



Introduce course staff
Myself: programming language guy, but deeply involved in compilers, assemblers, linkers, debuggers, all of which work with machine structures and assembly language.
Call me 'Professor' or 'Professor Ramsey' or 'Norman'
Please do not call me 'Ramsey'
I like questions! If you have a question, chances are several other people also have a similar question.
Eli Brown: Head grader, evalute your written work
Teaching assistants: Greg Bodwin, Adrienne Dreyfus, Hawk Glazier, Amanda Hay, Foster Lockwood, Marshall Moutenot, Josh Pearl
Pair programming with the course staff: Ari Kobren, Jesse Welch, me
Hanson is essential, Kernighan and Ritchie is highly recommended
For the other book, it depends how much you like books---suggestions on web. If books will save you time, spend the money.
Today's handouts:
Printed copies of web pages:
Syllabus needs two observations:
Everything in this course is about the projects
By overwhelming student request, the lectures on the next project start just before the current project is due. (No just-in-time lectures.)
This is a change from last year: the idea is that after you get all the lecture on a topic, you still have a few days to finish the project. Please let me know how it goes.
Article about pair programming
You do all coding with your partner in the room.
Splitting an assignment into pieces and doing them separately is strictly forbidden.
You're going to like it
First homework assignment and a supporting interface and
implementation. For Friday's lab you'll need to have read the
assignment and to have some idea about the Pnmrdr interface (but
not its implementation), so that's just pages 1--3.
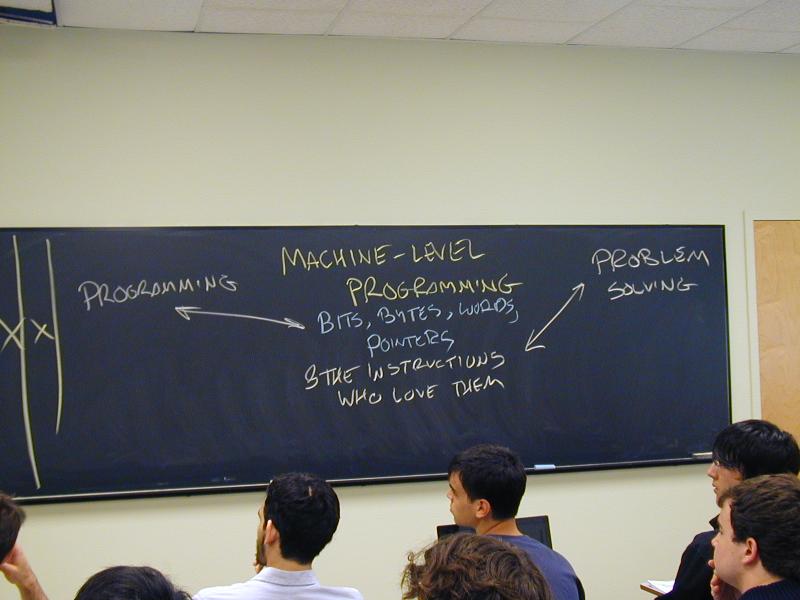
bits, bytes, words, pointers, the caches they live in, the instructions that command them
connect to Programming
connect to Problem-Solving
But also
Raise programming to another level (Last required programming course---and most ambitious)
11's building blocks were statements and expressions
15's building blocks were functions and methods
40's building blocks are modules
The course is all about projects:
Last year: ``I finally figured out that you don't teach us the material in lecture; we teach ourselves the material as we work on the projects.'' Exactly what you should expect.
Lectures give you the foundations---a place to stand---often from a more theoretical perspective. Then you go out and apply what you've learned.
Labs are mandatory. Most labs are oriented to the projects
You're going to work really hard, and a lot of you are going to earn high grades.
My goal is to give you great projects. What makes a project great?
The projects will be connected to real-world problems. I can't give you "Fire in the Fells", but I can give you projects that relate to real problems. Mostly we'll focus on image-processing problems and on the tools used to create executable machine code.
You will not just acquire knowledge; you will apply knowledge of machine-level programming
Extend your reach and abilities as a programmer
You're going to want to talk about the work you did on these projects. You're going to have an opportunity to take pride in your work, and for many of you the work you're going to do is going to mean a lot more to you than whatever grade you earn.
Truth in advertising: not everyone is going to think every project is great. But in focus groups last spring, and everybody has a couple of favorites, and they're not always the same ones. All the projects are at least pretty good, and each year I work to make them better.
Satisfied customer:
I just got out of back to back interviews at Google Cambridge today. I just wanted to thank you for stressing design so much in Comp 40. I know that I achieved optimal solutions for the two interviews. Both of my interviewers were very pleased with how I wanted to write out the program's process in english and go deeply into designing before even thinking about coding. They really appreciated the fact that I was always keeping how every module of code fit into the bigger picture in terms of complexity, placement, and design. Even though I was learning on the spot, having had similar learning experiences in 40 was a huge, huge benefit. I thought I'd just let you know how useful COMP 40 was to my experience.
FAQ:
What I want most is for each of you to do work you are proud of.
I want each of you to learn as much as you possibly can.
I want you to work hard---natural ability counts for something, but hard work will take you farther than natural ability.
I want you to work with discipline and good technique:
Discipline includes a sustained effort over time. Projects are designed for 90 minutes a day for the average student. Try to cram that time into two days, and you can double it.
Good technique is not required to complete all the projects successfully. Most of them, although bigger than what you are used to, are still small enough that you can brute-force your way to it. Don't do it. You'll double or triple the amount of time it takes.
I'll be spending class time, lab time, and handouts on how to work with good technique. You'll also have the chance for small-group instruction to help you hone your technique. Because what I don't want is for you to exhaust yourself spending endless hours in the lab and missing out on your other classes.
Discipline and technique are essential!
The best discipline is brief daily sessions of 45-90 minutes
What about technique?
Group exercise: technique (20 minutes)
Who has an idea what abstraction is?
Answers
Parameterizing over something, where something about the parameter is not known.
Connecting the world of ideas to the world of implementation, and showing that the world of implementation faithfully reflects the world of ideas. (You may substitute "homework problems" for "ideas".)
So what's so special about the machine level of abstraction?
Some faults can be diagnosed only if you understand machine-level programming.
To understand and improve performance, you must understand the machine level.
The foundation of the world's computing infrastructure is built at this level, in C or C++.
A problem: AMD64 is too complex to be mastered in one semester. So, you'll learn to analyze AMD64 code, but you won't write much. To understand assembly code and machine instructions in depth, later in the term we'll work with a virtual machine. Most students find this pretty interesting.
This week in COMP 40:
Technique (from last week)
Invariants
Polymorphism, higher-order functions, boxed data, Table interface
More invariants, abstraction functions, unboxed data, UArray interface
warnings: don't turn them off!
To get around 'unused variable' warning:
Pnmrdr_T rdr = Pnmrdr_new(fp);
(void) rdr; // prevents 'rdr' from being unused
40 asks you to do more:
In 40, you don't program to our test cases---you make your own test cases (part of raising your game). Part of a programming discipline.
In 11 and 15, in-class discussion to get a feel for projects and design solutions. In 40, you do this on your own.
Suggestion: talk projects over with several classmates, not just your programming partner. Conversations are encouraged, you just can't work on code.
Some of your technical ideas:
Drawing diagrams [Ideas: your data (right away), a call graph (later), a module-dependency graph (much later), a concept map (for brainstorming)]
Sequence: English, pseudocode, code
Lots of stopping and stepping back. That's good. But how do you know when to stop or step back?
Answer: figure out for yourself what works for you. Observe yourself and your partners over the next couple of weeks. We'll return to this question.
Skills and techniques from other disciplines:
Jillian Silver: remember to eat and drink
From swimming: don't panic and flail (A real hazard in 40)
Chris Smith: Learn something and then forget it so that it becomes natural (universal truth of any skills-based learning)
I hope a handout is coming
Techniques from the professor:
Maintain a single point of truth for all information (e.g., what year it is on the class web site)
Code should go directly from brain to screen without stumbling over your fingers:
Minimize keystrokes for frequently performed operations
Repeat: code must flow from your brain onto the screen
Why? One of the three topics of this course is programming, and you have now reached the stage where in order to improve, you need to observe yourself and how you do things. It's not just about the finished project. How you work really affects how long it takes to finish.
You have to read the course policy pages; they will tell you important stuff like we don't take submissions that have tab characters in them or that are wider than 80 columns.
And more important stuff like:
If a program dumps core without a sensible error message, No Credit for functional correctness.
To get high grades you have to run valgrind without errors; to get top grades you have to run without leaks as well. (If you hit a checked run-time error, leaks are OK.)
For the rest, read when you are stuck or are moving more slowly than you would like on problems. For example,
If you know how to do something in C++ but not in C, that would be the time to look at the C idioms.
If you are having trouble with error messages at compile time, that might a time to look at the handout on how to write compile scripts.
If you can't get something to work, http://stackoverflow.com!
For tonight's design document, we just want an explanation of what data structures you will use to solve the problem of the fingerprint groups, and how the contents of those data structures relate to the input. (The loop invariant.) A couple of well-written paragraphs will do the job. Certainly no more than a page.
Note: we expect your code to perform reasonably on inputs of several hundred thousand lines
The problem we're trying to solve is that your brain is too small!
11 and 15: summarize code by giving a narrative sequence of events:
Problems with narrative sequences:
Known to be hard (6 questions on AP CS exam, all about simulating sequences of events, predict success on the entire exam)
Your brain can only hold so much
Conclusion: narrative thinking holds you back
Solution: replace narrative thinking with a new habit of thought
Think about data and its invariants
Two consequences:
If you know the data and its invariants, you can reconstruct the narrative on demand. (Show me your data and I won't need to see your code; it will be obvious.)
Because there's less to remember, you can solve bigger problems with less work
Sort array of integers in place:
Table interface



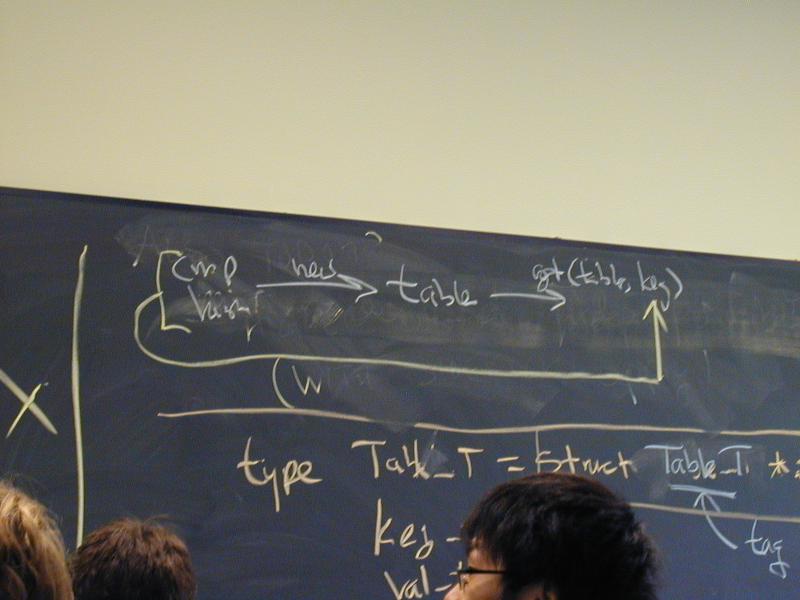


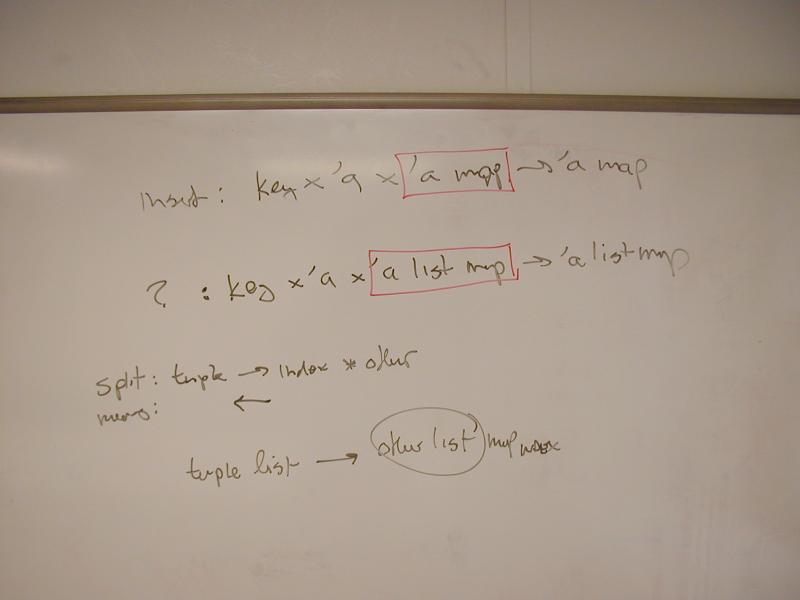
Homework advice:
If seeking help with code that compiles but does not run:
Submit your assignment
Tell us what valgrind says
Today:
Abstract data types in the world of ideas
Contracts (precondition, postcondition, cost model)
Polymorphic container with boxed elements
Higher-order map function with companion apply function
Detailed analysis of the Table interface, with special attention to void type and C-style polymorphism.
Two of the most important concepts in programming
Parametric polymorphism
Function closures
Neither concept is inherently difficult, but
Both are unfamiliar (unless you've had 105)
Both are awkward in C++
Both are extremely awkward in C
Had you studied Scheme or Haskell or ML, the compiler would handle it, and you would barely even notice what was happening. In C, you must make it all happen yourself.
Start with parametric polymorphism:
What are the type parameters? (If you prefer, template parameters)
Let's modify the interface by identifying which voids represent
key and value (looking at just the put and get methods):
So, can you define a Table_T in which the values are integers?
And now, 16 variations on a theme (computer demo)
High points:
void * is a pointer to an unknown type
void * might also be an unknown pointer type
Joining state and code together using function pointers and
void * pointers enables powerful abstractions like iterations
These techniques are required to support polymorphism
Polymorphism is your main hope of reuse

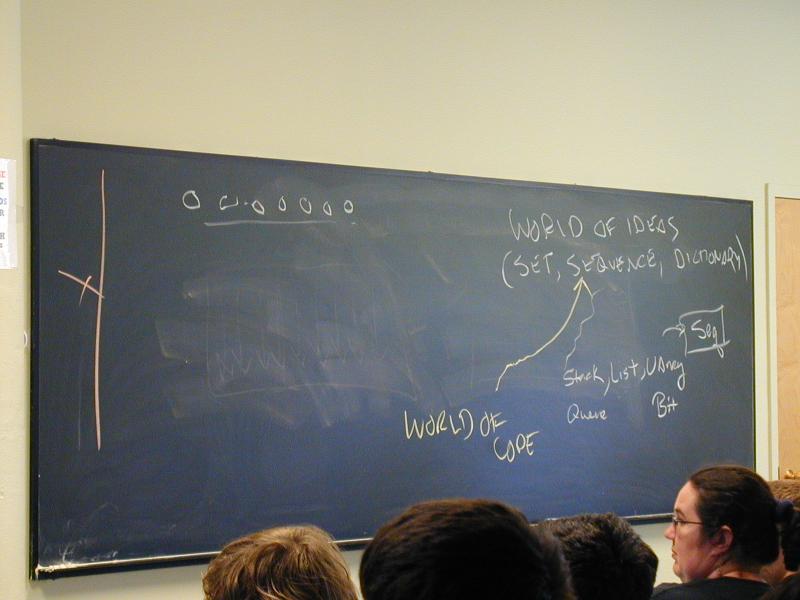



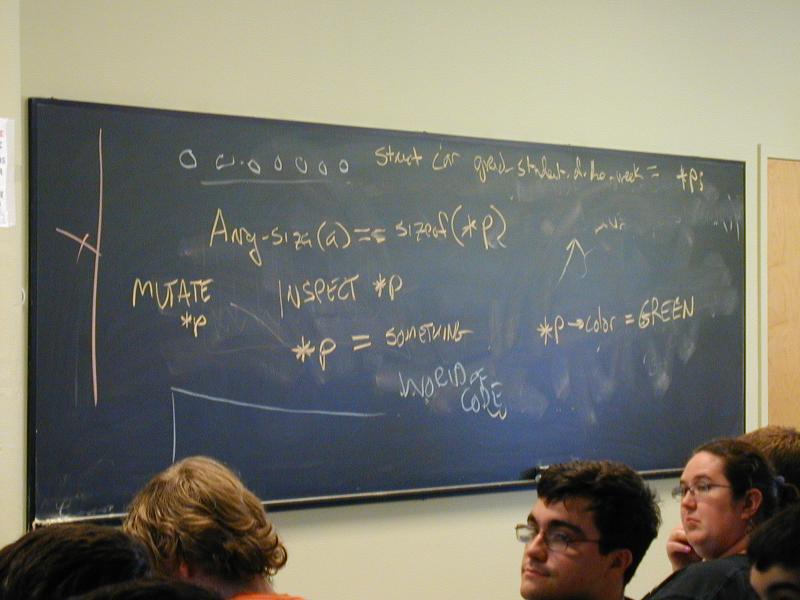


Learning objectives:
The parable of the terriers, the squirrels, and the lion
mapLearning to program with abstraction and invariants so that we can tackle interesting problems instead of boring problems.
Most likely source of bugs in your code:
Invariant does not properly relate the world of ideas to your implementation, or
Invariant is violated
The design checklist will help you debug faster
Today's class: Invariants, contracts, and implementation
Wednesday: compiling and linking, starting to look at machine structure
The UArray interface with operations classified:
typedef struct T *T;
extern T UArray_new (int length, int size); // creator
extern void UArray_free(T *array); // destroyer
extern int UArray_length(T array); // observer
extern int UArray_size (T array); // observer
extern void *UArray_at(T array, int i); // observer
extern void UArray_resize(T array, int length); // mutator
extern T UArray_copy (T array, int length); // producer
Suppose array a is a Hanson UArray_T containing values of type struct pixel.
Here is how I recommend you get an expression containing the ith element:
struct pixel *p = UArray_at(a, i); // capture pointer into the array
// (valid until resized or freed)
assert(sizeof(*p) == UArray_size(a));
... *p ... // use expression of struct type
This approach is more verbose than the uses of Array_get in Hanson's
book, but it is also robust against changes in type. Why?
The Ramsey approach has a
single point of truth,
that is, the type is mentioned in only one place. In the Hanson approach,
the type is mentioned in multiple places, and it is easier to write inconsistent
code.
Suppose function f() returns a value of type struct pixel you want to store in
an unboxed array.
struct pixel *p = UArray_at(a, i); // capture pointer into the array
// (valid until resized or freed)
assert(UArray_size(a) == sizeof(*p)); // detects some errors
*p = f();
(picture this)
struct UArray_T {
int length;
int size;
char *elems;
};
What's the invariant?
If length > 0 then elems points to a contiguous block of
memory large enough to hold length elements each of size
bytes; that is, a block of size * length bytes.
If 0 <= i < length, then element i of the array is pointed to
by a->elems + i * size. (Note the type char *.)
In particular, if 0 <= i < length and 0 <= k < size, then
byte k of block i in the abstraction (world of ideas)
corresponds to byte a->elems[i*size + k] in the
representation.
Corollary: no element shares memory with any other element
Corollary: every byte of the elems representation corresponds
to a byte of an element in the interface
Question: can you change array without changing what's happening in
the world of ideas?
Question: how long is it safe to retain a pointer returned by UArray_at?
Question: What are the contracts?



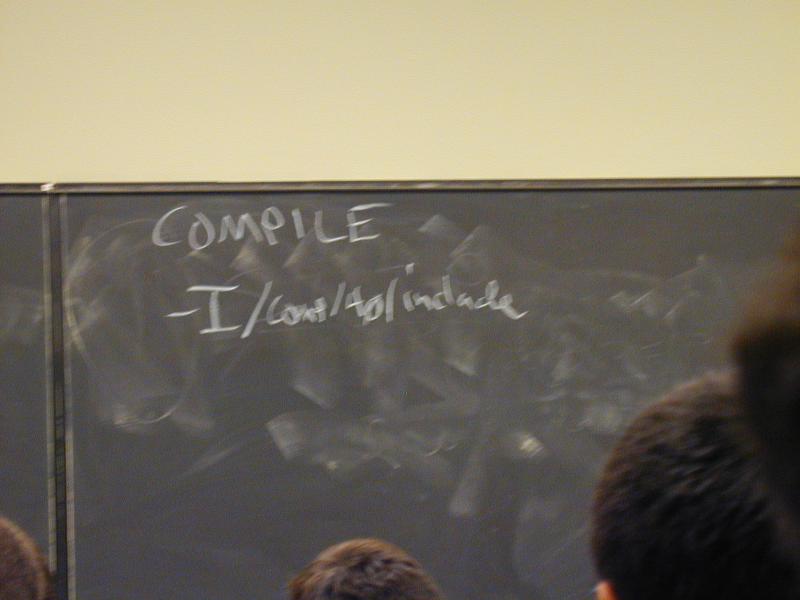
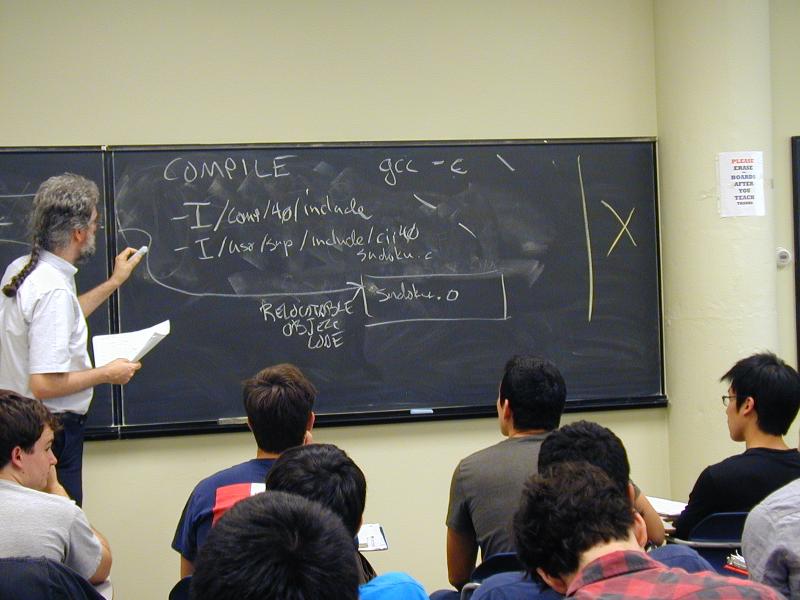


Special visitor at end of class
(You need this more than compiling)
Vague, pointless verbs:
Informative verbs:
A typical function that calculates something?
A typical function that acts on the state of the program, or the state of the world:
If your function does both, its contract is probably too complicated. If you can't fix it, document it very carefully. Show us you have thought about it.
Will have homework back later this week.
Fingerprint groups exposed some problems:
No correct solutions
One solution read the output spec correctly, but didn't properly signal empty input line
One solution read the input spec correctly, but didn't properly use newline as a separator in the output
12 of 25 solutions get every single test wrong, including the example in the output
Primary offenders:
Extra junk in standard output
Junk to standard error
Output formatted incorrectly
Do not parse fingerprint and name correctly
My diagnosis:
"Right in concept" vs "Right in practice"
The gap and the chasm
Output for people versus output for other programs
Two illustrations
The email program from the last ice age
The treehouse game in Windows 8 (unparalleled achievement by one of our own, who sat in your chair last year
Most of these problems can be solved by attention to detail:
If your program doesn't meet the specification, we want to figure out what went wrong---to give you a fair grade, we have to be able to distinguish trivial errors from significant errors.
But our goal here is not to give grades---we want to use our time to read your code and help you get better.
Help us by following directions scrupulously. As you read an assignment, ask "what requirements are being imposed on my program here?"
Two reasons why this stuff matters:
It matters for your grades: if we can't tell easily that your answer is "almost right", it will be graded as wrong
The real reason: to build big stuff, you have to get people out of the loop. Your code has to be exactly right. Microsoft and Google and Apple all understand this. In fact I think you'll find out that places like Microsoft know exactly what COMP 40 means.
Your best source to read about this material is my handout on How to Write a Compile Script.
Questions:
Can we create a program just from UArray2? What would that mean?
Where does every C program (and C++) start executing?
Things to remember from the compilation lecture:
Any single invocation of gcc should compile or link, but not
both
For every .h file there should be a corresponding .c file or a corresponding .o file (or both).
When compiling,
You present a .c file and use gcc -c.
To help the compiler find .h files, you use the -I option.
How do you know which directories contain the .h files you want? It's different for every library. Consult the documentation, or better, find someone who knows.
When linking,
You're gluing together a collection of .o files. Each one contains relocatable object code.
Each .o file is either mentioned on the command line
or brought in from a library. If a .o is mentioned on the
command line, you always get it. If a .o is in a library,
you get it only if it provides a definition (like printf)
that is used by a function (like main) in another .o file.
mentioned on the command line
A library is a collection of .o files.
You get a library by writing -lname, and the compiler
hunts for a file called libname.a (or sometimes,
libname.so).
To tell the compiler where to hunt for libraries, you use the
-L option at link time.
Things to try to see what goes wrong:
Link a collection of .o files without any main() function
Link a collection of .o files with two main() functions
Signs that your compile script is broken:
A mix of .c and .o arguments
The -I option used in a linking step
A .c file passed as an argument in a linking step
The -l or -L option used in a compilation step
A .o file passed as an argument in a compilation step
A .h file passed as an argument anywhere (advanced technique---don't use it)






Another step on the software track, but the same kind of thing you've been doing. Plus two bonus activities: experimental computer science and performance improvement. Therefore, more time.
Another abstract data type: blocked, 2D, unboxed array
Another application: image rotation
Object-oriented programming in C through mediators
Understanding the hardware
Measuring and understanding performance
A point about reading PNM files:
The Pnmrdr was good when we had no 2D arrays
Switch now to the Pnm interface; it exploits your 2D arrays
Function pointers to the max
Questions?
Newtonian (classical) picture of storage:
Address space is a big blob
Variables are somewhere
All costs are equal
Classical picture works in everyday cases, but breaks down at the extremes.
To get from Newton to Einstein, we need to know more about storage
A register is a one-word container
16 Integer registers: general-purpose
16 SSE registers (XMM): floating-point, vector
8 legacy floating-point registers: 80-bit floating-point
control word
status word
It is impossible to create a pointer to a register
New terms of art (for language designers and compiler writers)
Location is the container
Value is the thing contained
Very occasionally you'll hear a location called a "mutable cell".
This distinction is important because we need to understand the difference between a location (which a program can assign to) an a value (which cannot be assigned to).
Address space is a sequence of 2-raised-to-64 one-byte containers (but only 2-raised-to-48 are usable on today's machines)
Byte containers can be aggregated to form word containers
8 bytes make a 64-bit word
We'll look at details when we cover machine arithmetic
Address-space layout (software convention)
+-------------+
| OS reserved |
+-------------+
| ... |
| Dynamic |
+-------------+
| Stack |
| ... |
| (unmapped) |
| ... |
| heap |
+-------------+
| data |
+-------------+
| text |
+-------------+
| unmapped |
+-------------+
Wait a minute! There's not enough memory!
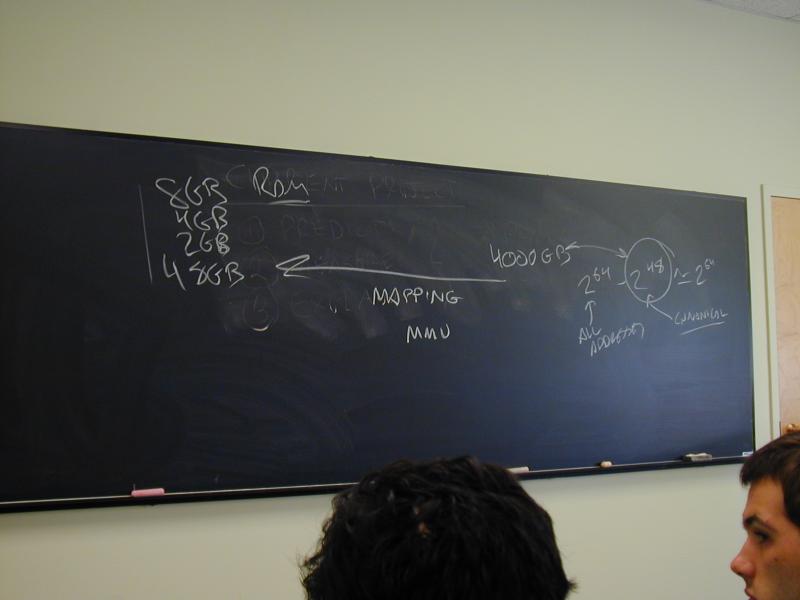
Address space: 2-raised-to-48 canonical addresses (256 terabytes)
Physical memory: 1-16 gigabytes typical (30-34 bits' worth)
Solution: Addresses are translated, also called mapped
The mapping is partial but is injective (one to one) on its domain
However, just counting shows that almost all addresses are unmapped
What happens when a program tries to use a container whose address is unmapped???
More on this in COMP 111 (Operating Systems)
Registers < 300B
L1 cache from 8KB to 128KB
L2 cache 512KB to 8MB
L3 cache 2-6MB
Note on the numbers:
The ideas are timeless, but the numbers change frequently
Every new chip/process changes cache size and speeds
A new architectural revision may add registers








Which is bigger, RAM or address space?
About how big is each one?
Do multiple processes share address space?
Do multiple processes share RAM?
How does it work?
What parts of the address space can you use?
What goes wrong if you use address space that doesn't belong to you?
How big is a register? How many registers can the CPU consume in a cycle?
How many words from RAM can the CPU consume in a cycle?
How big is level 1 cache?
How many words from L1 cache can the CPU consume in a cycle?
From the point of view of the memory hierarchy, what does the CPU do? That is, if we treat the CPU as an abtraction, what activity does the memory system see, and what activity is private or hidden from the memory subsystem?
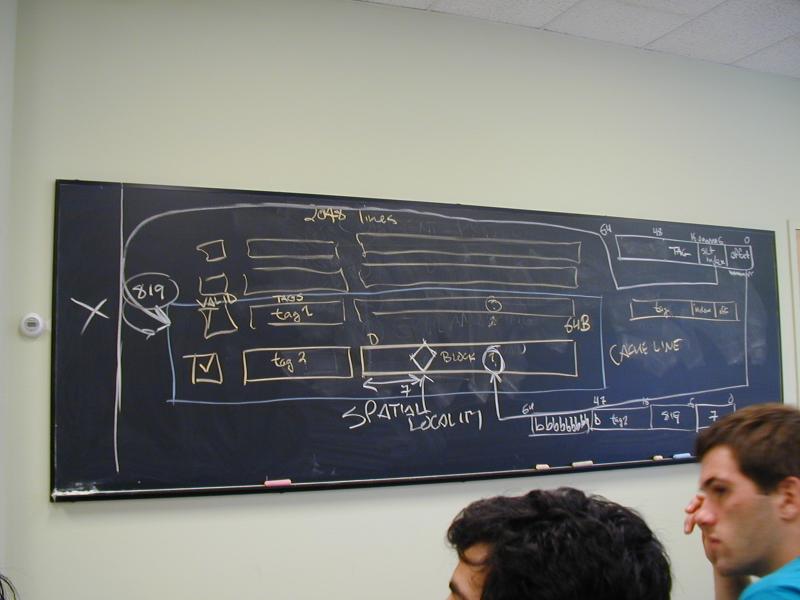
Sets of fast containers (not as fast as registers; faster than memory)
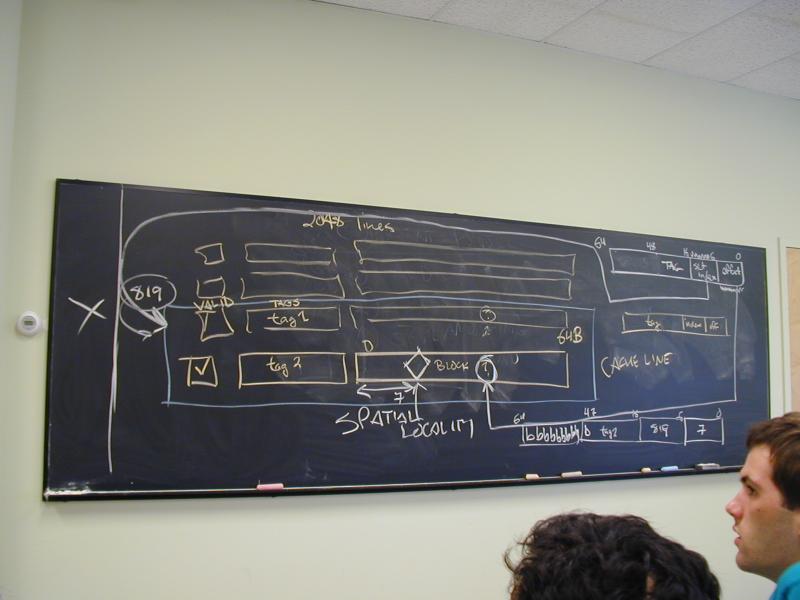
Two new terms of art (Bryant and O'Hallaron, first edition, page 506):
The cache line is the name for the container, plus extra information about what is in the container
The block is the name for the thing contained
Today's machines have a line size of 64B (8 words).
Phenom 9850 has very large 128KB L1 cache
2048 cache lines
To deliver two words per cycle, cannot possibly search all 2048 lines. Therefore lines are divided into sets.
Sets are organized for best performance
Architects do massive simulation
Alternatives are very well covered in Chapter 6
I will hit the high points
Search through sets is done by very simple hardware
Phenom 9850 uses 2 lines per set, so 1024 sets
Split address into pieces (see Bryant and O'Hallaron, first edition, page 488)
64 48 16 6 0
+------------+---------------+--------------+------+
| canonical | tag | set index |offset|
+------------+---------------+--------------+------+
A pedagogial lie:
64 16 6 0
+----------------------------+--------------+------+
| tag | set index |offset|
+----------------------------+--------------+------+
(Changes only how big things are, not how things work.)
A set holds two lines:
Each holds valid bit, tag, and block
+---+ +------------------------+ +---------------------+
| V | | tag (48 bits) | | Block (64 bytes) |
+---+ +------------------------+ +---------------------+
+---+ +------------------------+ +---------------------+
| V | | tag (48 bits) | | Block (64 bytes) |
+---+ +------------------------+ +---------------------+
Cache-search algorithm:
Take 10-bit set index from address, choose a 2-line set
In parallel, compare tags and check valid bits
If tags match and line is valid, use offset to index into block
Otherwise, we have a cache miss
Go to next level down and get a block
Find a place to put the block in the cache:
Determine which set by looking at bits of address
Within set, is any line invalid?
If yes, store the block and the tag and make the line valid
If not, evict a block to make room
Eviction:
Choose block that is least recently used or not used recently
May need to write the block to the next level down (write-back)
Block may already have been written (write-through)
Question: is there a scenario in which the program uses just 3 bytes in memory, but they cannot all fit in L1 cache?
Programs show a property called locality
Temporal locality: referring to the same address repeatedly, close together in time
Spatial locality: referring to an address close to another address in space
Idea: keep recently used bytes/words and nearby words in the cache
Einstein #1: more addresses than will fit in a set
conflict misses
easy with 2-way associativity (L1)
harder with 12-way or 16-way associativity (L2)
Einstein #2: more addresses than will fit in the cache
not in this class, but imagine an 8MB data structure in a 4MB class
capacity misses (rare in today's apps)
Non-Einsteinian #3:
compulsory misses
load a word you've never loaded before
Friday's lab an example
Image rotation an example
Block diagram:
Predictors can avoid "compulsory" misses!



(Nobody took photos, but there was an in-class exercise)
Address split
64 48 16 6 0
+--------------------------------------------------+
|canonical| tag | set index |offset|
+--------------------------------------------------+
Set of two cache lines (2-way associativity):
+---+ +---+ +------------------------+ +---------------------+
| D | | V | | tag (32 bits) | | Block (64 bytes) |
+---+ +---+ +------------------------+ +---------------------+
LRU ==
+---+ +---+ +------------------------+ +---------------------+
| D | | V | | tag (32 bits) | | Block (64 bytes) |
+---+ +---+ +------------------------+ +---------------------+
Question: CPU wants a byte from a random address: what block is loaded into what cache line?
Example: Conflict on a set of size 2 with three addresses
Cache miss at every load
How do you create it?
Assume cache lines are loaded on demand only
Examine graphs:
For stride of size k, how many misses per load?
L.L loads with stride k. How many lines
are loaded?Which hardware conforms to the model?
What is going on with the Core2 Quad Q6700?
Other questions
Type size alignment
bool 1 1
char 1 1
short 2 2
int 4 4
long 8 8
pointer 8 8
float 4 4
double 8 8
long double 16 16 (80 bits)
call stack -- 16










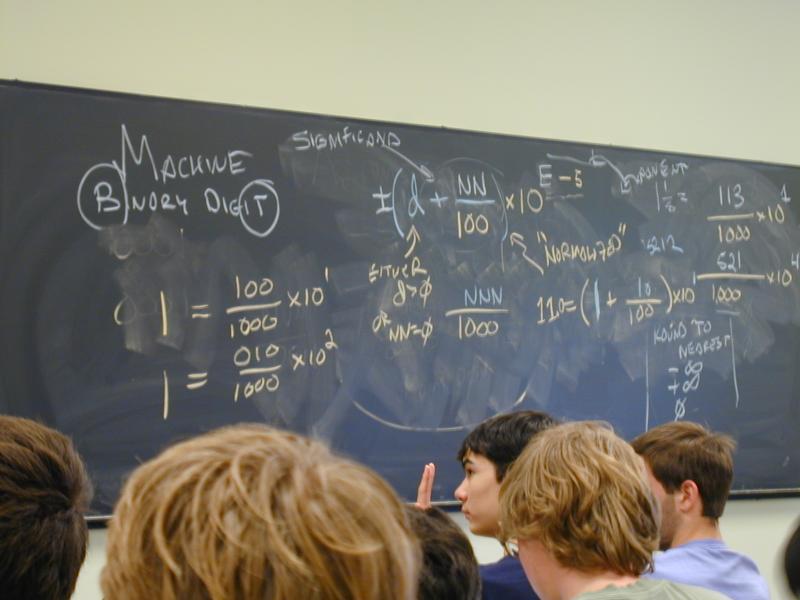
NOTE: In this lecture, I went wildly off script. The notes are not going to be very close to lecture. With luck I will have time to adjust the notes in retrospect. ---NR
Points of emphasis on the homework:
What's new: Predict, measure, explain
The right documentation in the right place
Example: does the invariant live next door? Upstairs? I think not.
The invariant sleeps with the representation.
Casts will kill you.
If you're having trouble with the a2methods interface we will help.
Arithmetic more fun to teach than to learn:
First trip through, hard to see how it all fits together
I will try!
We have a problem that exercises several kinds of arithmetic
Where we've been:
Cache and the costs of locality
Pointer arithmetic and pointer indirection:
Where we're going:
What can the hardware do with those pointers?
(Chase to other pointers)
Arithmetic on numbers
Characters, pixels, sounds are all made of numbers
How do we get from C to hardware?
| Topic | Base 10 | Base 2 |
| Positional notation | 1 | 7 |
| Natural numbers (unsigned ints) | 2 | 8 |
| Signed-magnitude integers | 3 | not used |
| Two's-complement integers | impossible | 10 |
| Fixed-point numbers (scaled integers) | 4 | --- |
| Floating-point numbers | 5 | 9 |
| Software emulation (rationals) | --- | --- |
| Software emulation (arbitrary precision) | 6 | --- |
| Bit vectors and logical operations | senseless | 11 |
Numerals and digits: Positional notation for integers
Limited precision: digits are in finite supply
Signs: sign-magnitude for floating point, two's complement for integers
Fractions: to approximate real numbers
Positional notation
Representations of real numbers:
Scaled integers sharing a denominator (fixed point) and their arithmetic
Rational numbers (each number its own denominator, no hardward support)
Floating point: scaled integers, with a limited set of scales and a compact representation
Binary arithmetic
Unsigned arithmetic
Two's-complement signed arithmetic
Bit vectors
n digits base b
d_{n-1} * b^{n-1} + ... + d_1 * b^1 + d_0 * b_0
Can represent any number k in the range 0 <= k < b^n
Examples: 112, 894
Addition: 112 + 894 = 1006
Question: how many additional digits needed to hold sum in general?
Question: how do you prove a theorem?
Multiplication: 112 * 894 = 100128
Question: how many digits are required to hold the product of an n-digit number and an m-digit number?
Question: do any of these theorems depend on the choice of base?
Add a plus or minus sign to a number in positional notation
Represent negative numbers with a minus sign
Negate a number by changing signs
Subtraction enters the picture (can represent k1 - k2 where k2 > k1)
Arithmetic means addition, subtraction, and multiplication on magnitudes, along with clever manipulation of signs.
No examples; you've all done this to death.
Finite precision: 3 digits
Want to represent real numbers.
Idea: scaled integers
Divide by implicit denominator
All numbers share the same denominator
If the denominator is a power of 10, we can use the world-famous decimal point. (It works just as well with any other base.) Let's use the denominator 10:
Real number 11.2 represented as 112 (implicit division by 10)
Real number 8.94 represented as 089 (loss of precision)
Addition works as addition of integers:
112 + 89 = 201
11.2 + 8.9 = 20.1
11.2 + 8.94 = 20.14
But
8.94 + 8.94 = 17.88 (to three digits, 17.9 or 179/10)
8.9 + 8.9 = 17.8 (loss of accuracy in calculation)
Multiplication requires dividing by the scale factor
11.2 * 8.94 = 100.128 = 100.0 (
11.2 * 8.9 = 99.68
112 * 89 = 9968 (overflow!)
112 / 10 * 89 = 11 * 89 = 979
Examples base 10 -- 3 digit significand
x = 10.1 normalized 1.01e1
y = 9.93 normalized 9.93e0
z = .707 normalized 7.07e-1
Typical coding exponent 10^n where n = exp - 5 and exp is one
digit
Range from 9.99e4 to 1.00e-4
Exp = 0 does not code 1e-5; instead it signals a denormalized number.

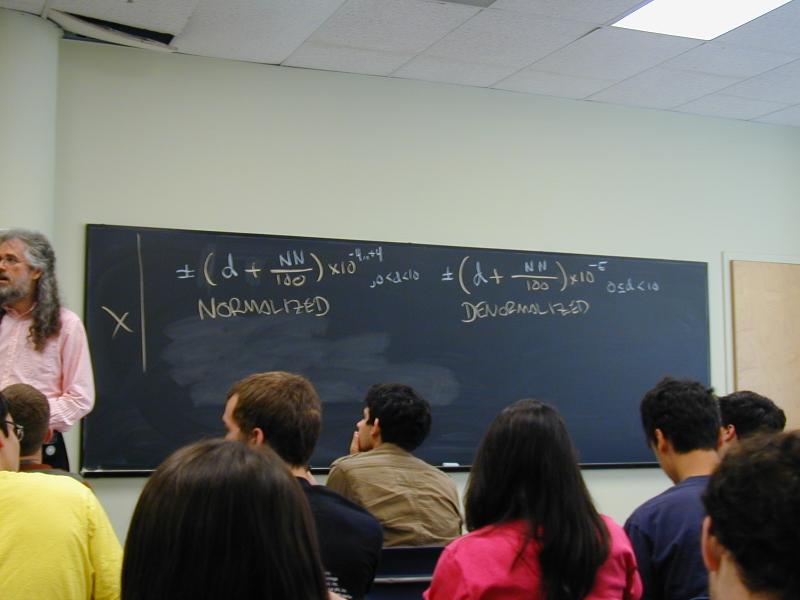



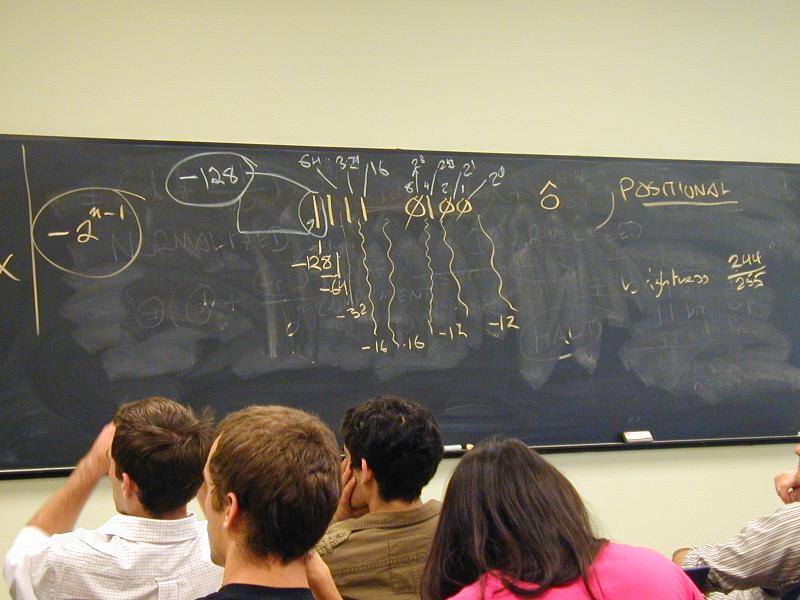





Dismal laws of computing:
Digits (bits) are a limited resource
The computer works with a positional notation and really only "understands" integers.
Real numbers can be approximated by scaling
Anatomy of a floating-point number:
Sign bit
Exponent (offset or "bias" coded)
Significand (or "fraction")
A number with n+1 digits of significand:
frac where 0 <= frac <= b^n
x = +/- (d + ---------------) * b^e where e typically is exp - bias
b^n where n is # of digits - 1
Normalized if d > 0
Simple floating point, base 10, 3-digit significand, 1-digit exponent
3.14 * 10^0
314 * 10^-2
.000314 * 10^4
Most important concept: normalized numbers
(d + NN/100) * 10^[-4..4], 0 < d < b
Q: Can every number be normalized?
Denormalized numbers:
(d + NN/100) * 10^-5 0 <= d < b
Q: Are there nonzero numbers that can't be normalized?
Q: Which ones can be represented as denormalized numbers?
Zero is a denormalized number
Sometimes write 'mantissa' or 'significand'
frac
m = (d + ---------------)
b^n
d is always 1 (in a normalized number) and need not be represented!Question: what goes wrong with 2^60 + 1?
What's this?
1111 0100
Ideas?
Bit stands for binary digit.
It's positional arithmetic, base 2.
Most significant bit is interpreted as sign bit
NOT sign-magnitude
Instead,
-d7*2^7 + d6*2^6 + d5*2^5 + ... + d1 * 2^1 + d0 * 2^0
So
1111 0100
-128 + 64 + 32 + 16 + 4
-64 + 32 + 16 + 4
-32 + 16 + 4
-16 + 4
-12
What therefore is the 6-bit
11 0100 ?
What about 16-bit
1111 1111 1111 0100 ?
And 5-bit
1 0100
Truth: given a signed integer in two's-complement representation, you can extend the sign bit as far as you like.
Questions
Smallest integer representible in 5 signed bits (two's complement)?
x xxxx
How do I complete the bits?
What is the value?
Largest integer representible in 5 signed bits (two's complement)?
x xxxx
How do I complete the bits?
What is the value?
What is the representation of -1?
Almost true that a 5-bit signed integer can represent the integers -15 to +15.
Treat word as a bit vector, do Boolean operations in parallel:
& bitwise and
| bitwise or
~ bitwise complement
Complement changes 0 to 1 and 1 to 0. So if we write
k = -d{n-1}*2^{n-1} + d_{n-2}*2^{n-2} + ... + d1 * 2^1 + d0 * 2^0
Then what are the digits of ~k
(1-d_{n-1}) ... (1-d0)
So what is the integer value of ~k + 1?
-(1-d{n-1})*2^{n-1} + (1-d_{n-2})*2^{n-2} + ... + (1-d1)*2 + (1-d0+1)*2^0
-(1-d{n-1})*2^{n-1} + (1-d_{n-2})*2^{n-2} + ... + (1-d1)*2 + (2-d0)*2^0
-(1-d{n-1})*2^{n-1} + (1-d_{n-2})*2^{n-2} + ... + (1-d1+1)*2 + (-d0)*2^0
-(1-d{n-1})*2^{n-1} + (1-d_{n-2})*2^{n-2} + ... + (2-d1)*2 + (-d0)*2^0
(2-d_i)*2^i -> 1 * 2^{i+1} - d_i*2^i
And eventually
(1-(1-d_{n-1}))*2^{n-1} + (-d_{n-2})*2^{n-2} + ... + (-d1)*2 + (-d0)*2^0
d_{n-1}*2^{n-1} + (-d_{n-2})*2^{n-2} + ... + (-d1)*2 + (-d0)*2^0
- (-d_{n-1})*2^{n-1} + (-d_{n-2})*2^{n-2} + ... + (-d1)*2 + (-d0)*2^0
- k
Most important are the signed and unsigned integers.
Differ only in the interpretation of the most significant bit
-2^{n-1}
or
+2^{n-1}
Serial formats:
a 32-bit integer has 4 bytes
a 64-bit integer has 8 bytes
Big-Endian is most significant byte first
Little-Endian is least significant byte first
We now reveal technology for extracting bytes (and implementing Bitpack)
Shift right and left, >> and <<
Suppose the two most significant bits are identical?
Then shift left 1 is equivalent to multiplying by 2
A right shift is always equivalent to a division
There are two right shift instructions.
Both notated as >> in C
Compiler chooses arithmetic or logical shift depending on type of operand.
What happens on a right shift if the least significant bits are not zero?
Boolean algebra plus shifter.
Recall our example byte:
1111 0100
Suppose we want to replace 101 with 010?
Or more generally, given
111xxx00
and given abc, how do we produce
111abc00?
Next problem: given two bytes
mnopqrst
and
abcdefgh
how do you compute
mnofghst ?
How about
unsigned field = Bitpack_getu(abcdefgh, 3, 0);
return Bitpack_newu(mnopqrts, 3, 2, field);


In memoriam Dennis Ritchie
Learning objectives
Office hours cancelled; Tuesday instead.
black-edge removal impressive
Sudoku not so much
image-rotation
blocked arrays
picture the transformations
most wrong: extend the rotation variable, name unchanged
less wrong: 3 variables (rotation, flip, transpose) problem: complex invairants
right: a single 'transformation' of enumeration type
even more right: a single function pointer
Remember, understand, apply
Abstractions & invariants
and a little bit of pointers.
Big transition: from data to code
Project: Defusing a binary bomb (by reverse engineering)
string comparison
read integers with scanf, examine properties
structs linked with pointers







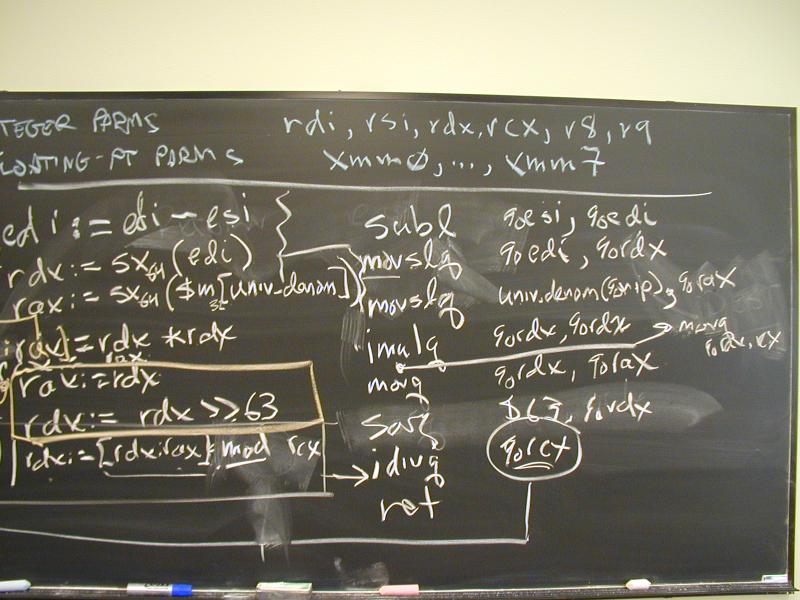

DATA:
CODE:
if, while,
switch)DATA AGAIN:
Parameter registers:
Integral scalars: %rdi, %rsi, %rdx, %rcx, %r8, and %r9
64-bit pointers or integers
32-bit come in %edi and so on
Floating-point scalers: %xmm0 .. %xmm7
Result registers
%rax or %rax/%rdx or %xmm0How to analyze:
Is the value used before it is written?
Infer number and types of parameters
Instructions may be
AMD64 alert: a memory reference can do a little arithmetic in the "address unit"!
Selected machine instructions to be aware of:
shifts mod 64 (shift only by %cl)
lea does address arithmetic and leaves flags unchanged
push and pop access stack implicitly (not much used by compilers)
multiply and divide have LOTS of implicit registers
C code:
extern int universal_denominator;
int sqdiff(int num1, int num2) {
int diff = num1 - num2;
long int sq = (long int) diff * (long int) diff;
return (int) (sq / universal_denominator);
}
Translation:
.globl sqdiff
.type sqdiff, @function
sqdiff:
.LFB2:
subl %esi, %edi -- difference into %edi
movslq universal_denominator(%rip),%rax -- preload denominator
movslq %edi,%rdx -- copy multiplier
imulq %rdx, %rdx -- multiply into %rdx
movq %rax, %rcx -- denominator into divisor register
movq %rdx, %rax -- product into dividend register
sarq $63, %rdx -- copy sign bit into most significant word
idivq %rcx -- divide D/A pair by %rcx
ret -- result is already in %rax
The same function using Register Transfer Language (curly braces contain assertions that hold between assembly-language statements):
{ precondition : num1 == rdi, num2 == rsi }
edi := esi - edi; // subl %esi, %edi
{ diff == edi }
rax := sx64($m[universal_denominator]); // movslq univ_den(%rip),%rax
{ diff == edi, rax == sx(universal_denominator) }
rdx := sx64(edi); // movslq %edi,%rdx
{ diff == edi, rax == sx(univ_denom), rdx == (long int) diff }
rdx := rdx * rdx; // imulq %rdx, %rdx
{ diff == edi, rax == sx(univ_denom), rdx == sq }
rcx := rax; // movq %rax, %rcx
{ rax == sx(univ_denom), rdx == sq, rcx == sx(univ_denom), ... }
rax := rdx; // movq %rdx, %rax
{ rax == sq, rdx == sq, rcx == sx(univ_denom), ... }
rdx := rdx >> 63; // sarq $63, %rdx
{ rax == sq, rdx == signbit(sq), rcx == sx(univ_denom), ...
(therefore rdx:rax == sx128(sq))
}
rax := rdx:rax / rcx | rdx := rdx:rax mod rcx;
// idivq %rcx
{ rax == sq / universal_denominator, rdx == sq % universal_denominator, ... }
return // ret




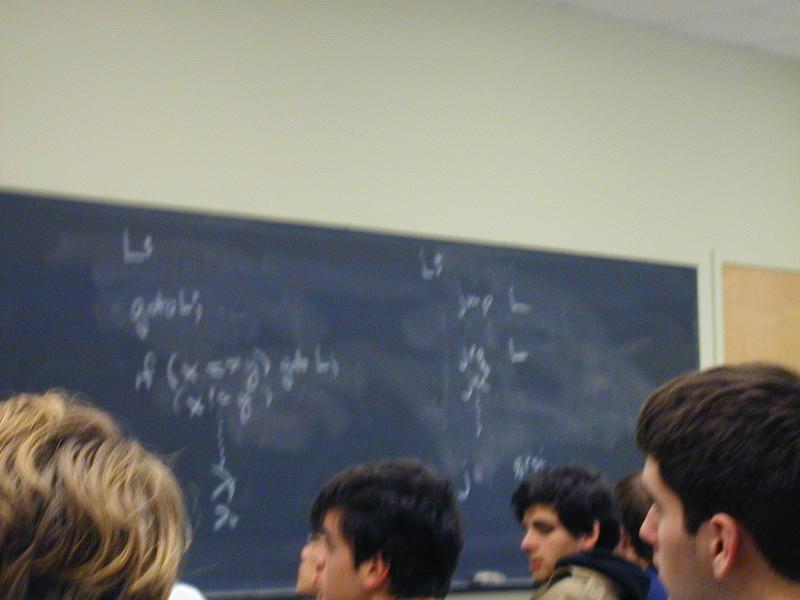


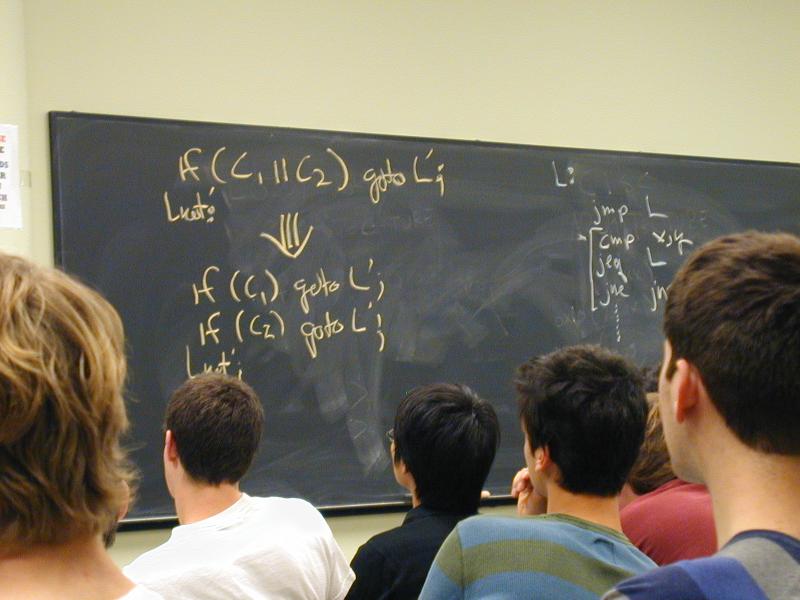
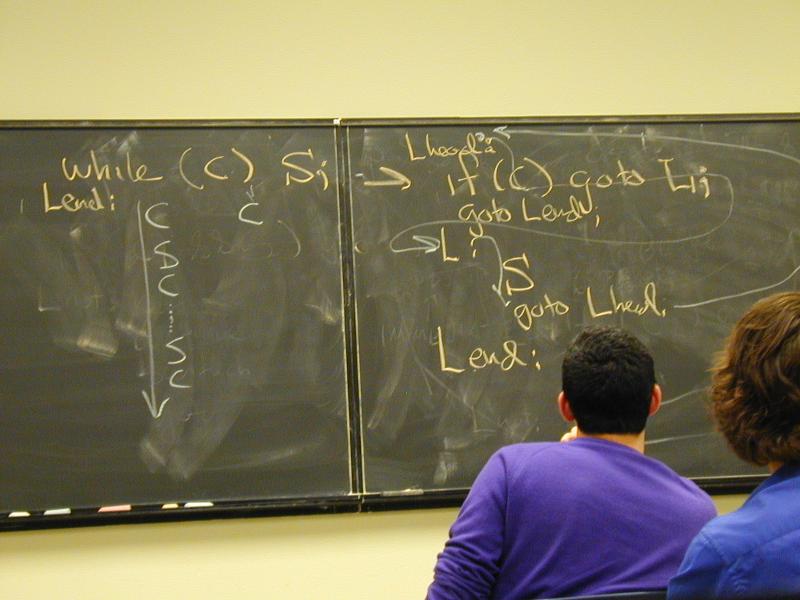
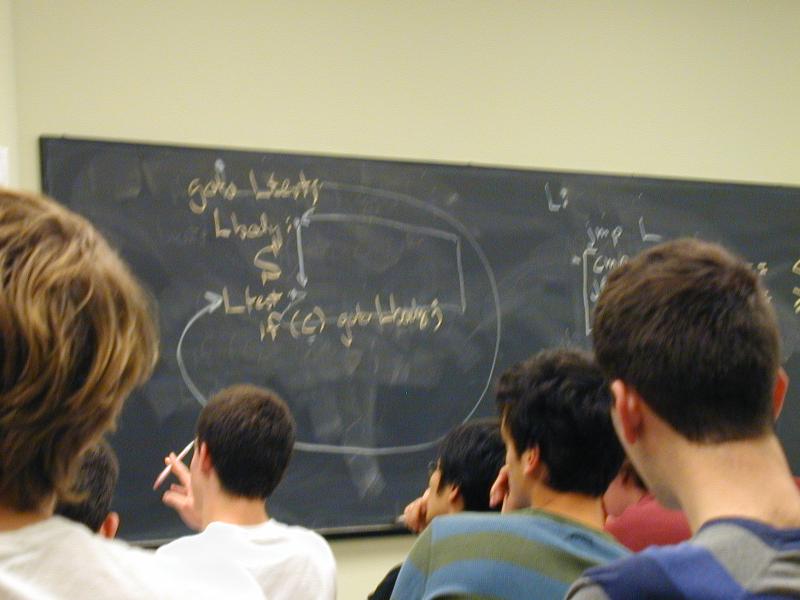
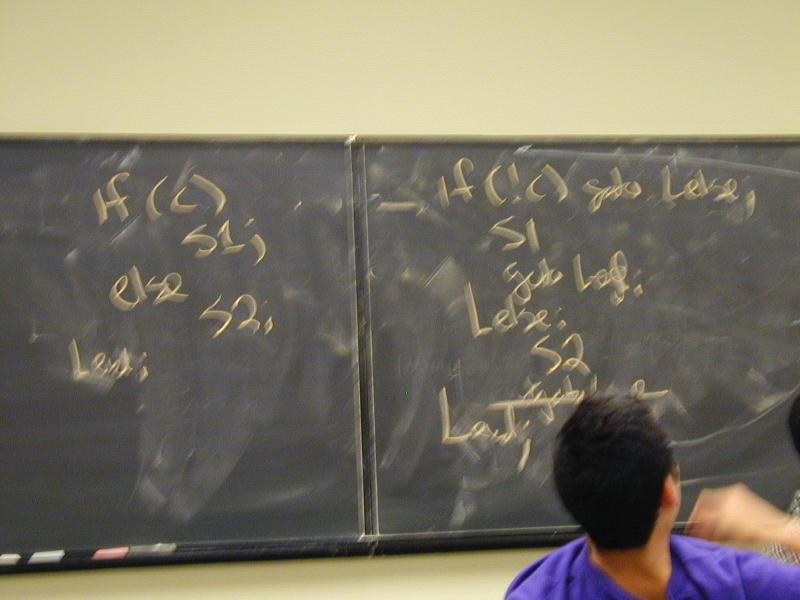
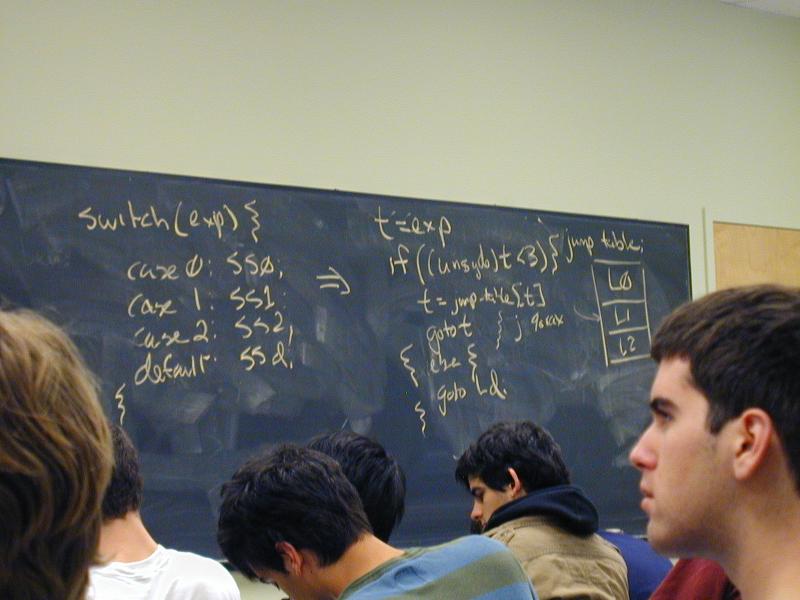

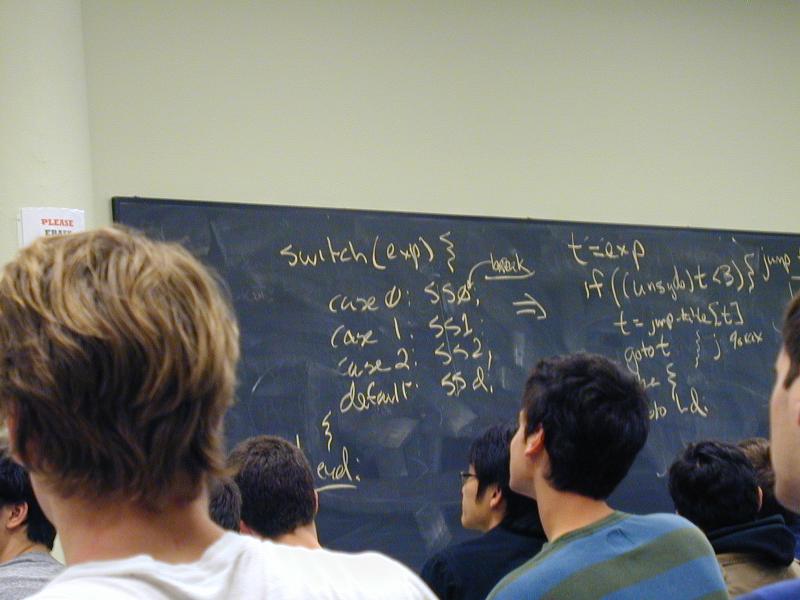
Class exercise: Lowering to normal form
Idea of lasting value: there is always a low-level normal form, and "at most one operator" is typical.
Ephemera: details of the AMD64 (This machine owns the desktop, but the action is going to be in embedded systems. You will encounter other machines.)
All decision making funnelled through condition codes, which Intel calls flags.
Mutated by a cmp or test instruction
Observed by a Jcc or cmov instruction
Flags are set "for free" by many computational instructions --- why?
Four basic tools:
Label (assembly) or address (machine) of instruction---target of a branch
L:
Unconditional branch (jump) to a labelled address
goto L;
Conditional branch depending on flags (they code for conditions,
hence "condition codes"). Combined with test or cmp we have
if (x == y) goto L;
if (x < y) goto L;
And so on for eq, ne, lt, le, gt, ge,
ltu, leu, gtu, geu. Also jo, jno, jc, jnc, others.
N.B. It is easy to negate the condition without introducing new instructions!
Computed branch jumps to an address in a register
j %rsi
Inexpressible in C but supported as a GCC extension.
Basic conditional:
L':
Short-circuit Booleans:
if (C1 && C2) goto L;
becomes
if (!C1) goto Lnot;
if (C2) goto L;
Lnot:
Short-circuit Booleans:
if (C1 || C2) goto L;
becomes what?
How about
while (C) S;
Try Forrest Baskett!
goto Ltest;
Lhead:
S
Ltest:
if (C) goto Lhead;
And also
for (exp1; C; exp2) S;
do S while(C);
Finally
switch (exp) {
case 0: SS0;
case 1: SS1;
case 2: SS2;
case 3: SS3:
default: SSd;
}
...
Uses a jump table (Pidgin C):
static code *jump_table[4] = { L0, L1, L2, L3 }; // addresses
t = exp
if ((unsigned)t < 4) {
t = jump_table[t];
goto t;
} else
goto Ld;
L0: SS0;
L1: SS1;
L2: SS2;
L3: SS3:
Ld: SSd;
Lend: ...
And break becomes goto Lend
In the beginning was FORTRAN. No recursion, no stack!
No excuse for a recursive factorial function, except it makes a good example:
int fact(int n) {
if (n == 0)
return 1;
else
return n * fact(n-1);
}
Q: When fact(4) is calling fact(3), where is n-1?
Q: OK, then where is n?
Q: Where was n on procedure entry?
Q: We have a problem. What's the general shape of the solution?
Attack from a fully general point of view (timeless truth):
Suppose you are computing factorial, or unblackedges, or the binary bomb, or anything else. How many procedures actually are executing in the processor at one time?
What are all the other procedures doing?
Here's the life cycle of a procedure:
The procedure is born when it is first calls.
It is then alive or active.
It may call other procedures.
It runs until it returns or an exception is raised.
Then it's dead.
What's wrong with this picture? Is it adequate to describe factorial?
Suppose we let the program run, and we suddenly freeze it at an arbitrary point:
What is the oldest procedure activation in the system (that we know about)?
What is the youngest activation?
What activations are using the processor and its registers?
What are all the other activations doing?
Refine our idea of state:
Activation may be running
Activation may be suspended at a call site
If f() calls g() calls h(), how are their lifetimes related?
Is there any way that an activation of g() can outlive an activation
of h()?
Yes in other languages, but no in C.
This is why 'return address of a local variable' leads to faults---you are returning a pointer to a dead container.
Therefore, what is the right data structure for activations?
Translation examples:
Special conventions around calls (see handout)
Effective addresses:
Literal constant: $ sign (DDD: without $ sign)
(a "location" by courtesy---immutable)
Memory: address of first byte:
(%rax) // follow pointer
0x10(%rax) // follow (pointer+16)
$0x4089a0(,%rax,8) // global array index multiple of 8
(%ebx,%ecx,1) // add two registers
4(%ebx,%ecx,1) // add to registers offset 4
Q: What is the C type system?
Mappings based on two principles: size and alignment
Example: what is the difference between
struct rgb { unsigned red; unsigned green; unsigned blue; };
and
unsigned pixels[3];
(In DDD, to inspect contents of arrays (and sometimes structs), use the
Memory...tool on theDatamenu.)
Example: how is a linked list of unsigneds represented?
struct node {
unsigned val;
struct node *next;
};
Q: What C could lead to the addressing mode 4(%ebx,%ecx,1)?









A Turing-complete machine in 14 instructions
Why the Universal machine?
Learn to distinguish binary machine code from assembly code
Learn how a sensible binary instruction set works
Possibly learn what the assembler and linker do
Possibly write a little assembly code
Finally, processor emulation interesting in its own right
(distant cousin to Java Virtual Machine)
A 32-bit machine:
A segmented memory architecture:
Most resembles the Intel 8086 (first IBM PC)
Access to any memory element requires two registers:
"segment" register
offset within the segment
Segmentation was used on the first IBM PC (foundation of Microsoft's success), but it is now out of fashion
Word-oriented, RISC instruction set architecture
No byte instructions; smallest addressable unit is the word (Like CRAY-1 supercomputer)
All computation in registers, pure load/store (RISC)
Every instruction is 32 bits wide (RISC) --- can find "next instruction" without decoding current instruction
Only two binary machine-code formats (RISC) --- very fast instruction decoding
Computational capabilities deliberately limited:
Simpler to implement and debug
Limitations can be worked around by a compiler or Macro Assembler
Purpose is partly instructional, e.g., learn how to implement subtraction in terms of other operations
No floating-point operations
Instruction set
Computation: Add, multiply, divide, NAND
Data movement: load and store from segment, load value
Control flow: computed goto ("run instruction in segment")
Decision-making: conditional move
Create and destroy segment (activate and inactivate)
Input and output
Halt
Keep representation of machine state:
Contents of 8 registers
Contents and sizes of 1 or more segments; segment 0 is always the program
Value of the program counter
Interface: given an initial 'segment 0' (binary program), run until
reaching a halt instruction, then return.
Asking for a more modular design:
UM execution should be a standalone component with its own API
UM loading (from a file) should be a standalone component
main() should be almost empty---just stitch together
The biggest design task is simulating segments



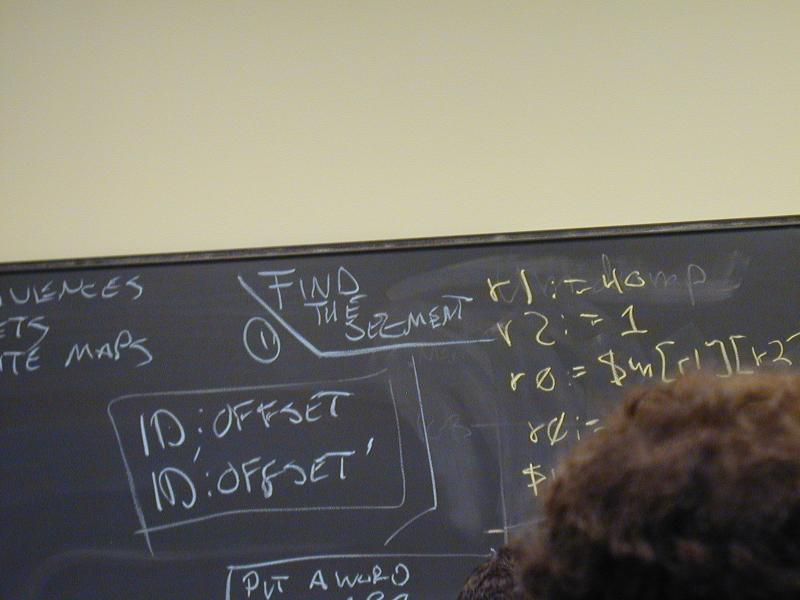




Representation is still the essence of programming.
Let's look at the data in the problem:
Universal Machine word (uint32_t or int32_t)
Universal Machine segment (sequence of words of fixed size)
Up to three representations:
Questions:
Which pairs of representations can be the same?
Which modules should know about which representations?
Set of segment IDs partitioned into mapped and unmapped subsets
Segment mapping (from mapped IDs to segments)
Universal Machine general-purpose registers
Universal Machine program counter
Universal Machine instructions
Representation within a segment is fixed
Representation used in emulator can be chosen freely
What invariants are true even in the world of ideas (about the abstractions)?
Which modules should know about which representations?
Which representations should be public?
Which representations should be private?
World of ideas:
Q: An active 32-bit identifier is associated with what?
We have a bijection between active identifiers and sequences
Q: How is the bijection used and changed by the instruction set?
Q: When an identifier makes the transition from active to inactive, what happens to its sequence?
World of implementation
How is a 32-bit identifier represented?
How can we distinguish active from inactive identifiers?
How is a sequence of mutable 32-bit locations represented?








Here is what I expect for the Universal Machine:
README to document the architecture of the system. Each interface may get a short description, but no more.
Rule of thumb: data types may be mentioned (in the world of ideas) but functions should not be mentioned.
Each interface to be documented with
Overall header comment briefly explaining
The general purpose (in many cases one line is enough)
The declared data types and what they stand for in the world of ideas
General knowledge needed to understand and use the interface (e.g., references to man pages or other info), if any
Well-chosen names!! (critical form of documentation)
Short documentation for each function. Aim for about one line per function---but recognize that sometimes it is clearer to document a small group of functions and let the names and types speak for themselves.
Don't forget to document the element types of arrays!!
Each implementation to be documented with
Descriptions for each declared type and global variable. What does it represent in the world of ideas? What are its invariants?
Descriptions of any functions private to the implementation:
These functions should have prototypes and be declared
static
The prototypes should be documented in much the same way as the function prototypes in a .h file
Bodies of functions should be documented only where code is tricky, long, or difficult to understand. Most of you are getting this part right already.
Much simpler modular structure than image compression
Existing modules including Bitpack, Seq, Array, Table,
and so on. Ample choices available.
A module to manage UM memory access
A module to run UM codes (execution phase)
A module to isolate the secret of the on-disk format
Some main functions
Documentation:
Stratify into three layers: architecture, interfaces, implementations.
Internal functions should be static and be documented like
interface functions, but not inline without good reason.
(Usually the compiler makes good inlining decisions on static
functions.)
Don't forget to try compiling with both -O1 and -O2 to see
about your performance target---mention results in README
Code:
You have a lot of freedom to change design decisions within modules.
An important aspect of modular reasoning is to identify design decisions that are likely to change. Many of you have already done so, especially around UM segments. I want those decisions hidden behind a layer of abstraction.
Otherwise, I'm mainly looking for good names:
There are a lot of numbers in binary code. The number 3 means something different depending on whether it occurs in opcode position, in register position, or in value position (in the Load Value) instruction. I expect you to use distinct names in your code. Where you need to, define enumeration types.
(Remember the example of the seven image transformations.)
Make sure your naming conventions distinguish the name of a container (register 3) from the contents of that container (the integer 17, a 32-bit segment identifier).
If you choose to define auxiliary functions, remember modular reasoning, and be sure that you separate these two concerns:
Instruction decoding
How the segmented memory unit works
For example, if you have an auxiliary function that finds a
memory location, its parameters should be called segment
register and offset register, not rB and rC. In fact,
the segmented load and store instructions
don't even use the same registers!








3 people using editor
many people shackled to the mouse
statistical analysis to come later, but we are looking for your best times, not your average or total time
Programmers, break your chains! Kill the mouse.
Notes on functional correctness:
Many struggles with Bitpack, and not just corner cases---half the class earned the lowest passing grade.
Not everyone understands the notion of 'fits in N signed bits'; expect to see a question on the final exam
Notes on structure and organization:
Most of you can structure a small module well (Bitpack)
Most of you struggled to structure the image compressor---40% of the class earned the lowest passing grade
The Universal Machine is intermediate in difficulty
We have high expectations for the Universal Machine
Lessons:
Many of you seem to overlook that half your grade is on the structure and organization of your code.
TAs continue to report many sightings of completely undocumented code. This means you are leaving half your grade on the table until the last minute.
This is not just a matter of your grade. Trying to debug ugly, undocumented code is like trying to work in my office---nearly impossible because there's mess everywhere and you can't find anything.
I don't enjoy handing out C's, but I know you can do much better than what you're doing.
Transformation of code to improve readability and internal structure.
A huge thing in industry.
Simpler is better.
Some ideas:
Suggested procedure for refactoring:
Work with your programming partner
When session is over, print out code
Each of you can review code on printout
At next meeting, discuss proposed revisions and simplifications
Implement the best ones
Example: Bitpack_newu in 21 lines:
uint64_t Bitpack_newu(uint64_t word, unsigned width,
unsigned lsb, uint64_t value) {
if (width + lsb > 64) {
RAISE(Bitpack_Overflow);
}
if(!Bitpack_fitsu(value, width)) {
RAISE(Bitpack_Overflow);
}
uint64_t one = 1;
uint64_t filter = shift_left64(one, width) - 1;
filter = shift_left64(filter, lsb);
uint64_t result = word & (~filter);
uint64_t insert = shift_left64(value, lsb);
result = result | insert;
return result;
}
Simplified version in 11 lines:
static uint64_t one = 1; // can be shared among multiple procedures
uint64_t Bitpack_newu(uint64_t word, unsigned width,
unsigned lsb, uint64_t value) {
if (width + lsb > 64 || !Bitpack_fitsu(value, width))
RAISE(Bitpack_Overflow);
uint64_t mask = shift_left64(one, width) - 1;
mask = ~shift_left64(mask, lsb);
return (word & mask) | shift_left64(value, lsb);
}
Factors of two matter!!
Fits in signed bits, fits in unsigned bits: arithmetic and visual
Visual: unsigned, excess high bits must be zero
Visual: signed, excess high bits must be copies of the sign bit
New term: mask








New Learning outcomes:
Performance targets:
How fast is fast enough?
Tufts dining services: how long to scan your card? Would doubling speed be of any benefit?
Unblack-edges: If it takes 30 seconds to scan a page, is an additional second to unblack edges a problem? What about an additional 30 seconds per page?
First & 2nd rule of performance optimization (Michael Jackson)
Don't do it
Don't do it yet
The "bank robbery" model of code tuning:
Q: Mr Sutton, why do you rob banks?
A: That's where the money is.
A law of mathematics that says if input takes only 5% of a program's execution time, than even if you make input infinitely fast, you speed up the whole system by at most 5%. The full version of Amdahl's Law tells you exactly how to calculate the speedup of the whole from the speedup of a part.
Amdahl's law tells you that there are certain parts of a program which it is a waste of time to try to make faster.
80% of the time is spent in 20% of the code
80% of the profile area occurs in 20% of the boxes
80% of the available speedup can be achieved by tuning just 20% of the code
The 80/20 rule is not true all the time, but when it is true, it's worth taking advantage of.
kcachegrind demo
Two samples from student black-edge removers: slowest and fastest
Total time on scanned image: 2.36s vs 3.86s. One is 63% slower.
valgrind --tool=callgrind reports 9.06 billion instructions
for the fast one, 12.4 billion for the slow one. One takes 37%
more instructions (note difference!).
fast one spends 71% of its time in bitToFile, and 67% of total
time in fprintf. Suggestions for speedup?
slow one spends 86% of time in Bit2maprowmajor. Call graph shows two children totalling 79%. So mapping overhead is 6%, but what about printPixel? Time split between Bit2get and fprintf.
NR's code total time is 1.02s. (NR has a better algorithm, running only 4.12 billion instructions.)
Idea based on main call graph: speed up pbmread by providing an 8-bit-wide interface?
Functions/procedures as the units of profiling
valgrind and cachegrind report on functions, so that's our first
unit of thought. There are three ways to make a function take less
time (== less area on the visualization):
Call it less often
Make the function run faster
Specialize the function (to be explained later)
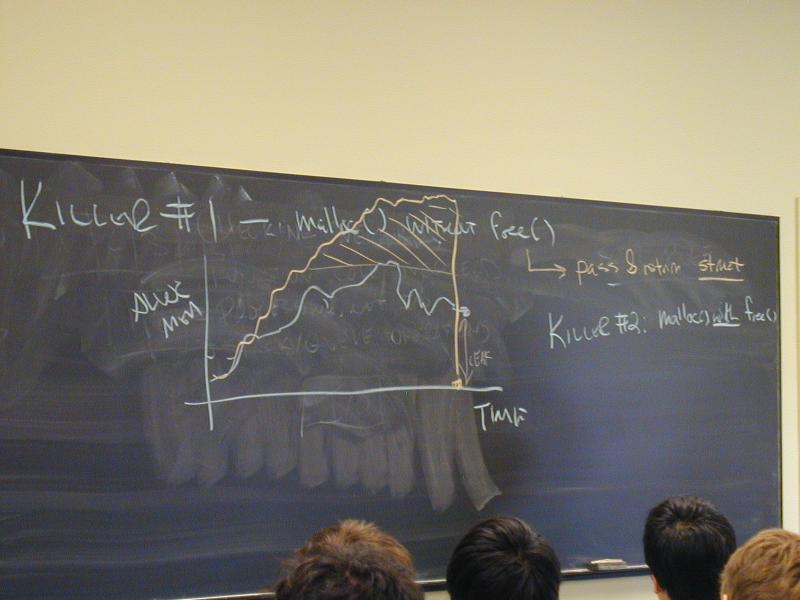
The biggest killer is malloc() without free().
This may occur two ways:
A memory leak discards pointers to live heap objects
without freeing them first. Leaks can be detected using
valgrind.
Data structures that grow without bound also kill
performance. You can discover a problem like this by running
valgrind and interrupting it (with control-C) to see how
much memory is in use. If this number continually gets
larger as your program runs for more time, you have a problem
with unbounded growth.
You can also monitor memory usage using the htop program;
press F6 and sort by VIRT (virtual memory).
Digression: this problem is unique to C and C++ and other
languages of similar vintage (e.g., Modula, Ada, Pascal).
Civilized languages provide automatic memory management, in
which the system figures out when the contents of a heap object
can no longer affect any future computation, then frees the
object automatically, making it available to satisfy future
allocation requests. The simplest and most performant
implementation of automatic memory management is called "garbage
collection", and this technology has been adapted to C in the
form of "conservative garbage collection", implemented and
maintained by Hans Boehm. You are welcome to try out this
technology on your homework; once the Boehm collector is
installed on the system, you can try linking with -lgc,
although for best performance you will also find it helpful to
consult the documentation.
Note that garbage collection only helps you recover from leaks: if your data structures grow without bound, the contents of those data structures could conceivably affect the results of some future computation, so they are not reclaimed by the collector.
The second biggest performance killer, of a lower order, is
malloc() with free(). It is true across languages that
allocating a heap object is among the most expensive things you
can do. Because of technology trends, this is likely to remain
true for some time.
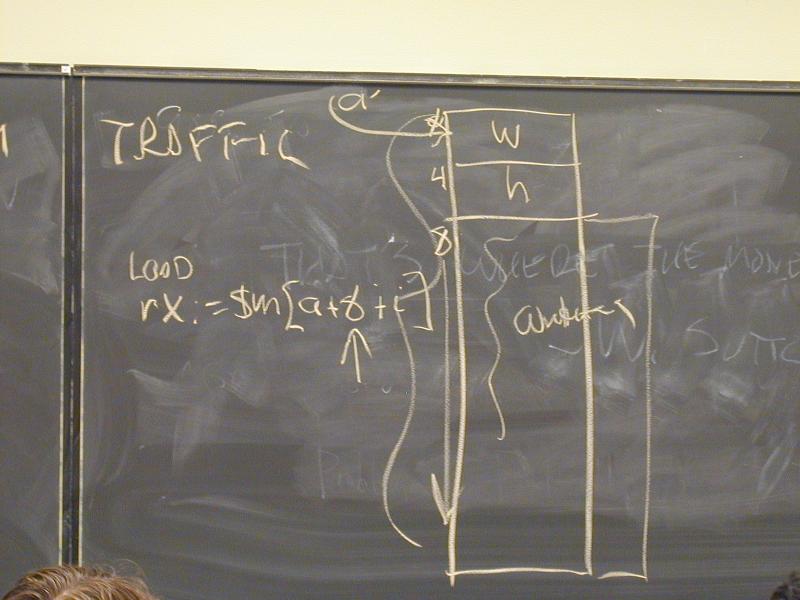
The third performance killer is loads and stores---memory traffic. Example: here's a relatively efficient representation of two-dimensional arrays:
struct Array2_T {
int width, height;
char *elements;
};
(Draw the representation)
To get to an array element i, you have to dereference two pointers
and do address arithmetic twice (one address is static and is
coded into the instruction; the other is dynamic):
a->elements[i] // same as *((*a).elements+i)
Now here's a trick:
struct Array2_T {
int width, height;
char elements[];
};
(Draw the trick): the C code is the same, but what happens at the machine level is quite different: it requires only one pointer dereference and one arithmetic (again done in the address unit):
a->elements[i] // something like *(a + offset(elements) + i)
To allocate the first kind of array:
struct Array_T *p = malloc(sizeof(*p));
p->elements = malloc(n * sizeof(*p->elements));
To allocate the second kind of array:
struct Array_T *p = malloc(sizeof(*p) + n * sizeof(*p->elements));
The advantages:
One heap object, not two
Created by one malloc(), not two
Element access with one load, not two
The disadvantage:



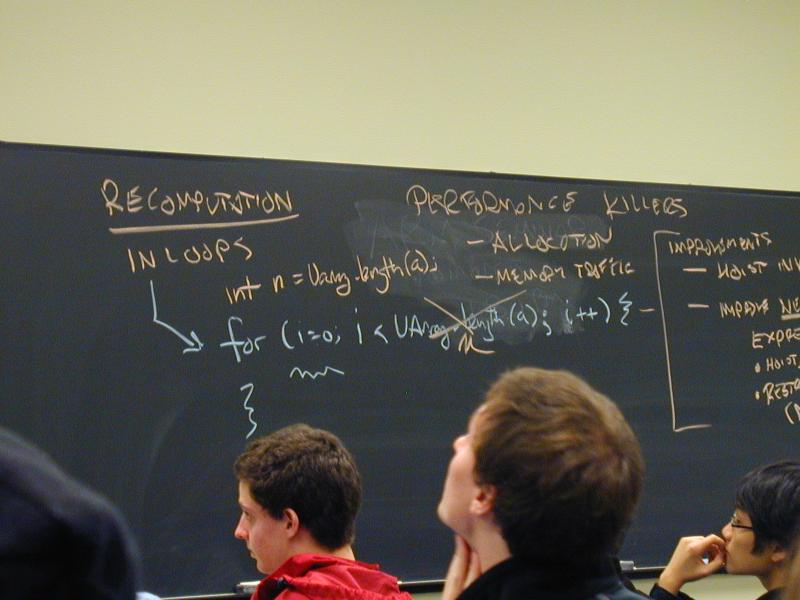


Fundamental principles:
Go where the money is (Amdahl's law)
You don't know where time is being spent, so use a profiler
You have both a code play and a data play
Profilers give excellent support for a code play
Profilers give poor support for a data play---no way to aggregate "all functions that know the secret of this representation", so you have to put together the picture yourself
Performance killers:
Allocation (especially if not freed)
Memory traffic (reduce levels of indirection, a data play)
More killers:
The fourth performance killer is some function calls.
Calls to small functions cost you two ways:
The overhead of the call may be equal to the cost of the body (less true on AMD64, where many parameters are passed in registers, but very much a concern on IA-32)
The call has indirect costs:
The volatile registers are essentially "lost" near the call site.
The compiler assumes any value in memory may be destroyed.
Larger functions can amortize these overheads; small ones cannot.
Calls to functions with compile-time constant arguments often benefit from being specialized to those arguments. This usually means inlining as well.
The fifth performance killer unnecessary recomputation in loops.
Example
for (i = 0; i < Array_length(a); i++) { ... }
The programmer knows that Array_length(a) is invariant.
The compiler does not.
Example: call to a function, some of whose arguments are the same for each loop iteration. Solution: inline and specialize.
Example (exercise): row major map through elements of 2D array.
Also, recomputation of near-invariant values in loops, e.g., recompute the row at every pixel, but the row almost never changes.
The sixth performance killer is control flow, especially
conditional branches. Anytime you can use pure arithmetic or
persuade the compiler to generate a cmov instruction, you win.
Arithmetic is free, except possibly for integer divide. (Maybe integer multiply costs a little, too.)
What to do with the following:
struct T {
int width, height;
int size;
UArray_T elements; /* UArray_T of 'height * width' elements,
each of size 'size', in row-major order */
// Element (i, j) in the world of ideas maps to
// elements[i + width * j], where the square brackets
// stand for access to a Hanson UArray_T
};
void UArray2_map_row_major(struct T *a2,
void apply(int i, int j, struct T* a2, void *elem, void *cl), void *cl) {
assert(a2);
for (int k = 0; k < a2->width * a2->height; k++) {
int col = k % a2->width;
int row = k / a2->width;
apply(col, row, a2, UArray_at(a2->elements, k), cl);
}
}
Conclusions:
Whether single or double loop, pulling out invariant expressions saves two loads and one multiply.
The more clever transformation is to introduce a nested loop.
For the loop overhead, Amdahl rides again:
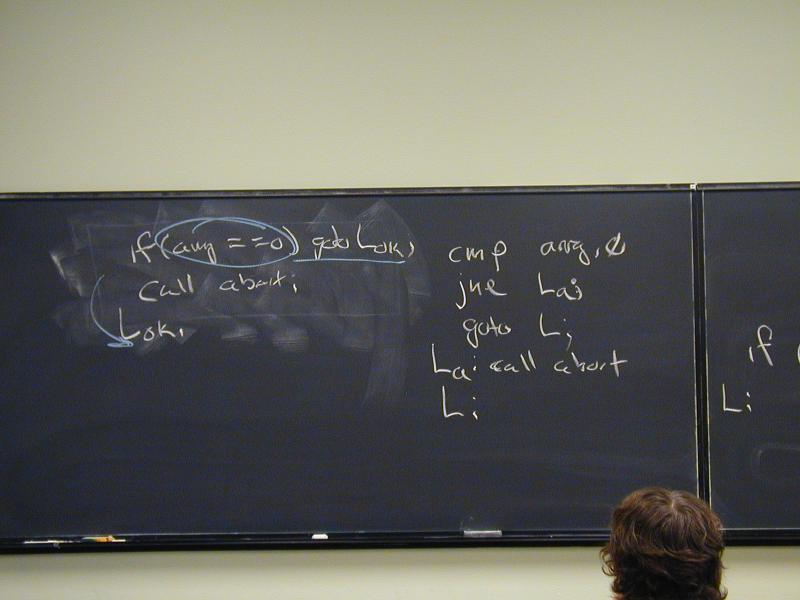


Where have we been & where are we going?
Last week: code tuning
Today: more depth on code tuning
Future: actually programming the Universal Machine:
Macro Assembler (e.g., implement subtract in software)
Write a simple RPN calculator
How does function-call overhead compare for Array_get vs
Bitpack_getu?
Key knowledge: the cost of assert()
Class exercise!
What's to be gained here by inlining Array_get(segment, r4)?
void *Array_get(T array, int i) {
assert(array);
assert(i >= 0 && i < array->length);
return array->array + i*array->size;
}
And what's to be gained here by inlining Bitpack_getu(instr, 3, 6)?
static inline uint64_t shl(uint64_t word, unsigned bits) {
assert(bits <= 64);
if (bits == 64)
return 0;
else
return word << bits;
}
static inline uint64_t shr(uint64_t word, unsigned bits) { // shift R logical
assert(bits <= 64);
if (bits == 64)
return 0;
else
return word >> bits;
}
uint64_t Bitpack_getu(uint64_t word, unsigned width, unsigned lsb) {
unsigned hi = lsb + width; // one beyond the most significant bit
assert(hi <= 64);
return shr(shl(word, 64 - hi), 64 - width); // different type of right shift
}
What operations need to be fast? (Profile and count!)
What operations can be omitted?
Can you specialize the abstraction or change a data structure or algorithm?








Getting from source to machine code: deepen and consolidate your knowledge
The assembler accumulates relocatable object code in a sequence of named sections.
You handle named sections
I handle label definitions and references to labels not yet defined
Typical sections for real hardware:
'text' (machine code)
read-only data (string literals, floating-point literals, etc)
read/write data (global variables)
bss data (global and static variables that are initially 0)
Simple program:
int main() {
puts("Hello, world\n");
return 0;
}
.rodata
L17:
.byte 'H'
.byte 'e'
.byte 'l'
.byte 'l'
.byte 'o'
.byte ','
.byte ' '
.byte 'w'
...
.byte '\n'
.byte 0
.text
main:
%rdi := L17 // mov L17, %rdi
call puts
%rax := 0
retq
Label definitions that are remembered
Relocation entries
What happens in init, text, rodata?
Not shown: who calls main???
start:
set up call stack
<get argument string from operating system>
build argv and compute argc
rc = main(argc, argv);
exit(rc);
Typical sections for Universal Machine:
'init' (code that runs to set up for procedure calls, main code)
'text' (machine code)
'data' (global variables)
'stk' (call stack)
Your assembler is agnostic about the identity of sections (more modular reasoning)
In the UM Macro assembler, the first section is always init
We will not translate start code, but we know it is in the
init section.
State includes the input read so far
Fundamental data structures:
A list of sections
A current section
Invariant (sections in the assembler):
The list of sections L relates to the input read in the following way:
Consider the name of the initial section, followed by each
name mentioned in a .section directive, in order.
The list L is a list of those named sections, in order of first appearance, with duplicates removed.
Q: What needs to be done to establish and maintain this invariant?
What is the list when the assembler is first created?
Does the list change whan anything not a .section is read?
What happens to the list when .section is read?
Relevant parts of the interface:
T Umsections_new(const char *section,
int (*error)(void *errstate, const char *message),
void *errstate);
/* Create a new assembler which emits into the given section.
The error function, which is called in case of errors,
is guaranteed not to return.
*/
void Umsections_section(T asm, const char *section);
/* make the named section current, creating if needed */
void Umsections_emit_word(T asm, Umsections_word data);
/* Emit a word into the current section */
Invariant (the current section):
The current section is the section named in the most recently
read .section directive, or if no .section directive has been
read, it is the initial section named in the call to
Umsections_new().
Q: What needs to be done to establish and maintain this invariant?
What is the current section when the assembler is first created?
Does the current section change whan anything not a .section is read?
What happens to the current section when .section is read?
Definition: a word is emitted into a section if that word is emitted while the section is current.
Invariant (contents of a section):
The contents of a section consists of all the words ever emitted into that section, in order.
Q: What needs to be done to establish and maintain this invariant?
Umsections_emit_word?The link phase retires all the outstanding relocation entries. If a relocation entry cannot be retired (because the definition of a label is missing), the linker calls the error function:
When all entries have been discharged, a binary can be written:
void Umsections_write(T asm, FILE *output);
/* Write the contents of each section stored in asm,
in the order in which they appear in asm's sequence.
Write the words to file 'output' in UM format.
*/







Points of emphasis:
Pair programming with course staff?
What do you know now that you needed to know by the end of September?
In metaphor:
The Universal Machine can do only 14 things
The assembler core is a little smarter, it can do 20 things
The full assembler is even smarter; it can do many things
Goal: umasm is easier to talk to, because it understands more. It is easier to write code for the Macro Assembler than to create UM code directly.
Technically, what appears to be one instruction expands to a sequence of instructions:
User-defined macros appeared in 1960s, for hand-written assembly code
Also useful to work around limitations in architecture (first widely used example, MIPS assembler in mid-1980s)
Example limitations:
UM cannot load an arbitrary 32-bit value into a register
UM cannot represent
r3 := r4 + 12
instead, UM must write
r3 := 12
r3 := r4 + r3
Some macro instructions require temporary registers:
r3 := r3 + 1 // cannot assemble this
but
r3 := r3 + 1 using r5
becomes
r5 := 1
r3 := r3 + r5
It's also possible to designate temporary registers permanently:
.temp r5
r3 := r3 + 1
r4 := r4 - 1
Most 'load program' instructions use array 0. Can be convenient to keep 0 in a register. If so, let the assembler know. Instead of
r0 := 0
r1 := L8
goto *r1 in program[r0]
we can do
r0 := 0
.zero r0
goto L8
The .zero is a promise to the assembler.
More macros for control flow
.temps r5, r6, r7
// compute absolute value
if (r1 >=s 0) goto L // uses many temporaries
r1 := -r1
L:
The .temps gives the assembler the right to destroy the
registers.
No procedures, just code:
.zero r0
.temps r7
L:
r1 := input()
r2 := ~r1 // macro instruction
r3 := exit
if (r2 != 0) r3 := write
goto r3
write: output r1
goto L
exit: halt
The goto is a macro instruction that Santa expands as follows:
r0 := 0 // Load Value instruction
r1 := L // load relocatable address
goto *r1 in program m[r0] // Load Program instruction
Six macro instructions:
typedef enum Ummacros_Op { MOV = LV+1, COM, NEG, SUB, AND, OR } Ummacros_Op;
/* move, one's complement (~), two's-complement negation (-),
subtract, bitwise &, bitwise | */
The corresponding assembly code:
r1 := r2 // MOV (move)
r1 := ~r2 // COM (one's complement)
r1 := -r2 // NEG (negate)
r1 := r2 - r3 // SUB (subtract)
r1 := r1 - r2 // SUB (subtract)
r1 := r2 & r3 // AND
r1 := r2 | r3 // OR
Instruction emission just as in the lab on UM unit testing: emit instructions into a sequence:
void Ummacros_op(Umsections_T asm, Ummacros_Op operator, int temporary,
Ummacros_Reg A, Ummacros_Reg B, Ummacros_Reg C);
void Ummacros_load_literal(Umsections_T asm, int temporary,
Ummacros_Reg A, uint32_t k);
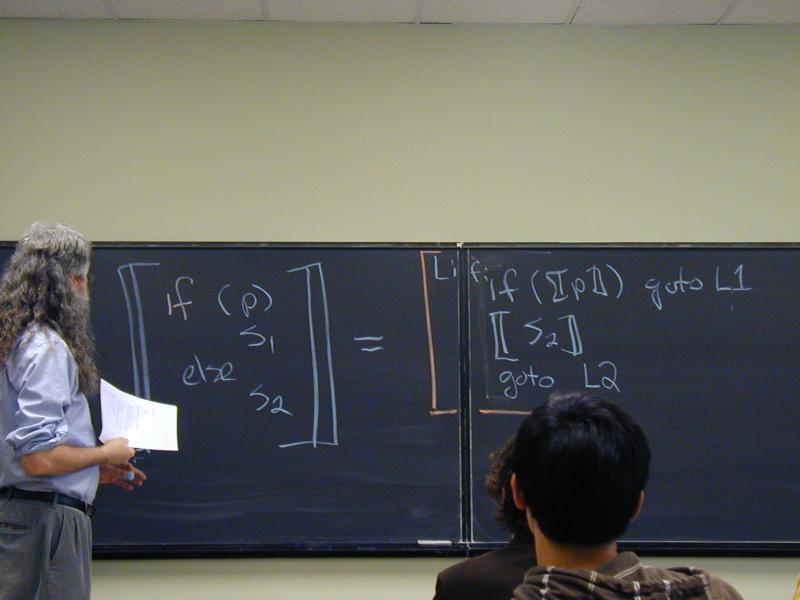

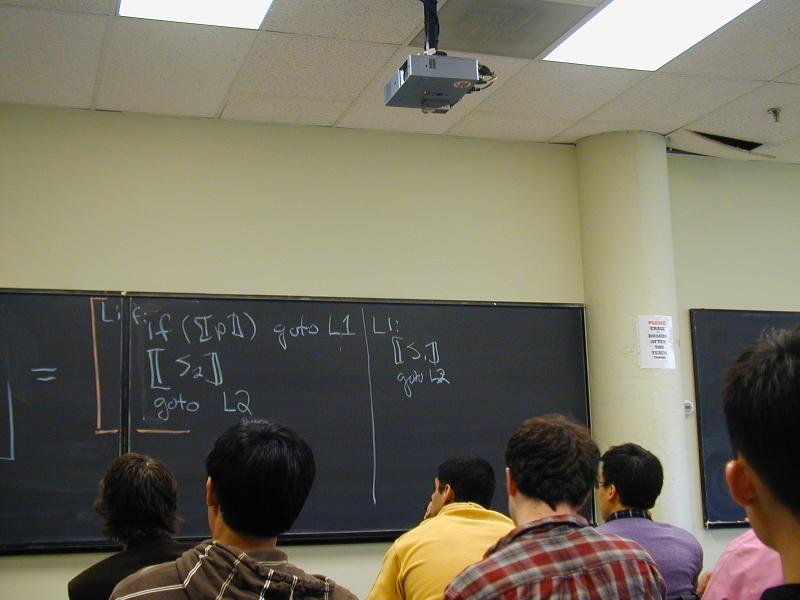











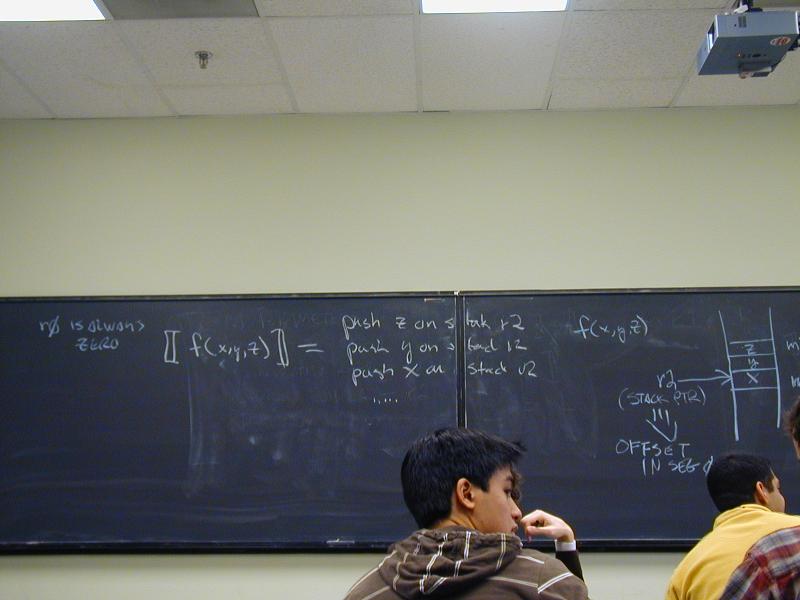

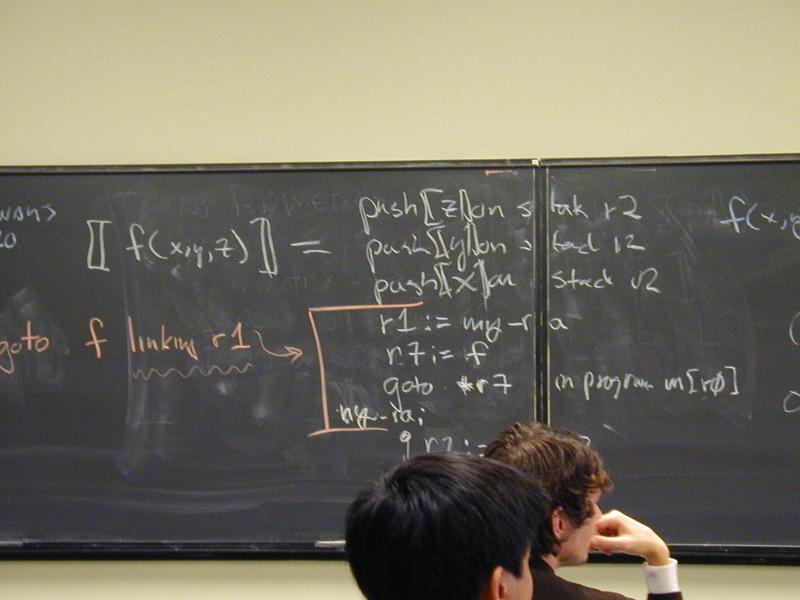
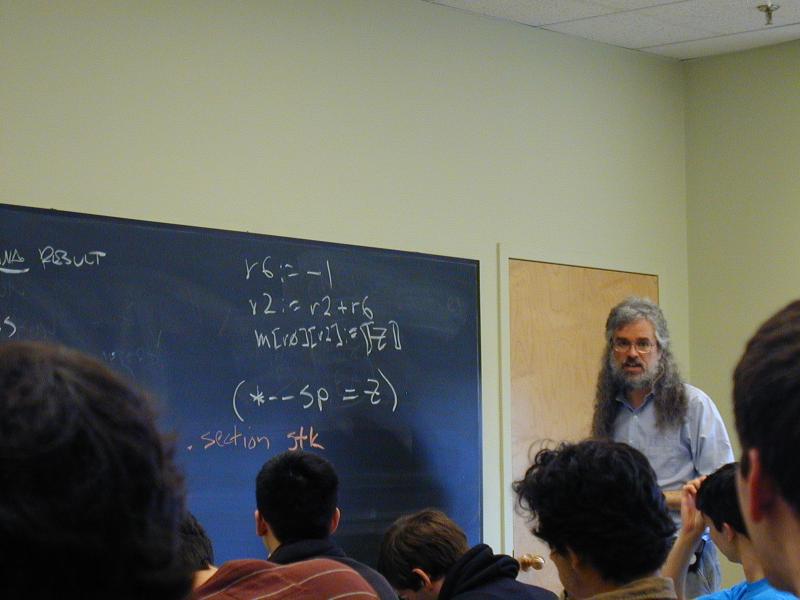
Half of the image-rotation codes were broken (No Credit for wrong answers fast)
Ten Universal Machines failed on one or more test cases, but here there was no way for you to know. I have repaired a few faults, but faults I could not repair were marked Excused. I will correct what faults I can, but if I can't correct one, then it never happened.
SPEED DEMON achievement
You have everything you need, but for some of it, maybe you could use a refresher. Tally votes on
Review of procedure calls from last time
Example of a recursive function in assembly code
Review of lowering for switch statements
Recommendation for switch statement in RPN calculator
Explanation of the RPN calculator
Remember:
Lowering of if
Lowering of while
Lowering of switch
What do we need for a procedure call?
Salient fact: not enough registers
What do we need to know about calling conventions?
Register conventions:
goto and for the
call stack)Compiler trick: if we need registers, save and restore r3, r4 on stack
What does a call instruction look like?
Must transfer control while capturing return address in register r1.
What ideas do you have?
The idea "call main if r6, r7 are temporaries and r0 is 0"
translates to
Translates to
r1 := this_ra // Load Relocatable (LV)
r7 := main // Load Relocatable (LV)
goto *r7 in program m[r0] // Load Program
this_ra: // labels next instruction
My front end accepts this code:
goto main linking r1 // goto main, setting r1 to the return address
Q: Why is it good to put the return address in a register and not on
the stack?
A: "Optimized leaf routines" can run without a stack---sometimes
without any data traffic at all.
Here's what startup code looks like (equivalent of crt0.o):
.section text
.zero r0
.temps r6, r7
start:
goto main linking r1
halt
We still need a stack:
How to allocate and initialize the call stack (equivalent of crtN.o):
.zero r0
.section stk
.space 100000
endstack:
.section init
r2 := endstack
Parameter passing: on the stack
m[r0][r2+0] // first parameter
m[r0][r2+1] // second parameter
Q: Why is the call stack in segment 0?
A: So we don't have to burn a two registers to point to it
Macro instructions for the stack:
.zero r0
.temps r6, r7
push r3 on stack r2 // what does it expand to?
r6 := -1 // macro instruction; implementation elided
r2 := r2 + r6
m[r0][r2] := r3
And also pop:
pop r3 off stack r2 // what does it expand to?
r3 := m[r0][r2]
r6 := 1
r2 := r2 + r6
These instructions can be used to save and restore registers.
If the return address is in a register, how are we going to implement a recursive function?
Answer: save it on the stack.
Here is a skeleton for any procedure:
proc:
push r1 on stack r2 // save return address
// where is the first parameter now?
// it's at m[r0][r2+1]
... // do many things
r1 := the return value
pop r5 off stack r2 // OK to overwrite r5; it's volatile
goto r5 // passes for a return
Notes:
Having at least one volatile register is key.
From the caller's perspective, the stack pointer does not move. (Common C convention, not a requirement)
We have
fact(n) = if n == 0 then 1 else n * fact(n-1)
Questions:
n?Because the parameter n is live across the recursive call,
we'll keep it in a nonvolatile register. This means we must
save and restore the register. (I've chosen r3.)
fact:
push r1 on stack r2 // save return address
push r3 on stack r2 // save nonvolatile register
r3 := m[r0][r2+2] // first parameter 'n'
if (r3 == 0) goto base_case
// recursive call
r5 := r3 - 1 // OK to step on volatile register
push r5 on stack r2 // now 'n-1' is a paraemter
goto fact linking r1 // make the recursive call
pop stack r2 // pop parameter
r1 := r3 * r1 // final answer
goto finish_fact
base_case:
r1 := 1
finish_fact:
pop r3 off stack r2 // restore saved register
pop r5 off stack r2 // put return address in r5
goto r5 // return
Try this
void main(void) {
for (int i = 10; i != 0; i--) {
print_d(i);
puts("! == ");
print_d(fact(i));
putchar('\n');
}
return
}
Output is
10! == 3628800
9! == 362880
8! == 40320
7! == 5040
6! == 720
5! == 120
4! == 24
3! == 6
2! == 2
1! == 1
Assembly code is
main:
push r1 on stack r1
push r3 on stack r2
r3 := 10
goto main_test
main_loop:
push r3 on stack r2
goto print_d linking r1
pop stack r2 // pop parameter
output "! == "
push r3 on stack r2
goto fact linking r1
push r1 on stack r2
goto print_d linking r1
r2 := r2 + 2 // pop 2 parameters
output '\n'
r3 := r3 - 1
main_test:
if (r3 != 0) goto main_loop
pop r3 off stack r2
pop r1 off stack r2
goto r1
Left as an exercise
Register conventions:
goto and for the
call stack)Macro instructions that help with calls
...
goto f linking r1
...
f:
push r1 on stack r2
push r3 on stack r2
...
pop r3 off stack r2
pop r5 off stack r2
goto r5
Midterms: criteria 1 depth + 2 competence = 25pts + 2*10pts = 45 pts
Midterm grade ranges:
65+ Excellent
45-64 Very Good
37-44 Good
25-36 Fair
under 25 Poor
Work needed on
Defining abstract types
Contracts vs invariants
Calculations with cache
Properties of COMP 15 data structures
Expect to see all this on the final
I apologize for question 8; sometimes a new question just doesn't work.
Dramatic improvement over midterm performance will be noted
Contract vs invariant: length of heap