question: in your previous life, what did you call a construct that
- Transfers control to an arbitrary point in the code?
- Uses no stack space?
Common Lisp, Scheme:
- Big environments, tiny interpreters, everything between
- High-level data structures
- Cheap, easy recursion
- Automatic memory management (garbage collection!)
- Programs as data!
- Sophisticated Interactive Development Environments
Down sides:
- Hard to talk about data
- Hard to detect errors at compile time
Bottom line: it's all about lambda
- Major win
- Real implementation cost (heap allocation)
Problems A and 12 (the strange let binding): making your head explode, creating room for new knowledge
Problem 1: understanding the structure of data and the recursion patterns that go with it (preparation for the solver)
Problems 5 and 6: mastering higher-order functions
Problem 13 (characteristic functions): understanding lambda
Problem B (quicksort): putting it all together in an application
Problems 20 and T (formula solver): inductive data types, continuation-passing style
Problems 26 and 35: more practice with semantics and implementation
Apply your new knowlwedge in Standard ML:
- You've already learned the ideas
- There will be a lot of new detail
Much less intellectual effort
Meta: Not your typical introduction to a new language
- Not definition before use, as in a manual
- Not tutorial, as in Ullman
- Instead, the most important ideas that are most connected to your work up to now
ML Overview
Designed for programs, logic, symbolic data
Apples to Oranges: uScheme in ML
- double C functionality, half the code
- general parser framework (six languages)
- detects more errors
Theme: talking about data
Board: ML = uScheme + pattern matching + exceptions + static types
Three new ideas:
- Pattern matching is big and important. You will like it.
- Exceptions are easy
- Static types get two to three weeks in their own right.
And lots of new concrete syntax!
ML---The Five Questions
Syntax: expressions, definitions, patterns, types
Values: num/string/bool, record/tuple, \rlap{\high{algebraic data}}
Environments: names stand for values (and types)
Evaluation: uScheme + case and pattern matching
Initial Basis: medium size; emphasizes lists
\medskip
(Question Six: type system---a coming attraction)
A note about books
Ullman is easy to digest
Ullman is clueless about good style
Suggestion:
- Learn the syntax from Ullman
- Learn style from Ramsey
(My style is not flawless---some Haskell style has crept in---but it will serve you better than Ullman. And I've made some effort at consistency.)
Tidbits:
The most important idea in ML!
Originated with Hope (Burstall, MacQueen, Sannella), in the same lab as ML, at the same time (Edinburgh!)
(Wikipedia article among the worst ever.)
Board:
A "Boolean" is produced using true or false
A "list of A" is produced using nil or a :: as, where a is an A and as is a "list of A"
A "Rose tree of A" is produced using a A or a list of rose trees of A
*** SLIDE ***
datatype bool = true | false (* copy me NOT! *)
datatype 'a list = nil (* copy me NOT! ) | op :: of 'a 'a list
datatype 'a srose = LEAF of 'a | INTERNAL of 'a srose list
type bool val true : bool type 'a list val false : bool type 'a srose val nil : forall 'a . 'a list val op :: : forall 'a . 'a * 'a list -> 'a list val LEAF : forall 'a . 'a -> 'a srose val INTERNAL : forall 'a . 'a srose list -> 'a srose
Exegesis (on board):
Notation 'a is a type variable
- On left-hand side, it is a formal type parameter
- On right-hand side it is an ordinary type
- In both cases it represents a single unknown type
Name before = introduces a new type constructor into the type environment. Type constructors may be nullary.
Alternatives separated by bars are value constructors of the type
They are new and hide previous names
(Do not hide built-in names list and bool from the initial basis!)
Value constructors participate in pattern matching (coming)
Complete by themselves: true, false, nil
Expect parameters to make a value or pattern: ::, LEAF, INTERNAL
op enables an infix operator to appear in a nonfix context
Type application is postfix
- On last line,
'a srose is the type parameter to list
New names into two environments:
bool, list, srose stand for new type constructors
true, false, nil, ::, LEAF, INTERNAL stand for new value constructors
Algebraic datatypes are inherently inductive (list appears in its own definition)---to you, that means finite trees
'a * 'a list is a pair type --- infix operators are always applied to pairs
*** Syntactic sugar for lists ***
- 1 :: 2 :: 3 :: 4 :: nil; (* :: associates to the right *)
> val it = [1, 2, 3, 4] : int list
- INTERNAL (LEAF 1 :: INTERNAL (LEAF 2 :: LEAF 3 :: nil) ::
LEAF 4 :: nil);
> val it = INTERNAL [LEAF 1, INTERNAL [LEAF 2, LEAF 3],
LEAF 4] : int srose
Consuming algebraic types
New language construct case (an expression)
fun length xs =
case xs
of [] => 0
| (x::xs) => 1 + length xs
Exegesis:
fun is close to define- Note syntactic sugar for
nil
- Function application by juxtaposition -- shed your parentheses
- As noted,
+ is an infix identifier
case is checked by the compiler:
- but
case is still no fun!
Types and their uses:
| Type | Produce | Consume |
| Introduce | eliminate |
| arrow | Lambda (fn) | Application |
| algebraic | Apply constructor | Pattern match |
| tuple | (e1, ..., en) | Pattern match! |
Consuming algebraic types---better
Case analysis in definition
fun length [] = 0
| length (x::xs) = 1 + length xs
(Very close to an algebraic law.)
This is the standard.
Harper: my students don't believe...
*** Type of a function consuming lists ***
- map;
> val ('a, 'b) it = fn : ('a -> 'b) -> 'a list -> 'b list
(* means this:
val map: forall 'a, 'b . ('a -> 'b) -> ('a list -> 'b list)
^^^^^^^^^^^^^^^
*)
Milner left out the forall. A tragic mistake ("language you need a PhD to use").
And the arrow type associates to the right
*** Code for a function consuming lists ***
fun map f [] = []
| map f (x::xs) = f x :: map f xs
(* FUNCTION APPLICATION HAS HIGHER
PRECEDENCE THAN ANY INFIX OPERATOR! *)
*** SLIDE ***
val filter : forall 'a . ('a -> bool) ->
'a list -> 'a list
fun filter p [] = []
| filter p (x::xs) =
case p x
of true => x :: filter p xs
| false => filter p xs
fun filter p [] = []
| filter p (x::xs) = (* 'if' better than 'case' *)
if p x then x :: filter p xs
else filter p xs
Exercise --- write
val flatten : forall 'a . 'a srose -> 'a list
where
datatype 'a srose
= LEAF of 'a
| INTERNAL of 'a srose list
*** SLIDE ***
fun flatten (LEAF a) = [a]
| flatten (INTERNAL ts) = (List.concat o map flatten) ts
fun flatten (LEAF a) = [a]
| flatten (INTERNAL ts) = List.concat (map flatten ts)
fun flatten t =
let fun flatapp (LEAF a, tail) = a :: tail
| flatapp (INTERNAL ts, tail) =
foldr flatapp tail ts
in flatapp (t, [])
end
























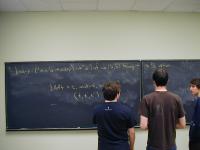


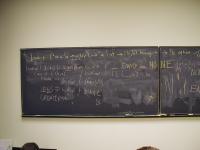



Board:
curry flip infixr 0 $ optmap
uncurry fst
snd
Basic values and expression
Infix arithmetic with "high minus"
~3 + 3 = 0
String concatenation: concat, infix hat ^
Short-circuit andalso, orelse for Booleans
Strings "as in C and C++"
Characters #"a", #"b", ...
' marks a type variable or is "prime"
Identifiers
Formation rules:
- Alphanumerics, underscore
_, prime '
- Symbols
+-/*<>=!@#$%^&~\|?: (and `)
in any combination
- Start with
'? You're a type variable
Fixity:
infixr 5 @ (* associativity, precedence *)
Revert using op
*** Lists and fixity ***
- [+, -, *, div];
! Toplevel input:
! [+, -, *, div];
! ^
! Ill-formed infix expression
- [op +, op -, op *, op div];
> val it = [fn, fn, fn, fn] : (int * int -> int) list
- length it;
> val it = 4 : int
-
The value environment:

Beware the semicolon!
Interactive R-E-P-L uses semicolons
Never put a semicolon in a file
(Did I mention Ullman was clueless?)
Nesting environments
At top level, definitions
Definitions contain expressions:
def ::= val ident = exp
Expressions contain definitions:
exp ::= let defs in exp end
Sequence of defs has let-star semantics
Structured values and terms: lists:

Structured values and terms: tuples:
Function pecularities: lambda
Lambda is spelled fn:\normalsize
val rec factorial =
fn n => if n = 0 then 1 else n * fact (n-1)
Function pecularities: 1 argument
Each function takes 1 argument, returns 1 result
For "multiple arguments," use tuples!\normalsize
fun factorial n =
let fun f (i, prod) =
if i > n then prod else f (i+1, i*prod)
in f (1, 1)
end
fun factorial n = (* you can also Curry *)
let fun f i prod =
if i > n then prod else f (i+1) (i*prod)
in f 1 1
end
Tuples are "usual and customary."
Mutual recursion:

Pattern-matching in definitions
def ::= val pattern = exp
Example:
val (pivot, left, right) = split xs
Function definition:
def ::= fun ident patterns = exp
{| ident patterns = exp }
Cases must be exhaustive! (Overlap discouraged)
What is a pattern?
pattern ::= variable
| wildcard
| value-constructor [pattern]
| tuple-pattern
| record-pattern
| integer-literal
| list-pattern
Design bug: no lexical distinction between
- VALUE CONSTRUCTORS
- variables
Workaround: programming convention
Pattern-matching example:

Type examples:

Values and types:

Syntax of ML types:

Syntax of ML types:

Polymorphic types:

Old and new friends:

Board:
Syntax:
raise E where E : exn- Example:
exception EmptyQueue
Semantics:
- alternative to normal termination
- can happen to any expression
- tied to function call
- if evaluation of body raises exn, call raises exn
Handler uses pattern matching
e handle pat1 => e1 | pat2 => e2
*** Exception handling in action ***
loop (evaldef (reader (), rho, echo)) handle EOF => finish () | Div => continue "Division by zero" | Overflow => continue "Arith overflow" | RuntimeError msg => continue ("error: " ^ msg) | IO.Io {name, ...} => continue ("I/O error: " ^ name) | SyntaxError msg => continue ("error: " ^ msg) | NotFound n => continue (n ^ "not found")
Gotcha - Value polymorphism:

*** Gotcha --- overloading ***
- fun plus x y = x + y;
> val plus = fn : int -> int -> int
- fun plus x y = y + y : real;
> val plus = fn : real -> real -> real
Gotcha --- equality types:

Gotcha --- parentheses
Put parentheses around anything with |
case, handle, fn
Function application has higher precedence than any infix operator
To run Moscow ML:
ledit mosml -P full
And tell it:
help "";
use "warmup.sml";
Also /usr/bin/sml, /usr/bin/mlton
[N.B. "Static" means "at compile time"]
Why have a static type system?
Why are we learning about types?
- By knowing the types of names, patterns, and contexts, you narrow your code down to just a few choices. Whether it's case analysis or function application, **the type system guides you to the right code.
But why are we learning this theory stuff?
- Source of new language ideas for next 20 years
- Needed if you want to understand advanced designs (or create your own)
- Startling applications (the Kathleen Fisher story)
Two flavors:
- Monomorphic (easy to compile, restrictive, poor reuse)
- Polymorpyic (harder to compile, freedom, great reuse)
What is a type?
As a working definition, a set of values
As a precise definition, a classifier for terms!!
- Note: a computation can have a type even if it never produces a value!
Examples: types
These are types:
intboolint * boolint * int -> int
Board: little language of types
- "Type-level expressions"
- Usually just called "types"
(Very confusing---as if "expressions" were called "values")
Examples: not really types
These "types in waiting" don't classify any terms
list (but int list is a type)array (but char array is a type)ref (but (int -> int) ref is a type)
These are utter nonsense
Type constructors
Technical name for "types in waiting"
Zero or more args, produce type
- Nullary
int, bool, char also called base types
- Unary
list, array, ref
- Binary (infix)
->
More complex type constructors:
- records/structs
- function in C, uSchueme, Impcore
Rules for constructors:

Connecting types to values:
Type soundness:
Types help programmers
What do I write next?
- What types of values do I have?
- What type of value am I trying to produce?
- What are the types of the available functions?
Plan:
- Two new languages: Typed Impcore and Typed uScheme
- Both languages in book and homework
- In lecture, just use Typed uScheme
- Begin with a monomorphic fragment
Typical syntactic support for types
Explicit types on lambda and define:
For lambda, argument types:\normalsize
(lambda ((int n) (int m)) (+ (* n n) (* m m)))
For define, argument and result types:
(define int max ((int x) (int y)) (if (< x y) y x))
Abstract syntax: \small
datatype exp = ...
| LAMBDA of (name * tyex) list * exp
...
datatype def = ...
| DEFINE of name * tyex * ((name * tyex) list * exp)
...
Type checking:

Monomorphic types are limiting
Each new type constructor requires
- Special syntax
- New type rules
- New internal representation (type formation)
- New code in type checker (intro, elim)
- Do another proof of soundness
Monomorphic burden: Array types:

Notes:
- *Implementing arrays on homework
- Writing rules for lists on homework
Monomorphism hurts programmers too
Users can't create new syntax
User-defined functions are monomorphic:\normalsize
(define int lengthI ((list int) l)
(if (null? l) 0 (+ 1 (lengthI (cdr l)))))
(define int lengthB ((list bool) l)
(if (null? l) 0 (+ 1 (lengthB (cdr l)))))
(define int lengthS ((list sym) l)
(if (null? l) 0 (+ 1 (lengthS (cdr l)))))
Quantified types:

*** Substitute for quantified variables ***
-> length
<proc> : (forall ('a) (function ((list 'a)) int))
-> (@ length int)
<proc> : (function ((list int)) int)
-> (length '(1 2 3))
type error: function is polymorphic; instantiate before applying
-> ((@ length int) '(1 2 3))
3 : int
*** Substitute what you like ***
-> length
<proc> : (forall ('a) (function ((list 'a)) int))
-> (@ length bool)
<proc> : (function ((list bool)) int)
-> ((@ length bool) '(#t #f))
2 : int
*** More "Instantiations" ***
-> (val length-int (@ length int))
length-int : (function ((list int)) int)
-> (val cons-bool (@ cons bool))
cons-bool : (function (bool (list bool))
(list bool))
-> (val cdr-sym (@ cdr sym))
cdr-sym : (function ((list sym)) (list sym))
-> (val empty-int (@ '() int))
() : (list int)
Bonus instantiation:
-> map
<proc> :
(forall ('a 'b)
(function ((function ('a) 'b)
(list 'a))
(list 'b)))
-> (@ map int bool)
<proc> : (function ((function (int) bool)
(list int))
(list bool))
Create your own!
Abstract over unknown type using type-lambda
-> (val id (type-lambda ('a)
(lambda (('a x)) x)))
id : (forall ('a) (function ('a) 'a))
\large 'a is type parameter (an unknown type)
This feature is parametric polymorphism
Board: two forms of abstraction:
| term | type |
| `lambda` | `function` (arrow) |
| `type-lambda` | `forall` |
Power comes at notational cost
Function composition
-> (val o (type-lambda ('a 'b 'c)
(lambda (((function ('b) 'c) f)
((function ('a) 'b) g))
(lambda (('a x)) (f (g x))))))
o : (forall ('a 'b 'c)
(function ((function ('b) 'c)
(function ('a) 'b))
(function ('a) 'c)))
Aka \black o : \mbox{$\forall \alpha, \beta, \gamma \mathrel. (\beta \arrow \gamma) \cross (\alpha \arrow \beta) \arrow (\alpha \arrow \gamma) $}
Instantiate by substitution:

Generalize with type-lambda:















Midterm evaluations (board --- participation grade)
Typed uScheme policy reversal
Fresh issue of extension tokens to total 7
(blots!)
Also length considered harmful
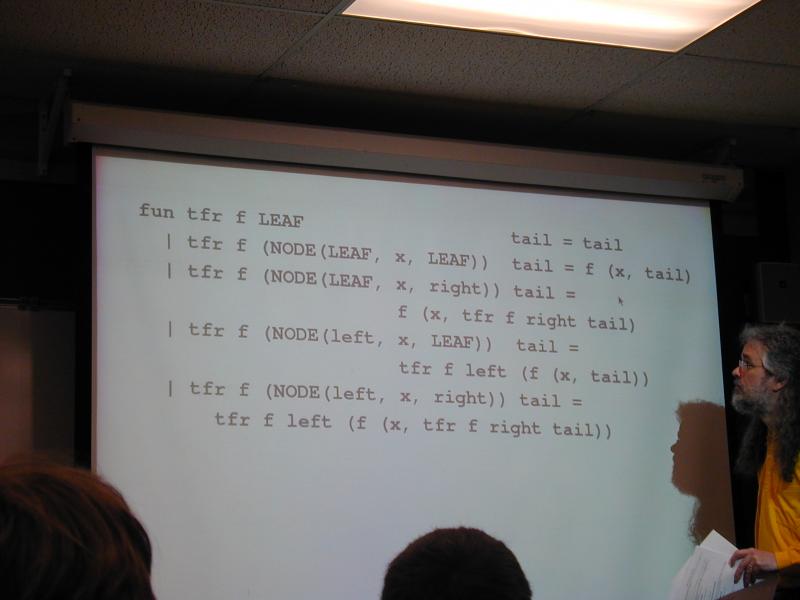
*** SLIDE ***
datatype 'a tree
= NODE of 'a tree * 'a * 'a tree
| LEAF
*** SLIDE ***
fun tfr f LEAF tail = tail
| tfr f (NODE(LEAF, x, LEAF)) tail = f (x, tail)
| tfr f (NODE(LEAF, x, right)) tail =
f (x, tfr f right tail)
| tfr f (NODE(left, x, LEAF)) tail =
tfr f left (f (x, tail))
| tfr f (NODE(left, x, right)) tail =
tfr f left (f (x, tfr f right tail))
*** SLIDE ***
fun length (nil) = 0
| length (x::xs) =
foldr (fn (_, n) => n + 1) 0 (x::xs)
From a monomorphic language to a polymorphic language:
bs - Instantiate by substitution $\forall$ elimination:
begin{center} \trule {\ptypeis e {\forall\ldotsn\alpha.\tau}} {\ptypeis {\xtyapply(e, \ldotsn\tau)} {\tau[\ldotsmapston \alpha \tau]}} \end{center} es
Generalize with type-lambda:
Arrow-introduction, corrected {\&} compared:

*** Working up to type inference ***
-> (define double (x) (+ x x))
double ;; uScheme
-> (define int double ((int x)) (+ x x))
double : (function (int) int) ;; Typed uSch.
-> (define double (x) (+ x x))
double : int -> int ;; uML
*** Infer a polymorphic type ***
-> (lambda (f) ;; uScheme
(lambda (x) (f (f x))))
<procedure>
-> (type-lambda ('a) ;; Typed uScheme
(lambda (((function ('a) 'a) f))
(lambda (('a x)) (f (f x)))))
<procedure> : (forall ('a)
(function ((function ('a) 'a)) (function ('a) 'a)))
-> (lambda (f) ;; uML
(lambda (x) (f (f x))))
<procedure> : forall 'a . ('a -> 'a) -> ('a -> 'a)
- fn f => fn x => f (f x); ;; Moscow ML
> val 'a it = fn : ('a -> 'a) -> 'a -> 'a
The Hindley-Milner type system
Restricted polymorphism:
- $\forall$ only at outermost level
- Function argument is always a monotype, never a quantified type
Advantage: no notation
- Type abstraction implicit at
let/val binding
- Polytypes instantiated automatically at use
ML to Typed uScheme:
val id = fn x => x
becomes
(val id (type-lambda ('a) (lambda (('a x)) x)))
Term
3 :: []
becomes
((@ cons int) 3 (@ '() int))
Representing Hindley-Milner types:

*** Type schemes in codeland ***
datatype ty
= TYVAR of name
| TYCON of name
| CONAPP of ty * ty list
datatype type_scheme
= FORALL of name list * ty
Key ideas:

Key ideas repeated:

{ML type rules can be nondeterministic!}:

{ML type rules, continued}:
{Things to notice}:

{Type inference}:

{Instances and substitution}:

{Instance properties}:

{Instantiation intuition}:

{More instantiation}:

What is theory and why is it important:
Precise answer to what does this program mean
Guides implementors and programmers
Elements of theory
- operational semantics
- lambda calculus
- type systems
- partial orders and lattices
- denotational semantics
World's simplest language
exp ::= var | \var.exp | exp exp
Also typically written as
M,N ::= x | \x.M | M N
Application associates to the left and binds tighter than abstraction
(Equivalent: body of lambda-term extends to the closing right paren)
Lambda is as powerful as any language known
Ideal for
- proving theorems
- experimenting with features
- describing other languages
Abstract syntax: application, abstraction, variable
Values: no values! Values are just terms
- Typically terms in normal form
- That's why it's a "calculus"
Environments: not used! (But names stand for terms)
Evaluation rules: coming
Initial basis: often add constants like + or 2
New kind of semantics: small-step
New judgment form
M --> N ("M reduces to N in one step")
No context!! No turnstile!!
Just pushing terms around == calculus
{Reduction rules}:

Example reduction to normal form:
(\x.\y.yx)(+ 3 4)(\x.+ x 2) -> (beta)
(\y.y(+ 3 4))(\x.+ x 2) -> (beta)
(\x.+ x 2)(+ 3 4) -> (beta)
+(+ 3 4)2
This is a normal form. If we have rules for constants, we can go further (to 9)
The substitution in the beta rule is the heart of the lambda calculus
- It's hard to get right
- It's a stupid design for real programming (shell, tex, tcl)
- It's even hard for theorists!
- But it's the simplest known thing
Free variables:
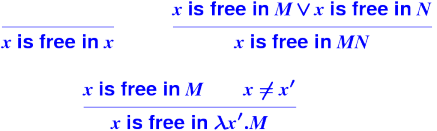
Examples of free variables:
\x . + x y
\x. \y. x
Substitution:


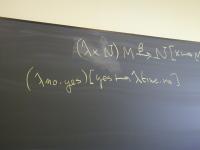
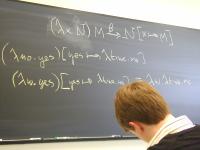









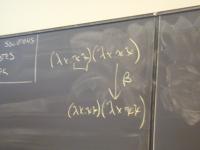
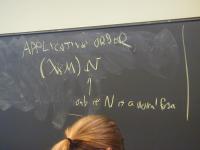
Over 20 pages of feedback
Focus on quick improvements
- Too fast on slides
- What do I know about what you know?
- Please help me help you---ask questions!
Substitution:
Example:
(\yes.\no.yes)(\time.no) ->
\z.\time.no
and never
\no.\time.no // WRONG!!!!!!
{Renaming of bound variables}:

Conversion:

Nondeterminism of conversion:
A
/ \
V V
B C
Now what??
Church-Rosser Theorem:
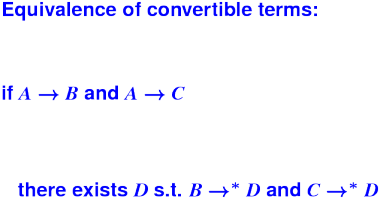
Given a beta-redex
(\x.M) N
do the beta-reduction only if N is in normal form
- Good model for ML and Scheme, so-called "call by value" languages
- Think "arguments before bodies"
Q: Does applicative order ever prevent you from making progress?
A: No. We can prove it by induction on the number of lambdas in N
Always choose leftmost, outermost redex
- Normalization theorem: if a normal form exists, this will find it
"Normal-order" stands for produces a normal form, not for "the normal way of doing things"
Normal-order illustration:

Not your typical call-by-value semantics!
Anybody remember propositions, logic, tautologies?
| Logic | PL |
| Propositions | Types |
| Proofs | Terms |
Basis of many modern theorem provers
- Primarily in safety-critical software, especially aerospace
Logical formulas:
A -> B -> A
A -> B -> B
A /\ B -> A
A /\ B -> B
A -> A \/ B
B -> A \/ B
Types:
A -> B -> A
A -> B -> B
A * B -> A
A * B -> B
A -> A + B
B -> A + B
What terms have these types?
Is
A -> B
a tautology?
Q: What term could possibly have that type?
A: Type soundness guarantees that if it terminates, it's good
A: So, a term that doesn't terminate
Q: How would you represent a pair, using only functions?
Followup: given a pair, what can a function do
A: continuation-passing style
Q: So then what function type might represent A * B
A: forall C . (A -> B -> C) -> C
Followup: does (forall C . (A -> B -> C) -> C) -> A?
A: Yes; substitute A for C and ((A -> B -> A) -> A) -> A
Followup: a term of that type?
A: \f. f (\a.\b.a)
Agenda: code a simple functional language, like Scheme, using lambda calculus.
Idea: continuation-passing style
if M then N else P ===> M N P
M chooses N or P based on truth or falsehood?
Q: How are true and false coded??
A: \x.\y.x and \x.\y.y
Q: What is the capability of a pair?
A: To access both elements
Q: Then what does the continuation look like?
A: Takes both elements and produces an answer
Q: How do we represent the pair (M, N)?
A: \k. k M N
Q: What does the pair function look like?
A: `pair = \x.\y.\f.f x y
Q: How do we implement fst and snd?
A: fst = \p.p(\x.\y.x)
A: snd = \p.p(\x.\y.y)
Q: What is the capability of a pair?
A: To access either one element or the other
Q: How many continuations should a sum expect?
A: Two
Q: What does a continuation look like?
A: Takes one element and produces an answer
Q: How do we represent the value (LEFT M)
A: \f.\g. f M
Q: How do we represent the value (RIGHT N)
A: \f.\g. g N
Q: So what do the LEFT and RIGHT functions look like?
A: left = \a.\f.\g.f a
A: right = \b.\f.\g.g b
Q: How do we do case analysis?
A: Our old friend either!
case X of LEFT a => M | RIGHT b => N
either X (\a.M) (\b.N)
either s f g = s f g
Simulating S-expressions:

datatype bool = true | false
datatype 'a heap = EMPTY | HEAP of 'a heap * 'a * 'a heap
datatype 'a seq = ESEQ | SINGLE of 'a | APPEND of 'a seq * 'a seq
What are the Church encodings of the following?
true
false
EMPTY
HEAP
ESEQ
SINGLE
APPEND
Natural numbers as functions:

Church Numerals:

*** Church Numerals to machine integers ***
-> (define to-int (n)
((n ((curry +) 1)) 0))
-> (to-int three)
3
-> (to-int ((times three) four))
12
*** Church Numerals in $\lambda$ ***
zero = \f.\x.x;
succ = \n.\f.\x.f (n f x);
plus = \n.\m.n succ m;
times = \n.\m.n (plus m) zero;
...
-> four;
\f.\x.f (f (f (f x)))
-> three;
\f.\x.f (f (f x))
-> times four three;
\f.\x.f (f (f (f (f (f (f (f (f (f (f (f x)))))))))))
Typed lambda is a simplified version of Typed uScheme:
M ::= x
| \x:tau . M
| M N
| /\'a . M
| M [tau] // instantiation
| constant
tau ::= mu // type constructor
| 'a // type variable
| forall 'a . tau
| tau tau
There is also a simply-typed lambda calculus without type-lambda, instantiation, or quantified types.
Church numerals in a typed calculus:

Lambda calculus is just pushing terms around
Operational semantics is just executing some automaton
How do we justify calling it "functional programming?" Where are the functions????
Functions are mathematical objects
Denotational semantics says what mathematical object corresponds to
- An expression (like a lambda term)
- A statement
- A program
A function is a value.
If values are V, then V must include V -> V.
What is V -> V? It can't be all functions from V to V
- Cantor's diagonal argument
But wait! There are only countably many source codes!
Intuition: include only those functions whose behavior is required by the source code










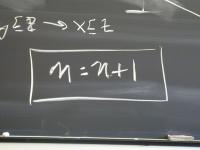




Two heroes here:
Dana Scott figured out which mathematical functions (and other objects) are denoted by computer programs. He described semantic domains; you'll get a taste of domain theory.
Christopher Strachey related it to language by syntax-directed definitions which are compositional
Scott's ideas underly classical compiler optimizations based on dataflow analysis. Plus they apply to all recursion equations
Strachey's ideas are used in every compiler and interpreter.
(N.B. First book ever written on these topics was written by Joe Stoy.)
Our goals (board):
Understand how recursion equations are solved by the fixed-point method
Learn to compute fixed points using the method of successive approximations
Write definitional interpreters in Strachey's style, try out some simple control operators
Avoid "junk" values, including non-computable functions
- Identify class of well-behaved functions
Deal with nontermination through a bottom element
Solve recursion equations with fixed points
- No such thing as a "recursive definition"
Bottom element
Partial order approximation
- "at least as defined as"
- "terminates at least as often as"
Functions in semantic domains are not "over-defined"
Partial order review:
- reflexive
- transitive
- antisymmetric
- incomparable elements are possible
Examples:
set inclustion
approximation on partial functions
- f <= g iff f and g agree where both are defined, and g is defined everywhere that f is defined
instance relation on types
trivial partial order for flat domains (Int, Bool)
Complete partial order or CPO
The "least" upper bound makes the fewest assumptions
Given a cpo S, what's the semantic domain of functions from S to S?
- Make them all total (use | where not otherwise defined)
Lift approximation to functions pointwise:
Refinement ordering on functions:

Well-behaved functions:

Bonuses:
- The total, monotonic, continuous functions form a CPO
- Recursion is now bought and paid for
Recursion = Fixed point:
Monotonic, continous $g$ has fixed point:

Fixed-point construction:

What do I want from you?
- Translate between recursion equations and fixed points
- Remember the fixed-point construction
Fixed points in (untyped) lambda:
Fixed points work on domains:
This evening, my friends and I discovered that we had a hard time answering a question on the assignment because we had no way to frame what it meant to "write the function whose fixed point is a solution to the equation".
Write a function f such that if (f ys = ys) then
ys = (cons 0 (map ((curry +) 1) ys)))
Could you produce a different, dissimilar recursion equation and use the steps listed on the assignment to solve it? I think such an example would be helpful.
Equation
p = pair 0 (fst p)
Function:
f = \p.pair 0 (fst p)
zero approximation:
p0 = _|_
p1 = f p0 = pair 0 (fst _|_) = pair 0 _|_
p2 = f p1 = pair 0 (fst (pair 0 _|_)) = pair 0 0
p3 = f p2 = pair 0 (fst (pair 0 0)) = pair 0 0
p2 is the least fixed point of function f and the least defined solution to the recursion equation.
Direct-style value semantics for a stratified language with statements and expression.
Domains: (board)
V = Int
Ide
sigma : S = Ide -> V
Exp = S -> V
Stm = S -> S
Notes:
- Direct style because we map states to states
- States map identifiers directly to values (like Impcore), no locations
Semantic functions on base types and on syntax:
I : ID -> Ide
N : NUM -> V
E : exp -> Exp
S : stm -> Stm
Semantic functions for values and store
plus : V -> V -> V
update : S * Ide * V -> S
Abstract syntax and semantic equations for statements:
S [[ID := exp]] sigma = update(sigma, I[[ID]], E[[exp]]sigma)
S [[s1; s2]] sigma = S[[s2]](S[[s1]] sigma)
Abstract syntax and semantic equations for expressions:
E [[NUM]] sigma = N[[NUM]] // note state is ignored
E [[ID]] sigma = sigma(I[[ID]])
E [[e1 + e2]] sigma = plus (E [[e1]] sigma) (E [[e2]] sigma)
Things to notice:
- Evaluating an expression doesn't change state.
- Name semantics is exactly like Impcore
- No side condition on domain: all functions are total
- Semantic functions are strict (preserve undefinedness
_|_)

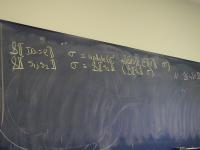
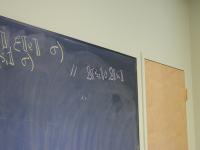

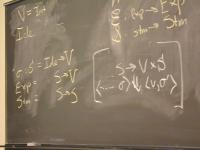
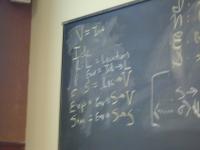

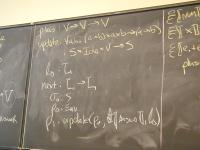
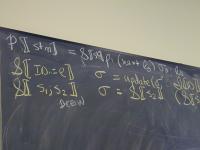
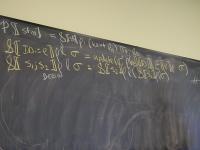
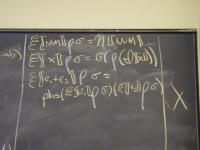


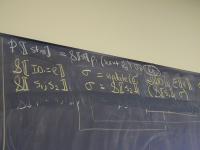
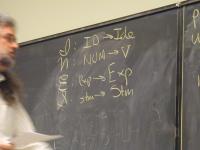
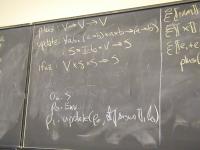
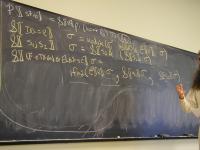

Today's plan:
- Design choices, quickly and easily
- Continuations
- Definitional interpreters
DON'T FORGET JOE STOY'S TALK TOMORROW, 3PM
Ideas:
- mutable locations
- result stored in variable
Answer
Domains: (board)
V = Int
Ide
l : L = Locations // new
rho : Env = Ide -> L // new
sigma : S = L -> V // changed
Exp = Env -> S -> V // changed
Stm = Env -> L -> S -> S // changed
Notes:
- Still direct style, but a location semantics
Semantic functions for base types and syntax
I : ID -> Ide
N : NUM -> V
E : exp -> Exp
S : stm -> Stm
P : prog -> Env -> L -> S -> L -> V
^ ^
| +-- location where answer is stored
|
+--- location for next local variable
Semantic functions for values, environment, and store
plus : V -> V -> V
update_S : S * L * V -> S
update_E : Env * Ide * L -> Env
New functions:
l0 : L // location supply
next : L -> L
sigma0 : S // initial state
rho0 : Env // initial env
rho1 : Env = update_E(rho0, I [[Answer]], l0)
Abstract syntax and semantic equations for programs:
P [[s]] = S [[s] rho_1 (next l0) sigma0 l0
Abstract syntax and semantic equations for statements:
S [[ID := exp]] rho l sigma = update_S(sigma, rho(I[[ID]]), E[[exp]] rho sigma)
S [[{ VAR x ; s }]] rho l sigma =
S [[s]](update_E(rho, I[[x]], l))(next l) sigma
S [[s1; s2]] rho l sigma = S[[s2]] rho l (S[[s1]] rho l sigma)
Abstract syntax and semantic equations for expressions:
E [[NUM]] rho sigma = N[[NUM]] // note state is ignored
E [[ID]] rho sigma = sigma(rho(I[[ID]]))
E [[e1 + e2]] rho sigma = plus (E [[e1]] rho sigma) (E [[e2]] rho sigma)
Things to notice:
??????
Ideas:
- to simplify, drop locations
- structured control flow
- states computed "front to back"
Domains: (board)
V = Int
Ide
sigma : S = Ide -> V // changed
Exp = S -> V // changed
Stm = S -> S // changed
Semantic functions for base types and syntax
I : ID -> Ide
N : NUM -> V
E : exp -> Exp
S : stm -> Stm
Semantic functions for values, environment, and store
plus : V -> V -> V
update : S * L * V -> S
ifnz : V * S * S -> S
Abstract syntax and semantic equations for statements:
S [[ID := exp]] sigma = update(sigma, I[[ID]], E[[exp]] sigma)
S [[s1; s2]] sigma = S[[s2]] (S[[s1]] sigma)
S [[IF exp THEN s1 ELSE s2]] sigma =
ifnz(E[[exp]]sigma, S[[s1]] sigma, S[[s2]]sigma)
S [[WHILE exp DO stm]] sigma =
Y(\f.\sigma.ifnz(E[[exp]]sigma,f(S[[stm]]sigma),sigma)) sigma
S [[skip]] sigma = sigma
Abstract syntax and semantic equations for expressions:
E [[NUM]] sigma = N[[NUM]] // note state is ignored
E [[ID]] sigma = sigma(I[[ID]])
E [[e1 + e2]] sigma = plus (E [[e1]] sigma) (E [[e2]] sigma)
Things to notice:
??????
Ideas:
- answers A
- continuation = S -> A "start program in a given state, run to completion"
- builds "back to front"
- Tell me what happens after me, and I'll tell you what happens before me
Why are we doing this?
- Name a language construct whose behavior is independent of "what happens after me".
We want to model those constructs.
Domains: (board)
V = Int
Ide
sigma : S = Ide -> V
A = Answers // new
theta : C = S -> A // new
Exp = S -> V // same
Stm = C -> C // changed
Prog = A // by definition, the answer you get when
// you run it (e.g., stdout, stderr, exit code)
Semantic functions for base types and syntax
I : ID -> Ide
N : NUM -> V
E : exp -> Exp
S : stm -> Stm
P : prog -> Prog
Semantic functions for values, environment, and store
plus : V -> V -> V
update : S * L * V -> S
ifnz : V * S * S -> S
done : C // end of the program
Abstract syntax and semantic equations for a program:
P[[stm]] = S[[stm]] done sigma_0
Abstract syntax and semantic equations for statements:
S [[ID := exp]] theta = \sigma.theta(update(sigma, I[[ID]], E[[exp]] sigma))
S [[s1; s2]] theta = S[[s1]] (S[[s2]] theta) // order restored!
S [[IF exp THEN s1 ELSE s2]] theta =
\sigma.ifnz(E[[exp]]sigma, S[[s1]] theta sigma, S[[s2]]theta sigma)
Abstract syntax and semantic equations for expressions:
E [[NUM]] sigma = N[[NUM]] // note state is ignored
E [[ID]] sigma = sigma(I[[ID]])
E [[e1 + e2]] sigma = plus (E [[e1]] sigma) (E [[e2]] sigma)
Things to notice:
- Continuation can be ignored. What sorts of commands ignore their continu



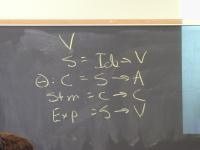

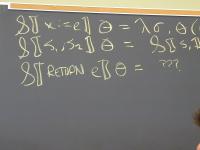

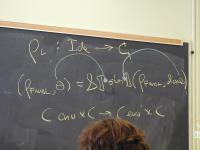

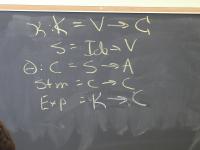

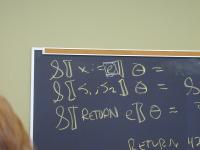
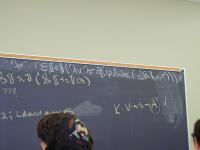
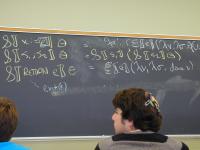

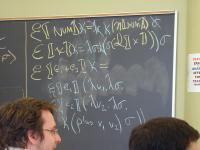





Context: operational, type theory, denotational
Gotos and labels: Important recursion equation
rho_final, theta = S[[stm]] (rho_final, done)
where
Stm = C env * C -> C env * C
Domains: (board)
V = Int
Ide
sigma : S = Ide -> V
A = Answers // new
theta : C = S -> A // new
Exp = S -> V // same
Stm = C -> C // changed
Prog = A // by definition, the answer you get when
// you run it (e.g., stdout, stderr, exit code)
Semantic functions for base types and syntax
I : ID -> Ide
N : NUM -> V
E : exp -> Exp
S : stm -> Stm
P : prog -> Prog
Semantic functions for values, environment, and store
plus : V -> V -> V
update : S * L * V -> S
ifnz : V * S * S -> S
done : C // end of the program
Abstract syntax and semantic equations for a program:
P[[stm]] = S[[stm]] done sigma_0
Abstract syntax and semantic equations for statements:
S [[ID := exp]] theta = \sigma.theta(update(sigma, I[[ID]], E[[exp]] sigma))
S [[s1; s2]] theta = S[[s1]] (S[[s2]] theta) // order restored!
S [[IF exp THEN s1 ELSE s2]] theta =
\sigma.ifnz(E[[exp]]sigma, S[[s1]] theta sigma, S[[s2]]theta sigma)
Abstract syntax and semantic equations for expressions:
E [[NUM]] sigma = N[[NUM]] // note state is ignored
E [[ID]] sigma = sigma(I[[ID]])
E [[e1 + e2]] sigma = plus (E [[e1]] sigma) (E [[e2]] sigma)
Things to notice:
- Continuation can be ignored. What sorts of commands ignore their continu
Ideas:
What if evaluating an expression can raise an exception or cause another control-flow event?
Expression appears in a context, which
- Expects a value
- Continues execution
Domains: (board)
V = Int
Ide
sigma : S = Ide -> V
A = Answers
theta : C = S -> A
kappa : K = V -> C // new
Exp = K -> C // changed
Stm = C -> C // same
Prog = A // same
Semantic functions for base types and syntax
I : ID -> Ide
N : NUM -> V
E : exp -> Exp
S : stm -> Stm
P : prog -> Prog
Semantic functions for values, environment, and store
plus : V -> V -> V
update : S * L * V -> S
ifnz : V * A * A -> A // changed
done : C // end of the program
error : A // an error answer
Abstract syntax and semantic equations for a program:
P[[stm]] = S[[stm]] (\sigma.error) sigma_0
Abstract syntax and semantic equations for statements:
S [[ID := exp]] theta = E[[exp]](\v.\sigma.theta(update(sigma, I[[ID]], v)))
S [[RETURN exp]] theta = E[[exp]](\v.\sigma.done v) // ignores theta!!
S [[s1; s2]] theta = S[[s1]] (S[[s2]] theta) // unchanged
Abstract syntax and semantic equations for expressions:
E [[NUM]] kappa = kappa(N[[NUM]]) // feed value to context
E [[ID]] kappa = \sigma.kappa(sigma(I[[ID]]))sigma // lookup and continue
E [[e1 + e2]] kappa = // must make contexts for e1 and e2
E[[e1]](\v1.E[[e1]](\v2.kappa (plus v1 v2)))
E [[stm; exp]] kappa = S[[stm]](E[[exp]]kappa) // bonus construct!
Things to notice:
- Continuation can be ignored! (By RETURN statement)
Definitional interpreter!
*** ML domains ***
type V = int
type Ide = string
type S = Ide -> V
datatype A = ERROR
| ANSWER of V (* value returned *)
type C = S -> A
type K = V -> C
type Exp = K -> C
type Stm = C -> C
*** Starting values ***
exception NotFound
val plus : V * V -> V = op +
val upd : S * Ide * V -> S
= fn (sigma, n, v) => fn n' =>
if n = n' then v else sigma n'
val done : V -> A = fn x => ANSWER x
val sigma0 : S = fn n => raise NotFound
*** Syntax of programs ***
datatype prog = PROG of stm
and stm = op := of Ide * exp
| RETURN of exp
| SEQs of stm * stm
and exp = SEQe of stm * exp
| NUM of V
| ID of Ide
| op + of exp * exp
*** Semantic equations, part I ***
fun P (PROG stm1) = S stm1 (fn s => ERROR) sigma0
and S (id := exp1) th =
E exp1 (fn v => fn s => th (upd(s, id, v)))
| S (RETURN exp1) th =
E exp1 (fn v => fn s => done v)
| S (SEQs (stm1, stm2)) th = S stm1 (S stm2 th)
val _ = P : prog -> A
val _ = S : stm -> C -> C
*** Semantic equations, part II ***
and E (SEQe (stm1, exp1)) k = S stm1 (E exp1 k)
| E (NUM v) k = k v
| E (ID n) k = (fn s => k (s n) s)
| E (exp1 + exp2) k =
E exp1 (fn v1 =>
E exp2 (fn v2 => k (plus(v1, v2))))
val _ = E : exp -> K -> C
Ideas:
Domains: (board)
V = Int
Ide
Lbl // labels, new
sigma : S = Ide -> V
A = Answers
theta : C = S -> A
rho : Lenv= Lbl -> C // label meanings, new
Exp = S -> V // back to direct-style expressions
Stm = Env * C -> Env * C // changed
Prog = A
Semantic functions for base types and syntax
I : ID -> Ide
N : NUM -> V
E : exp -> Exp
S : stm -> Stm
P : prog -> Prog
Semantic functions for values, environment, and store
plus : V -> V -> V
update : S * L * V -> S
ifnz : V * S * S -> S
done : C // end of the program
fst, snd
Abstract syntax and semantic equations for a program:
P[[stm]] = snd(Y(\(rho_L, theta).S[[stm]](rho_L, done))) sigma_0
rho_final, theta = S[[stm]] (rho_final, done)
Abstract syntax and semantic equations for statements:
S [[ID := exp]] (rho_L,theta) =
(rho_L,\sigma.theta(update(sigma, I[[ID]], E[[exp]] sigma)))
S [[s1; s2]] (rho_L,theta) = S[[s1]] (S[[s2]] (rho_L,theta))
S [[IF exp THEN GOTO L]] (rho_L,theta) =
(rho_L, \sigma.ifnz(E[[exp]]sigma, rho_L([[L]]), theta sigma))
S [[L:]] (rho_L, theta) = (update(rho_L, [[L]], theta), theta)
Abstract syntax and semantic equations for expressions:
E [[NUM]] sigma = N[[NUM]] // note state is ignored
E [[ID]] sigma = sigma(I[[ID]])
E [[e1 + e2]] sigma = plus (E [[e1]] sigma) (E [[e2]] sigma)
Things to notice:
- Label definition has same continuation but updates environment
- Conditional goto can ignore inline successor theta but pull from environment.
Why Smalltalk?
- Turing Award winner
- Small, simple, pure objects
- Almost the complete language can be done in a relatively small interpreter
Alive and well today
- At the core of Ruby
- As an extension to C ("Objective C") for Apple products
The five questions:
Values are objects (even true, 3, "hello")
Even classes are objects!
There are no functions---only methods on objects
Syntax:
mutable variables
message send
sequential composition of mutations and message sends (side effects)
"blocks" (really closures, objects and closures in one, used as continuations)
No if or while. These are implemented by passing continuations to Boolean objects.
(Smalltalk programmers have been indoctrinated and don't even notice)
Environments
Dynamic semantics
- Main rule is method dispatch (complicated)
- The rest is familiary
The initial basis is enormous
- Why? To demonstrate the benefits of reuse, you need something big enough to reuse.
*** Abstract syntax (approximate) ***
datatype exp = VAR of name
| SET of name * exp
| BEGIN of exp list
| SEND of name * exp * exp list
| BLOCK of name list * exp list
| LITERAL of rep
Analysis of syntax (board):
Protocol is Smalltalk term of art:
- The set of messages an object can respond to
- What it is supposed to do on receipt
Ruby dialect "duck typing" is a statement about protocols
Protocol is determined by the class of which an object is an instance
- About classes and instances, more later

Arities:
- Symbolic messages: arity 1
- Keyword messages: arity is number of colons
Every object gets not just the protocol but the implementations from its class. And a class can inherit from its superclass (more undefined terms) all the way up to class Object.
*** Simple examples ***
-> (isKindOf: 3 Object)
<True>
-> (isMemberOf: 3 Object)
<False>
-> (isNil 3)
<False>
-> (isNil nil)
<True>
-> (println nil)
nil
nil
*** SLIDE ***
-> true
<True>
-> True
<class True>
-> Object
<class Object>
Key strategy for reuse in object-oriented languages: subtype polymorphism
A value of the subtype can be used wherever a value of the supertype is expected.
Board:
- SUBTYPE != SUBCLASS
- SUPERTYPE != SUPERCLASS
Only crippled languages like C++ identify subtype with subclass
Only the ignorant and uneducated don't know the difference
Subtyping mathematically:
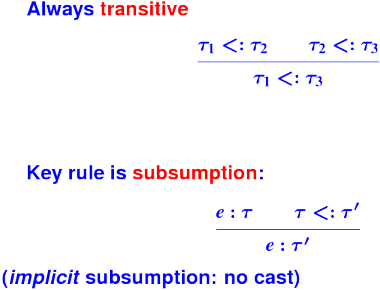
Subtyping is not inheritance:

Blocks are closures
Blocks are objects
Booleans use continuation-passing style
Protocol for Booleans:

Booleans implemented with two classes True and False
one value apiece
*** Classes True and False ***
(class True Boolean () (method ifTrue:ifFalse: (trueBlock falseBlock) (value trueBlock)) ) (class False Boolean () (method ifTrue:ifFalse: (trueBlock falseBlock) (value falseBlock)) )
*** Common methods in superclass ***
(class Boolean Object () (method ifTrue:ifFalse: (trueBlock falseBlock) (subclassResponsibility self)) (method ifTrue: (trueBlock) (ifTrue:ifFalse: self trueBlock [])) (method not ()
(ifTrue:ifFalse: self [false] [true])) ... )
*** Blocks manage loops ***
-> (val x 10)
-> (val y 20)
-> (whileTrue: [(<= x (* 10 y))]
[(set x (* x 3))])
nil
-> x
270
Protocol for blocks:

Goal of objects is reuse
Key to successful reuse is a well-designed class hierarchy
Killer app: toolkits for building user interfaces
Smalltalk blue book is 90 pages on language, 300 pages on library
Lots of abstract classes
- Define protocols
- Build reusable stuff, just like class
Boolean
``Collection hierarchy'':

| Collection | contain things |
| Set | objects in no particular order |
| KeyedCollection | objects accessible by keys |
| Dictionary | any key |
| SequenceableCollection | keys are consecutive integers |
| List | can grow and shrink |
| Array | fixed size, fast access |
Collection mutators:

Collection observers:

Collection iterators:

Implementing collections:

Reusable methods:

\lit{species} method:


Most subclass methods work by delegating all or part of work to list members
N.B. Set is a client of List, not a subclass!
Real Smalltalk syntax: receiver first:

Mixfix message sends:















ENGINEERING FELLOWS FOCUS GROUPS
Unlocking the final door for building large software systems
You have all gotten good at first-class functions, algebraic data types, and polymorphic types
Modules are the last tool you need to build big systems
Many paths will be open to you:
Direct use of functional programming with modules, largely at hedge funds and investment banks
Ideas translate to many other languages
Functions of a true modules system:
Hide representations, implementations, private names
"Firewall" separately compiled units (promote independent compilation)
Possibly reuse units
Real modules include separately compilable interfaces and implementations
Designers almost always choose static type checking, which should be "modular" (i.e., independent)
C and C++ are cheap plastic imitations
- C doesn't provide namespaces
- C++ doesn't provide modular type checking for templates
Collect declarations
- Unlike definition, provides partial information about a name (usually environment and type)
Things typically declared:
Terminology: a module is a client of the interfaces it depends on
Roles of interfaces in programming:
The best-proven technology for structuring large systems.
Means of hiding information (ask "what secret does it hide?")
A contract between programmers
- Essential for large systems
- Parties might be you and your future self
A way to limit what we have to understand about a program
- Estimated force multiplier x10
Interface is the specification or contract that a module implements
- Includes contracts for all declared functions
Two approaches to writing interfaces
Interface "projected" from implementation:
- No separate interface
- Compiler extracts from implementation
(CLU, Java, Haskell, Oberon)
- When code changes, must extract again
- Few cognitive benefits
Full interfaces:
- Distinct file, separately compiled
(Caml, Modula, Ada)
- Implementations can change independently
- Full cognitive benefits
Structure of implementations
Holds all dynamically executed code (expressions/statements)
May include private names
May depend only on interfaces, or on interfaces and implementations both (max cognitive benefits when all dependency is mediated by interfaces)
Dependencies may be implicit or explicit (import, require, use)
The Perl of module languages?
Has all known features
Supports all known styles
Rejoice at the expressive power
Weep at the terminology, the redundancy, the bad design decisions
What we've been using so far is the core language
Modules are a separate language layered on top.
ML module terminology
Interface is a signature
Implementation is a structure
Generic module (parameterized implementation) is a functor
You have too many choices
Implementations
May depend directly on other implementations (bad design --- no true separate compilation)
May be parameterized over interfaces (signatures) and then instantiated with implementations
May be "constrained" by interfaces (good)
using "signature ascription"
Structures match signatures
The implementation relation is called matching
- "A structure
Foo matches a signature FOO" if Foo is an implementation of FOO
Surprise! A single structure can match many signatures
A structure has a private name space
To refer to other structures, use qualified names
Int.toString
TextIO.stdIn
Real.fromInt
Structures relate to other structures
No explicit imports (terrible decision)
Explicit exports handled by signature ascription (good decision)
Structures may be nested (great decision)
- terrifically useful when managing namespaces
Workaround for lack of imports
External structures should usually be abbreviated:
structure S = String
structure C = Char
val ucase = S.map C.toUpper
val doubleVision =
S.translate (fn c => S.implode [c, c])
If you use open, I will hunt you down and hurt you
(breaks modularity)
Signature says what's in a structure
Specify types (w/kind), values (w/type), exceptions.
Ordinary type examples:
type t // abstract type, kind *
eqtype t
type t = ... // 'manifest' type
datatype t = ...
Type constructors work too
type 'a t // abstract, kind * => *
eqtype 'a t
type 'a t = ...
datatype 'a t = ...

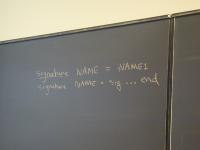














*** Example: environment signature ***
signature ENV = sig
type 'a env
eqtype name
exception NotFound of name
val empty : 'a env
val bind : name * 'a * 'a env -> 'a env
val find : name * 'a env -> 'a
end
*** Environment structure ***
structure ListEnv : ENV = struct
type name = string
type 'a env = (name * 'a) list
exception NotFound of name
val empty : 'a env = []
fun bind(n, x, rho) = (n,x) :: rho
fun find(n, []) = raise NotFound n
| find(n, (n', x')::l) =
if n = n' then x' else find(n, l)
Matching is OK, but too many details exposed
- This is transparent matching
Two kinds of ascription (matching)
What is hidden?
Transparent ascription ListENV : ENV
- Verifies match
- Hides names not in signature (none here)
- Allows all types to ``leak out'' through colon
(Therefore, no true separate compilation)
Opaque ascription ListENV :> ENV
- Verifies match
- Hides names not in signature
- Hides all types except those explicit in signature
(The > symbol plugs the leak)
But wait! The opaque version is useless! We don't know what type name is.
Reveal that names are strings:

Going back, signature does not really work with search trees
- Need more than just an equality type, need order
Equality types are a bad idea anyway
*** More abstract environments ***
signature ENV = sig
type 'a env
type name
exception NotFound of name
val empty : 'a env
val bind : name * 'a * 'a env -> 'a env
val find : name * 'a env -> 'a
end
*** Environment with binary-search tree ***
signature ORD_KEY = sig
type ord_key
val compare : ord_key * ord_key -> order
end
functor SearchTreeFn(Key: ORD_KEY) : ENV =
struct
... binary-tree implementation ...
end
(ord_key?! These people have no taste!)
You give me an ordered type, and I'll give you an environment:
Heavier weight than core-language solution
But you don't have to futz with passing comparison functions
And therefore it's much harder to get wrong!
Key idea: SearchTreeFn is compiled once, used over and over, and supports modular type checking
Let's see the code!
*** Implementation of search-tree functor ***
functor SearchTreeFn(Key: ORD_KEY) : ENV = struct
type name = Key.ord_key
datatype 'a tree
= NULL
| NODE of name * 'a * 'a tree * 'a tree
type 'a env = 'a tree
exception NotFound of name
val empty = NULL
fun find (name, NULL) = raise NotFound name
| find (name, NODE (n', x', L, R)) =
case Key.compare (name, n')
of EQUAL => x'
| LESS => find (name, L)
| GREATER => find (name, R)
*** Search-tree functor, finale ***
fun bind (name, x, NULL) = NODE (name, x, NULL, NULL)
| bind (name, x, NODE (n', x', L, R)) =
case Key.compare (name, n')
of EQUAL => NODE (name, x, L, R)
| LESS => NODE (n', x', bind(name, x, L), R)
| GREATER => NODE (n', x', L, bind(name, x, R))
end
*** Using the functor ***
structure OrderedString = struct
type ord_key = string
val compare = String.compare
end
structure StringEnv =
SearchTreeFn(OrderedString)
Note that ORD_KEY is not required
- This is an "unconstrained" structure
Two-step process
Signature matching in two steps:
Step one: realize the signature
- Make all abstract types manifest
Step two: cut down the structure to match
A form of subtyping!!
"More polymorphic"
- Export of
name list -> int could be represented by forall 'a . 'a list -> int.


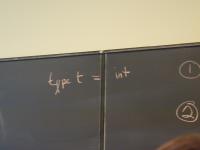







signatures, structures, functors
signature matching:
- make abstract types manifest
- make sure the structure is a subtype (everything called for in the signature, and more)
When are two types equal?
Abbreviation defined with type equals RHS
Type defined with datatype is always fresh
- The
datatype construct is generative
Abstract types are never equal,
- Unless there is a sharing constraint
Example with sharing
Interactive interpreter with persistent store.
signature INTERPRETER = sig
type value
type exp
val eval : exp * value ref Env.env -> value
end
signature PERSISTENT_STORE = sig
type value
val save : (string * value) list -> unit
val restore : unit -> (string * value) list
end
Abstractions must agree
Interpreter and store must have same value type:
functor INTERACTIVE_SYSTEM (
structure I : INTERPETER
structure S : PERSISTENT_STORE
sharing type I.value = S.value
) = struct ... end
Could use SML like Modula, Ada
- One structure, one signature, no/rare functors
Doesn't work as well as Modula, Ada:
- If you even mention another structure, you get import dependencies that are not easy to discover
Goal of SML is flexibility, not control.
Tofte style:
- Write everything as functors and signatures
- Build the whole system by functor application
(See "four lectures on standard ML")
Crucial advantages:
Because there are no structures until the end, properties of structures can't "leak" by accident.
Dependencies between modules are explicit and totally controlled.
What most people do: a haphazard mix of functors and structures
| Core language | Modules language |
| Function maps value to value | Functor maps structure to structure |
| Cannot depend on a type | Can depend on a type |
| Unknown type? Must carry around
clunky type parameter | Unknown type? No problem! It's invisible.
(Think `type 'a env` does not depend on names) |
| Lightweight notation | Heavyweight notation |
| Inconvenient if there are a lot of arguments | Easy when there are a lot of arguments (names!) |
| Has a run-time cost | Essentially no run-time cost |
Modules more flexible about information hiding
Comparing modules and objects
A module can encapsulate two types:
signature CONTROL_FLOW_GRAPH = sig
type graph
type node
val entry : graph -> node
val exit : graph -> node
val graph_of : node -> graph
val successors : node -> node list
...
end
Both graph and node ``methods'' know all
Modules, objects, and reuse
Like Smalltalk protocols and Java interfaces,
SML signatures support subtyping
But no automatic code reuse (no inheritance)
- Instead, reuse code by applying functors
SML modules: powerful but strange
Power beyond mortal ken
Clean winner on expressive power
Reliability, not so much
Module semantics is considered intimidating!
- Still a topic for research
Needed: good models, guidelines, tutorials
Back to class home page