The function condense turns lists of lists of things into lists of things. Here are some functional examples:
(check-expect (condense '((1 2) (3 4 5) () (6 7)))
'(1 2 3 4 5 6 7))
(check-expect (condense '(("Dear") ("Mr" "Ramsey") ("your" "frog" "died")))
'("Dear" "Mr" "Ramsey" "your" "frog" "died"))Using the parametric data definition for lists, write a signature, purpose statement, and header for condense.
Here is a self-referential data definition:
A
number-bst(binary search tree of numbers) is either:
falseA structure
(make-node left key value right)where
keyis a string,valueis a number,leftis anumber-bstin which allkeys are less than this key, andrightis anumber-bstin which allkeys are greater than this key.An
image-bst(binary search tree of images) is either:
falseA structure
(make-node left key value right)where
keyis a string,valueis an image,leftis aimage-bstin which allkeys are less than this key, andrightis aimage-bstin which allkeys are greater than this key.
In both data definitions, “less” and ’greater" are determined by string<?; they basically amount to alphabetical order. If you want to understand the details, you can experiment with DrRacket’s Interactions window.
This problem has three parts:
Generalizing from the two example definitions above, write a parametric data definition for binary-search trees that can be used to store any given class of value.
The “search” in a binary-search tree comes from a function that is given a binary-search tree and a string key. The function searches for a node containing that key, and if it finds such a node, it returns the node’s
value. If it does not find the node, it returnsfalse.Using your parametric data definition from the previous problem, write the signature, purpose statement, and header for a function that searches binary-search trees. The signature must have one or more type variables.
Using the design recipe for self-referential data, finish the design of the function for searching in a binary-search tree (from the previous problem). Make sure that your test cases use the function with different types of values.
This problem is similar to the search on the apocalyptic railway, but it is significantly easier.
Here are two parametric data definitions:
A
(2Dpoint X)is a structure
(make-point x y value)where
xandyare numbers andvalueis an X.A
(2Dtree X)is one of the following:
A
(2Dpoint X)A structure
(make-v-boundary left x right),where
xis a number,leftis a(2Dtree X)in which every point has an x coordinate at mostx, andrightis a(2Dtree X)in which every point has an x coordinate at leastxA structure
(make-h-boundary above y below),where
yis a number,aboveis a(2Dtree X)in which every point has an y coordinate at mosty, andbelowis a(2Dtree X)in which every point has an y coordinate at leasty
Here is an image derived from a data example made using make-v-boundary: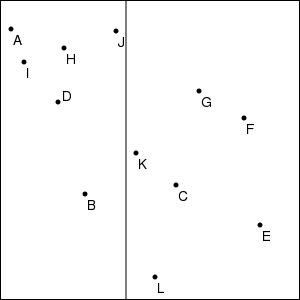
And here is an image derived from a data example made using make-h-boundary:
This problem has two parts:
Based on the simple maps used for the templates homework, write data examples for
(2Dtree string). A list of towns appears at the end of the problem, but you need not include every town.Define a function
nearest-pointwhich is given the (x, y) coordinates of a “target” and is also given a(2Dtree X). The function returns the(2Dpoint X)within the tree that is closest (in ordinary Euclidean distance) to the target.Your function must avoid searching on the far side of a boundary unless such a search is necessary. To figure out when a far-side search is necessary, use the table you made for the templates homework (or my solution).
The second part of this problem presents a major design challenge. To help you meet this challenge, here are some observations about templates, conditionals, helper functions, and testing:
If you don’t know your templates, or if you are not scrupulous about following the design recipe, you will die of frustration. Know your templates.
Treat conditionals like gold: spend as few of them as possible.
The function
nearest-pointconsumes only one piece of complex data, which is defined by choices. There are three choices, so you can expect a conditional with three cases.When you’re dealing with a boundary, one subtree has coordinates that are smaller than the location of the boundary, and the other side has coordinates that are at least as large as the location of the boundary. But because you’re searching for the point nearest the target (x, y), there’s a more important distinction.
The subtree on the same side as the target is called the near subtree.
The subtree on the opposite side as the target is called the far subtree.
To tell which subtree is “near” and which is “far”, you will need another conditional.
“Near” and “far” are good words to use to form names used in
localdefinitions.In your main function, do not nest conditionals deeper than two, or nobody will understand it. If you need other conditionals (and you will), put them in helper functions.
The presence of so many conditionals means you will have to craft your test cases carefully, and you will need more test cases than usual. Make sure that when you press the Run button, that there is no untested code.2
Use
localdefinitions for both values and functions. For example, the near and far subtrees are potential candidates forlocaldefinitions.You always have to search for the nearest point in the near subtree. Use the appropriate natural recursion.
As you know from the templates homework, you may or may not have to search across the boundary in the far subtree. The key to efficiency is to search the far subtree only when necessary. The job of “searching only when necessary” is best given to a helper function. At minimum, this helper function needs to know
- What is the far subtree?
- What is the closest point in the near subtree?
- How far away is the boundary?
This function also needs to know the (x, y) coordinates of the target point. If you make this function a
localfunction, it can access these coordinates directly. Or you can choose to make it a top-level function, in which case you can test it withcheck-expect. Both tactics have their advantages.If you do have to search the far subtree, your final answer comes down to choosing whichever of two points is closer to the target (x, y) coordinates. For this job, I recommend designing yet another helper function.
The formula for Euclidean distance is annoying to write and even more annoying to read. I recommend that you arrange for it to occur in your code only once. If you need to design a helper function that calculates Euclidean distance, it’s OK.
To help you create data examples and test cases, here is a list of all the towns from the maps used in the templates homework:
(list
(make-point 11 29 "A")
(make-point 85 194 "B")
(make-point 176 185 "C")
(make-point 58 102 "D")
(make-point 260 225 "E")
(make-point 244 118 "F")
(make-point 199 91 "G")
(make-point 64 48 "H")
(make-point 24 62 "I")
(make-point 116 31 "J")
(make-point 136 153 "K")
(make-point 155 277 "L"))Once you have a good template, I don’t expect the code itself to give you much trouble, but if at any point you get stuck, here are some useful questions. You should base your answers on the results for the map examples on the templates homework.
- Which side of the boundary is the near side?
- How do you know?
- Which side of the boundary do you have to search first?
- How do you code that search?
- Do you have to search the far side of the boundary?
- How do you know?
- If you have to search the far side of the boundary, how do you code that search?
- What searches do the natural recursions correspond to?
- If you only have to search the near side of the boundary, then what is the closest point?
- If you have to search both sides of the boundary, then how do you determine the closest point?