 Image tufts1.jpg
Image tufts1.jpg
| 
|
| 
|
The primary purpose of this assignment is to give you practice unpacking and repacking representations that put multiple integers (both signed and unsigned) into a word. You'll also learn to analyze two's-complement arithmetic so that you know how many bits are needed to store the results of calculations, and when not enough bits are available, you'll know how to adapt your code. You'll be exposed to some of the horrors of floating-point arithmetic. Finally, you'll get a post-midterm challenge problem that will test the modularity of your code.
As a minor side benefit, you'll also learn a little bit about how broadcast color TV works as well as the basic principle behind JPEG image compression.
Here's what you'll do:
git clone /comp/40/git/arithto get files you will need for the assignment.
In COMP 40, you practice solving problems by writing programs. You'll find problem-solving more difficult (and more satisfying) than simply writing a program someone has told you to write. To solve the problem of image compression, we recommend a technique called stepwise refinement.
When using stepwise refinement, one analyzes a problem by breaking the problem into parts, which in turn can be broken into subparts, and so on, until the individual sub-sub-parts are either already to be found in a library or are so easy as to be quickly solvable by simple code. Each individual subpart is solved by a function or by a collection of functions in a module. Each solution is written as another function, and so on, all the way up to the main function, which solves the whole problem. In other words, the solution to the main problem is composed of solutions to the individual parts. To design software systems successfully, you must master the techniques of analysis and composition.
Keep in mind these units of composition:
All files we provide will be in /comp/40/include or /comp/40/lib64, or else you will acquire them using git. The files include
main function that can handle the command line for you.
You can acquire it by
git clone /comp/40/git/arith.
Your design document, to be submitted using
submit40-arith-design,
should describe your overall design, and it should also include
separate descriptions of each component.
Your sections on the Bitpack module and on parts of the
40image program can be relatively short, since in these cases
I have done some of the design work for you.
But you should have a detailed plan for testing each of these components.
Also, your 40image program should not be
implemented as a single component. Your design document should
not only explain how 40image is to be implemented by a
combination of components, but should also present a separate design
description of each component.
The following elements of your design document will be critical:
Your implementation, to be submitted using submit40-arith, should include
Bitpack interface.
[*]
Your goal is to convert between full-color portable pixmap images
and compressed binary image files.
Write a program 40image which takes the option -c (for
compress) or -d (for decompress) and also the name of the file to
compress or decompress.
The name of the file may be omitted, in which case you should compress
or decompress standard input.
If you're given something else on the command line, print the
following:
Usage: 40image -d [filename]
40image -c [filename]
A compressed image should be about three times smaller than the
same image in PPM format.
If not, you are doing something wrong.
I have designed a compressed-image format and a compression algorithm. The algorithm, which is inspired by JPEG, works on 2-by-2 blocks of pixels. Details appear below, but here is a sketch of the compression algorithm:
unsigned Arith40_index_of_chroma(float x);This function takes a chroma value between -0.5 and +0.5 and returns a 4-bit quantized representation of the chroma value.
The index operation is implemented by
Value Type Width LSB a Unsigned scaled integer 9 bits 23 b Signed scaled integer 5 bits 18 c Signed scaled integer 5 bits 13 d Signed scaled integer 5 bits 8 index(\avgP_B) Unsigned index 4 bits 4 index(\avgP_R) Unsigned index 4 bits 0
Arith40_index_of_chroma; it quantizes the chroma value and
returns the index of the quantized value in an internal table.
Bitpack interface you will
develop in Part B on page [->].
printf("COMP40 Compressed image format 2\n%u %u", width, height);
This header should be followed by a newline and then a sequence of
32-bit code words,
one for each 2-by-2
block of pixels.
The width and height variables describe the dimensions of the
original (decompressed) image, after trimming off any odd
column or row.
Your decompressor will be the inverse of your compressor:
fscanf with exactly the same string used to
write the header:
<sketch of header reading code>= unsigned height, width; int read = fscanf(in, "COMP40 Compressed image format 2\n%u %u", &width, &height); assert(read == 2); int c = getc(in); assert(c == '\n');
size parameter should be the size of a colored pixel.
Place the array, width, height, and the denominator of your choice in a local
variable as follows:
struct Pnm_ppm pixmap = { .width = width, .height = height
, .denominator = denominator, .pixels = array
};
The PNM format allows some choice of denominator, but it should meet
some constraints:
float Arith40_chroma_of_index(unsigned n);
pixmap->pixels.
(Because repeated quantization can introduce significant errors into
your computations, getting the RGB values into the right range is not
as easy as it looks.)
Pnm_ppmwrite(stdout, pixmap).
My compressor and decompressor total under 320 lines of new code, including many assertions and some testing code. (This total does not include the implementation of the chroma quantization in the arith40 library.) I created five new modules (including chroma quantization) and reused a number of existing modules.
The CIE XYZ color space was created by the International Committee on Illumination in 1931. The committee is usually referred to as the CIE, which as an acronym for the French Commission Internationale de l'Éclairage. It is the international authority on standards for representation of light and color.
The XYZ system uses three so-called tristimulus values which are matched to the visual response of the three kinds of cone cells found in the human retina. [By contrast, the RGB system is matched to the red, green, and blue phosphors found on cathode-ray tube (CRT) computer screens. Despite the fact CRTs have largely been replaced by liquid-crystal displays, which have different color-response characteristics, computing standards remain wedded to the RGB format originally created for CRTs.] The Y value represents the brightness of a color; the X and Z values represent ``chromaticity.'' Early black-and-white television transmitted only Y, or brightness. When color was added, analog engineers needed to make the color signal backward compatible with black-and-white TV sets. They came up with a brilliant hack: first, they made room for a little extra signal by reducing the refresh rate (number of frames per second) from 60Hz to 59.97Hz, and then they transmitted not the chromaticity, but the differences between the blue and red signals and the brightness. The black-and-white sets could ignore the color-difference signals, and everybody could watch TV.
The transformation is useful for compression because the human eye is more sensitive to brightness than to chromaticity, so we can use fewer bits to represent chromaticity.
There are multiple standards for both RGB and luminance/chromaticity representations. We will use component-video representation for gamma-corrected signals; this signal is a luminance Y together with two side channels P_B and P_R which transmit color-difference signals. P_B is proportional to B-Y and P_R is proportional to R-Y. In each case, the constant of proportionality is chosen so that both P_B and P_R range from -0.5 to +0.5. The luminance Y is a real number between 0 and 1.
Given the RGB representation used by the portable pixmap (PPM) library, we can convert to component video by the following linear transformation:
\cvectorY P_B P_R = \cmatrix 0.299 0.587 0.114 -0.168736 -0.331264 0.5 0.5 -0.418688 -0.081312 \cvectorR G B.If your matrix arithmetic is rusty, the equation above is equivalent to
y = 0.299 * r + 0.587 * g + 0.114 * b; pb = -0.168736 * r - 0.331264 * g + 0.5 * b; pr = 0.5 * r - 0.418688 * g - 0.081312 * b;The inverse computation, to convert from component video back to RGB, is
r = 1.0 * y + 0.0 * pb + 1.402 * pr; g = 1.0 * y - 0.344136 * pb - 0.714136 * pr; b = 1.0 * y + 1.772 * pb + 0.0 * pr;
Suppose we have a 2-by-2 block of pixels with brightnesses Y_1 through Y_4. From the point of view of linear algebra, these Y_i values form a vector, but to exploit our geometric intuition about 2-by-2 blocks, I write them as a matrix:
\bmatrixY_1 Y_2 Y_3 Y_4.It is easy to see that we can compute this matrix as the sum of four standard matrices, each of which is multiplied by the brightness of a single pixel:
\bmatrixY_1 Y_2 Y_3 Y_4 = Y_1 *\bmatrix1 0 0 0 + Y_2 *\bmatrix0 1 0 0 + Y_3 *\bmatrix0 0 1 0 + Y_4 *\bmatrix0 0 0 1.This representation does not take advantage of the way the human eye works; the eye is better at seeing gradual shadings of color than at seeing fine spatial detail. We can therefore write the same pixels using a different orthogonal basis: [The words ``orthogonal basis'' will mean something to you only if you have studied linear algebra.] The basis comes from taking cosines at discrete points; in fact, the four new matrices we use come from computing cos0, cospiy, cospix, and (cospix)(cospiy). The values used for x and y are the coordinates of the four pixels, so x and y take on only the integer values 0 and 1, and the equation is
\bmatrixY_1 Y_2 Y_3 Y_4 = a *\bmatrix1 1 1 1 + b *\bmatrix-1 -1 1 1 + c *\bmatrix-1 1 -1 1 + d *\bmatrix1 -1 -1 1.This is the famous discrete cosine transform (DCT), so called because we compute cosines at discrete points.
When we consider the four-pixel array as an image, not just numbers, we can see that the new basis derived from cosine functions actually tells us something interesting about the image:
Here are the equations giving the transformation to and from cosine space. To transform from cosine space into pixels, we just read off the sum from the previous page; to get from cosine space back to pixel space, we perform the inverse transformation:
Since Y_i is always in the range 0 to 1, we can see that a is also in the range 0 to 1, but b, c, and d lie in the range -frac12 to frac12. Thus, you can code a in nine unsigned bits if you multiply by 511 and round.
Y_1 = a - b - c + d Y_2 = a - b + c - d Y_3 = a + b - c - d Y_4 = a + b + c + d
a = (Y_4+Y_3+Y_2+Y_1)/4.0 b = (Y_4+Y_3-Y_2-Y_1)/4.0 c = (Y_4-Y_3+Y_2-Y_1)/4.0 d = (Y_4-Y_3-Y_2+Y_1)/4.0
For coding b, c, and d, your objective is to code the floating-point interval [-0.3, +0.3] into the signed-integer set {-15, -14, ..., -1, 0, 1, 2, ..., 15 }. As noted above, any coefficient outside that interval should be coded as +15 or -15, depending on sign. There is more than one good way to do the calculation.
The process of converting from an arbitrary floating-point number to one of a small set of integers is known as quantization. In reducing average chroma to just 4 bits, we quantize in the extreme. The quantization works by considering the floating-point chroma value and finding the closest value in the set
{±0.35, ±0.20, ±0.15, ±0.10, ±0.077, ±0.055, ±0.033, ±0.011 }.As seen below, most chroma values are small, so I chose this set to be more densely populated in the range ±0.10 than near the extrema of ±0.50. By putting more information near zero, where most values are, this nonlinear quantization usually gives smaller quantization errors [The quantization error is the difference between P_B and
chroma_of_index(index_of_chroma(P_B)).]
than the
linear quantization n = floor(15 * (P_B + 0.5)).
But for those rare images that use saturated colors, when P_B or P_R is large,
quantization errors will be larger than with a linear quantization.
The net result is that when colors are
more saturated, compression artifacts will be more visible.
You probably won't notice artifacts if you compress an ordinary
photograph, especially if it has already been compressed with JPEG.
But if you try compressing and then decompressing a color-bar test
pattern, you should notice artifacts.
Quantization is implemented by sorting the values above into a 16-element array. To quantize a floating-point chroma value, I find the element of the array that most closely approximates the chroma, and I return that element's index.
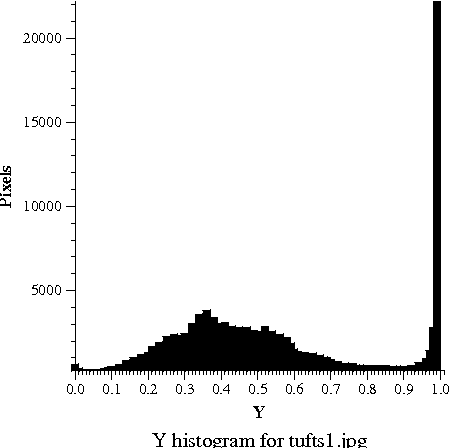
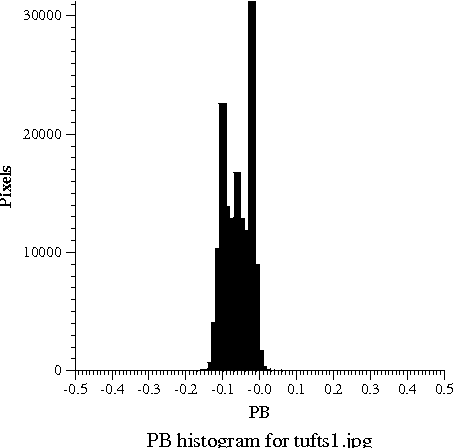
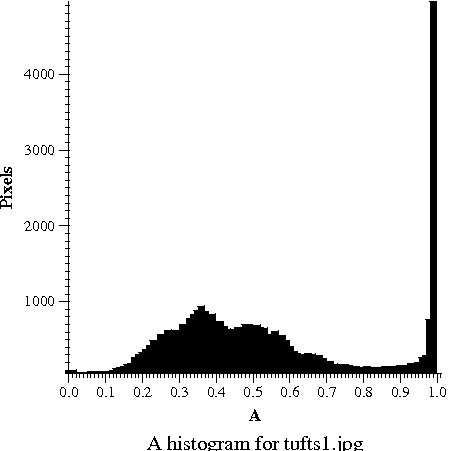
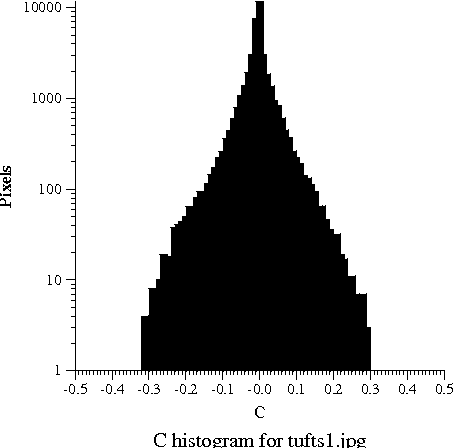
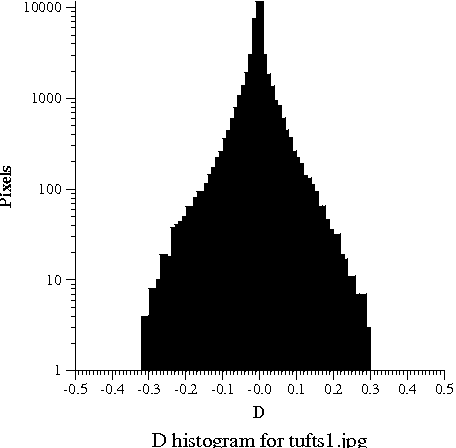
Here you can see a picture and three histograms, which tell how often each value of Y, P_B, and P_R occurs in the picture. The hump in Y values around 0.3 to 0.5 shows that the picture is somewhat dark; the big spike near 1.0 is the bright overcast sky in the background. The tremendous range in the available Y values shows that Y carries lots of information, so we are justified in using lots of bits (24 out of 32) to code it. As is typical, the chroma signals are mostly near zero; the blue chroma P_B is somewhat negative because of the lack of blue tones in the photograph; the red chroma P_R is somewhat positive, probably because of the red bricks. The narrow range of the actual chroma values shows that color differences carry little information, so we are justified in using only 8 of 32 bits for color.
|
Image tufts1.jpg
|
|
|
|
|
Here's a diagram that shows the results of the discrete cosine transform on Y:
| 
|
| 
|
[*] When programming at the machine level, it is common to pack multiple small values (sometimes called ``fields'') into a single byte or word. The binary representation of machine instructions uses such packings heavily, and the instruction-decode unit unpacks a sequence of bytes into fields that determine opcodes and operands. [You are not yet expected to know what an ``opcode'' or ``operand'' is.] You will implement functions to perform these kinds of computations. It will take you longer to understand the specification than to write the code.
The best way to describe a field is to give its width and the location of the least significant bit within the larger byte or word. For example, if a machine has a 2-way set-associative 128KB Level 1 cache with 64-byte cache lines, then 6 bits are required to address a byte within a line, and the line offset is a field 6 bits wide with its least significant bit at bit 0. There are 128K ÷64 = 1024 = 2^10 sets, so the set number is a field 10 bits wide with its least significant bit at bit 6. Because bits 48–63 are canonical, the caching tag is 32 bits wide with its least significant bit at bit 16. All these fields are interpreted as unsigned integers.

When packing fields, you also have to deal with the question of whether an integer fits into a given number of bits. For example, the integer 17 cannot be represented in a 3-bit field. [A 3-bit field can be interpreted as signed or unsigned. When signed, it can represent integers in the range -4 to 3; when unsigned, it can represent integers in the range 0 to 7.]
In this part of the assignment you will define bit-manipulation
primitives as part of the Bitpack interface.
<bitpack.h>= #ifndef BITPACK_INCLUDED #define BITPACK_INCLUDED #include <stdbool.h> #include <stdint.h> #include "except.h" <exported macros, functions, and values> #endif
You are to implement this interface in file bitpack.c.
<exported macros, functions, and values>= (<-U) [D->] bool Bitpack_fitsu(uint64_t n, unsigned width); bool Bitpack_fitss( int64_t n, unsigned width);
The functions tell whether the argument n can be represented in
width bits. For example, 3 bits can represent unsigned integers
in the range 0 to 7, so Bitpack_fitsu(5, 3) == true.
But 3 bits can represent signed integers
only in the range -4 to 3, so Bitpack_fitss(5, 3) == false.
<exported macros, functions, and values>+= (<-U) [<-D->] uint64_t Bitpack_getu(uint64_t word, unsigned width, unsigned lsb); int64_t Bitpack_gets(uint64_t word, unsigned width, unsigned lsb);
Each function extracts a field from a word given the width of the field and the location of the field's least significant bit. For example,
Bitpack_getu(0x3f4, 6, 2) == 61 Bitpack_gets(0x3f4, 6, 2) == -3To get the cache set number from a 64-bit address, you might use
Bitpack_getu(address, 10, 6).
It should be a checked run-time error to call Bitpack_getu
or Bitpack_gets with a width w that does not satisfy
0 <=w <=64.
Similarly,
it should be a checked run-time error to call Bitpack_getu
or Bitpack_gets with a width w and lsb that do not satisfy
w + lsb <=64.
Some machine designs, such as the late, unlamented HP PA-RISC, provided these operations using one machine instruction apiece.
<exported macros, functions, and values>+= (<-U) [<-D->] uint64_t Bitpack_newu(uint64_t word, unsigned width, unsigned lsb, uint64_t value); uint64_t Bitpack_news(uint64_t word, unsigned width, unsigned lsb, int64_t value);
Each of these functions should return a new word which is identical
to the original word, except that the field of width width with least
significant bit at lsb will have been replaced by a width-bit
representation of value.
It should be a checked run-time error to call Bitpack_newu
or Bitpack_news with a width w that does not satisfy
0 <=w <=64.
Similarly,
it should be a checked run-time error to call Bitpack_newu
or Bitpack_news with a width w and lsb that do not satisfy
w + lsb <=64.
If Bitpack_news is given a value that does not fit in
width signed bits, it must raise the exception
Bitpack_Overflow (using Hanson's RAISE macro from his
Except interface).
Similarly, if Bitpack_newu is given a value that does not fit in
width unsigned bits, it must also raise the exception.
<exported macros, functions, and values>+= (<-U) [<-D] extern Except_T Bitpack_Overflow;
You'll implement this exception as follows:
<code to be used in file bitpack.c>=
#include "except.h"
Except_T Bitpack_Overflow = { "Overflow packing bits" };
If no exception is raised
and no checked run-time error occurs, then Bitpack_getu and Bitpack_newu
satisfy the mathematical laws you would expect, for example,
Bitpack_getu(Bitpack_newu(word, w, lsb, val), w, lsb) == valA more subtle law is that if
lsb2 >= w + lsb, then
getu(newu(word, w, lsb, val), w2, lsb2) == getu(word, w2, lsb2)where in order to fit the law on one line, I've left off
Bitpack_
in the names of the functions.
Similar laws apply to the signed get and new functions.
Such laws make an excellent basis for unit testing. [``Unit testing'' means testing a solution to a subproblem before
testing the solution to the whole problem.]
You can also unit-test the fits functions by using the
TRY construct in Hanson's exceptions chapter to ensure that the
new functions correctly raise an exception on being presented with
a value that is too large.
I'm aware of three design alternatives for the Bitpack module:
Not counting the code shown here, my solution to this problem is about 90 lines of C, plus another 80 lines for testing.
[*] After the midterm, I will announce a new format for the codeword in your image compressor. You will have one day to change your code to support the new format. You will be evaluated on the magnitude and scope of your changes (earlier bullets are more important):
(I am posing this problem is not for its own sake, but to provoke you into thinking more deeply about your design. By thinking deeply, you are more likely to build a working compressor.)
Computations involving arithmetic are the most difficult to get right; a trivial typo can lead to a program that silently produces wrong answers, and finding it can be nearly impossible. The only helpful strategy is aggressive unit testing.
0, 1, 0l, 1l, 1ul, and so on are not
guaranteed to be 64 bits.
I recommend two safe ways make sure you are using all 64 bits when
shifting, complementing, and doing other bitwise operations:
(uint64_t) or (int64_t)
uint64_t or int64_t
Bitpack
interface by using a loop that does one iteration per bit. Don't!
The Bitpack operations need to be implementable in one or two dozen
instructions apiece. This is true not only to meet performance goals
for code that we will rely on heavily, but to meet learning goals that
you understand how to compute with shift, bitwise complement, and the
other Boolean operations on bit vectors.
Once n is large enough, doing arithmetic
with pow(2, n) will lead to serious error.
You can see what goes wrong if you pass pow(2, n) to this function,
experimenting with different values of n:
/* Show x bracketed by x - 1 and x + 1.
The name comes from photographers' practice of 'bracketing'
apertures for exposure */
void bracket(const char *what, double x) {
double plus = x + 1.0;
double minus = x - 1.0;
printf("%s = %.1f + 1 = %.1f\n", what, x, plus);
printf("%s = %.1f = %.1f\n", what, x, x);
printf("%s = %.1f - 1 = %.1f\n", what, x, minus);
}
Although you could possibly get away with computing pow(2, n) and
then immediately converting to an integer, this idiom would be very
confusing to any experienced C programmer you might work with; a
C programmer expects you to compute 2^n
using the expression ((uint64_t)1 << n),
unless of course n is greater than or equal to the word size,
in which case the number can't be represented anyway. [Not to mention
that by pinging back and forth between the integer unit and the
floating-point unit, you make it more difficult for the hardware to
schedule the computations and exploit instruction-level paralellism.
]
static inline function to force each value into the
interval where it belongs.
Here are some ideas to keep in mind when you approach the Bitpack module:
2 << 60 does not do
what you would hope (its value is not 2^60).
What C do I have to utter to get the hardware effect that I want?You can use this same point of truth to define a shift operation that is better than the hardware—one that does something sensible when asked to shift left or right by a full 64 bits.
A good way to draw pictures is to write abcde and so on for fields
that you care about, and xxxxxx or yyyyyy for fields that you
don't care about. Left and right shifts can move or eliminate
fields, and if you have different words that contain fields in
different positions, with zeroes elsewhere, you can compose them
into a single word using bitwise or (single |).
In addition to avoiding the traps and pitfalls and defining your own shift operations, you might benefit from the following advice:
Bitpack last.
frac(x-y)^2 x^2 + y^2is small. However, this test can fail as well if x and y are both zero. In that case they are definitely approximately equal, but you have to check for it.
Plan to spend most of your time on this assignment creating and running unit tests. Once your unit tests all run, doing whole pictures should be pretty easy—the most likely mistakes are things like confusing width and height, and these can be observed pretty easily.
We will run unit tests against your code. A significant fraction of your grade for functionality will be based on the results of those unit tests.
The following problems are available for extra credit. Some are programming problems and some are math problems.
40imagex, which uses 5-bit nonlinear coding
for b, c, and d instead of a 5-bit linear coding.
Be sure to change the header to image format 3.
40image on a difficult image.
Hint: draw a line through the origin perpendicular to the direction of the gradient, drop a perpendicular bisector from the pixel to the origin, use polar coordinates, and remember your trigonometry.
For dealing with command-line options, consider such code as the following:
#include <string.h>
#include <stdlib.h>
#include <stdio.h>
#include "assert.h"
#include "compress40.h"
static void (*compress_or_decompress)(FILE *input) = compress40;
int main(int argc, char *argv[]) {
int i;
for (i = 1; i < argc; i++) {
if (!strcmp(argv[i], "-c")) {
compress_or_decompress = compress40;
} else if (!strcmp(argv[i], "-d")) {
compress_or_decompress = decompress40;
} else if (*argv[i] == '-') {
fprintf(stderr, "%s: unknown option '%s'\n", argv[0], argv[i]);
exit(1);
} else if (argc - i > 2) {
fprintf(stderr, "Usage: %s -d [filename]\n"
" %s -c [filename]\n", argv[0], argv[0]);
exit(1);
} else {
break;
}
}
assert(argc - i <= 1); // at most one file on command line
if (i < argc) {
FILE* fp = fopen(argv[i], "r");
assert(fp);
compress_or_decompress(fp);
fclose(fp);
} else {
compress_or_decompress(stdin);
}
}
You can get this function using
git clone /comp/40/git/arith.
The mistakes people typically make on this assigment are covered above. To enumerate all the common mistakes would be to repeat much of the handout. Here are a half dozen carefully chosen ones:
Bitpack without using all 64 bits